Structure
Hudi (pronounced “Hoodie”) ingests & manages storage of large analytical tables over DFS (HDFS or cloud stores) and provides three types of queries.
- Read Optimized query - Provides excellent query performance on pure columnar storage, much like plain Parquet tables.
- Incremental query - Provides a change stream out of the dataset to feed downstream jobs/ETLs.
- Snapshot query - Provides queries on real-time data, using a combination of columnar & row based storage (e.g Parquet + Avro)
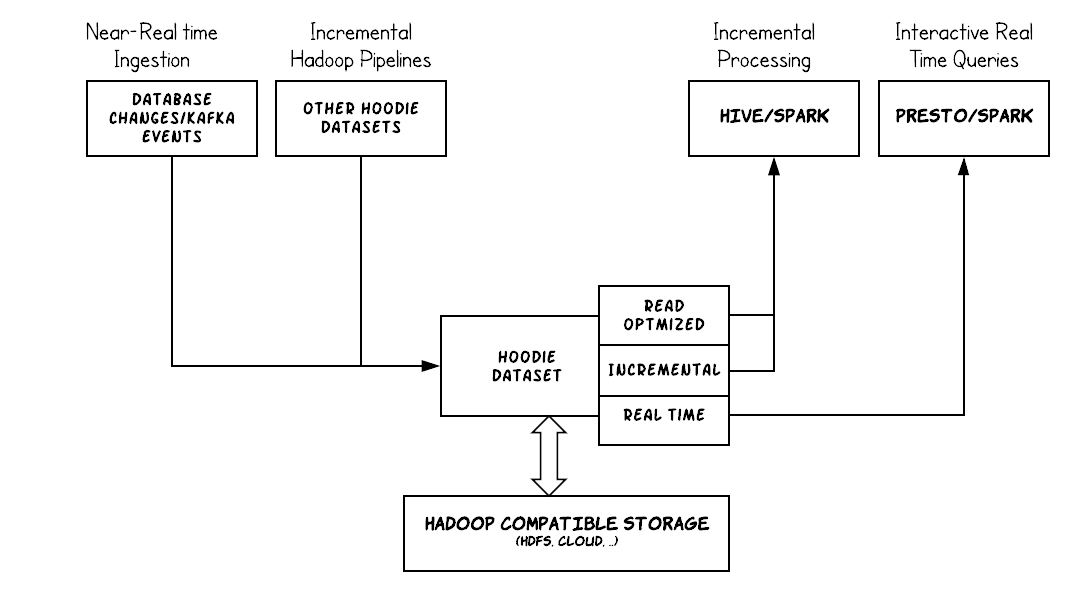
By carefully managing how data is laid out in storage & how it’s exposed to queries, Hudi is able to power a rich data ecosystem where external sources can be ingested in near real-time and made available for interactive SQL Engines like PrestoDB & Spark, while at the same time capable of being consumed incrementally from processing/ETL frameworks like Hive & Spark to build derived (Hudi) tables.
Hudi broadly consists of a self contained Spark library to build tables and integrations with existing query engines for data access. See quickstart for a demo.