Lakehouse Concurrency Control: Are we too optimistic?

Transactions on data lakes are now considered a key characteristic of a Lakehouse these days. But what has actually been accomplished so far? What are the current approaches? How do they fare in real-world scenarios? These questions are the focus of this blog.
Having had the good fortune of working on diverse database projects - an RDBMS (Oracle), a NoSQL key-value store (Voldemort), a streaming database (ksqlDB), a closed-source real-time datastore and of course, Apache Hudi, I can safely say that the nature of workloads deeply influence the concurrency control mechanisms adopted in different databases. This blog will also describe how we rethought concurrency control for the data lake in Apache Hudi.
First, let's set the record straight. RDBMS databases offer the richest set of transactional capabilities and the widest array of concurrency control mechanisms. Different isolation levels, fine grained locking, deadlock detection/avoidance, and more are possible because they have to support row-level mutations and reads across many tables while enforcing key constraints and maintaining indexes. NoSQL stores offer dramatically weaker guarantees like eventual-consistency and simple row level atomicity in exchange for greater scalability for simpler workloads. Drawing a similar parallel, traditional data warehouses offer more or less the full set of capabilities that you would find in an RDBMS, over columnar data, with locking and key constraints enforced whereas cloud data warehouses seem to have focused a lot more on separating the data and compute in architecture, while offering fewer isolation levels. As a surprising example, no enforcement of key constraints!
Pitfalls in Lake Concurrency Control
Historically, data lakes have been viewed as batch jobs reading/writing files on cloud storage and it's interesting to see how most new work extends this view and implements glorified file version control using some form of "Optimistic concurrency control" (OCC). With OCC jobs take a table level lock to check if they have impacted overlapping files and if a conflict exists, they abort their operations completely. Without naming names, the lock is sometimes even just a JVM level lock held on a single Apache Spark driver node. Once again, this may be okay for lightweight coordination of old school batch jobs that mostly append files to tables, but cannot be applied broadly to modern data lake workloads. Such approaches are built with immutable/append-only data models in mind, which are inadequate for incremental data processing or keyed updates/deletes. OCC is very optimistic that real contention never happens. Developer evangelism comparing OCC to the full fledged transactional capabilities of an RDBMS or a traditional data warehouse is rather misinformed. Quoting Wikipedia directly - "if contention for data resources is frequent, the cost of repeatedly restarting transactions hurts performance significantly, in which case other concurrency control methods may be better suited. " When conflicts do occur, they can cause massive resource wastage since you have a batch job that fails after it ran for a few hours, during every attempt!
Imagine a real-life scenario of two writer processes : an ingest writer job producing new data every 30 minutes and a deletion writer job that is enforcing GDPR, taking 2 hours to issue deletes. It's very likely for these to overlap files with random deletes, and the deletion job is almost guaranteed to starve and fail to commit each time. In database speak, mixing long running transactions with optimism leads to disappointment, since the longer the transactions the higher the probability they will overlap.

So, what's the alternative? Locking? Wikipedia also says - "However, locking-based ("pessimistic") methods also can deliver poor performance because locking can drastically limit effective concurrency even when deadlocks are avoided.". Here is where Hudi takes a different approach, that we believe is more apt for modern lake transactions which are typically long-running and even continuous. Data lake workloads share more characteristics with high throughput stream processing jobs, than they do to standard reads/writes from a database and this is where we borrow from. In stream processing events are serialized into a single ordered log, avoiding any locks/concurrency bottlenecks and you can continuously process millions of events/sec. Hudi implements a file level, log based concurrency control protocol on the Hudi timeline, which in-turn relies on bare minimum atomic puts to cloud storage. By building on an event log as the central piece for inter process coordination, Hudi is able to offer a few flexible deployment models that offer greater concurrency over pure OCC approaches that just track table snapshots.
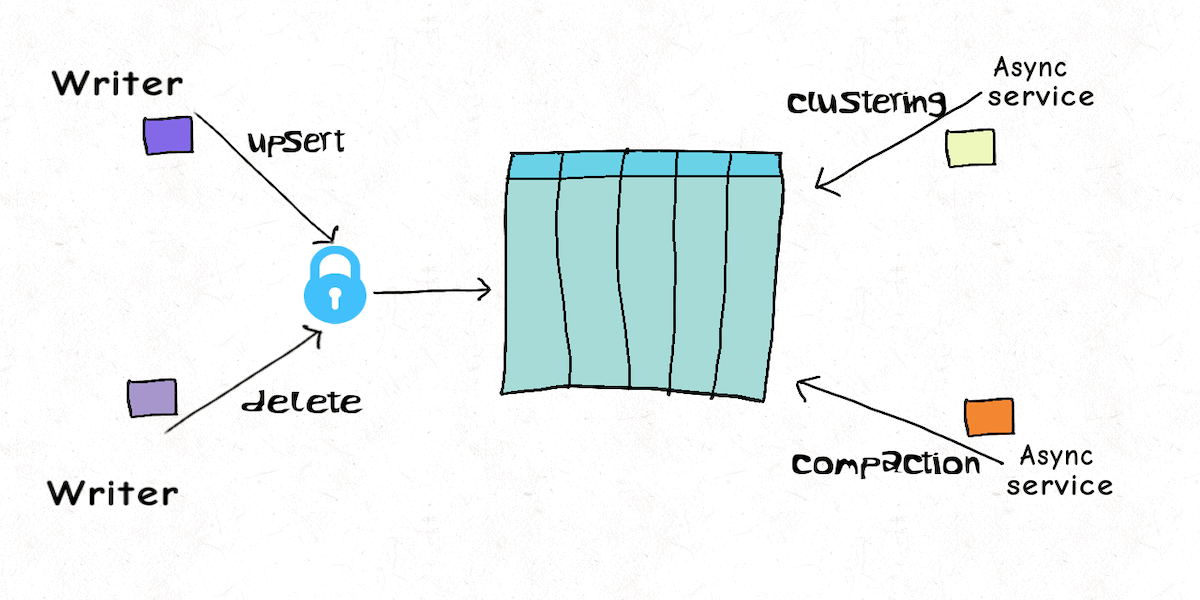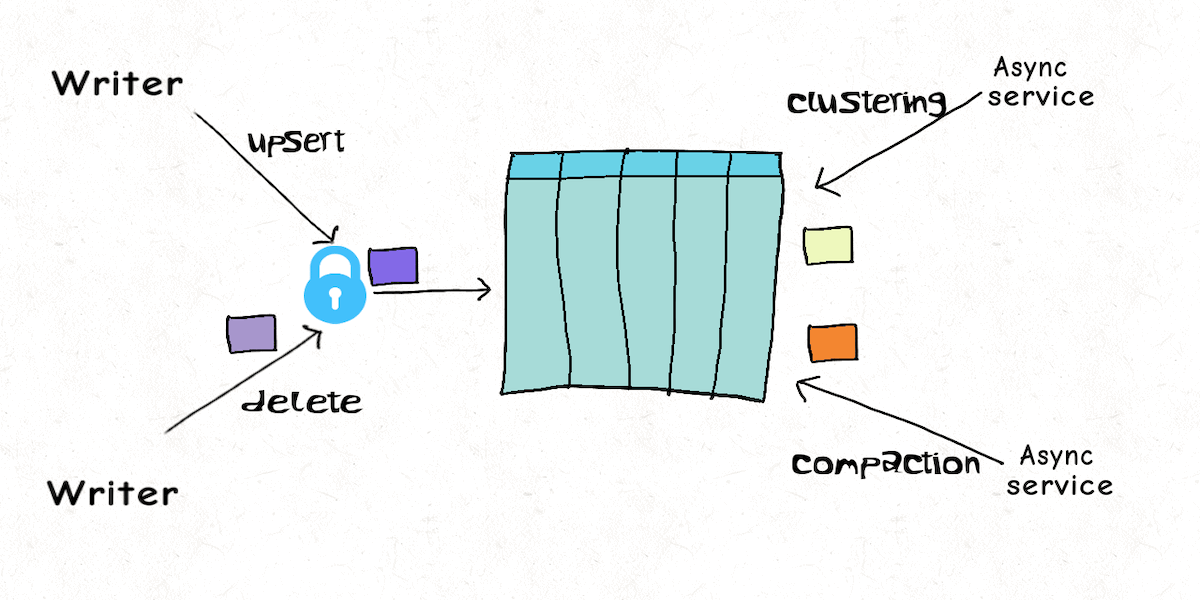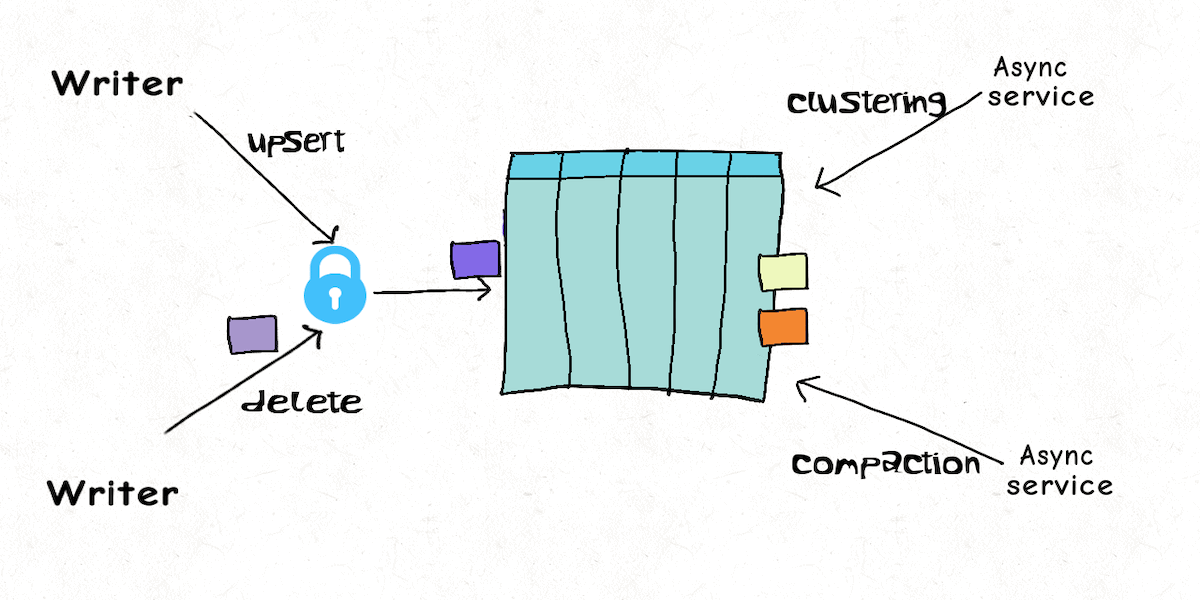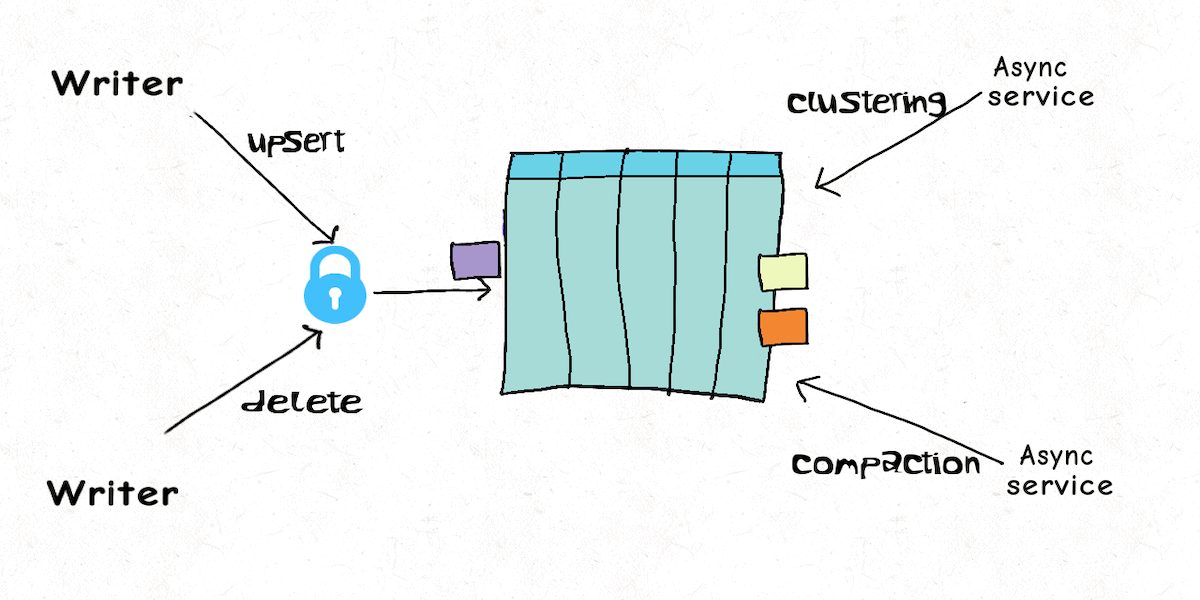
Model 1 : Single Writer, Inline Table Services
The simplest form of concurrency control is just no concurrency at all. A data lake table often has common services operating on it to ensure efficiency. Reclaiming storage space from older versions and logs, coalescing files (clustering in Hudi), merging deltas (compactions in Hudi), and more. Hudi can simply eliminate the need for concurrency control and maximizes throughput by supporting these table services out-of-box and running inline after every write to the table.
Execution plans are idempotent, persisted to the timeline and auto-recover from failures. For most simple use-cases, this means just writing is sufficient to get a well-managed table that needs no concurrency control.
Model 2 : Single Writer, Async Table Services
Our delete/ingest example above is n't really that simple. While ingest/writer may just be updating the last N partitions on the table, delete may span across the entire table even. Mixing them in the same job, could slow down ingest latency by a lot. But, Hudi provides the option of running the table services in an async fashion, where most of the heavy lifting (e.g actually rewriting the columnar data by compaction service) is done asynchronously, eliminating any repeated wasteful retries whatsoever, while also optimizing the table using clustering techniques. Thus a single writer could consumes both regular updates and GDPR deletes and serialize them into a log. Given Hudi has record level indexing and avro log writes are much cheaper (as opposed to writing parquet, which can be 10x or more expensive), ingest latency can be sustained while enjoying great replayability. In fact, we were able to scale this model at Uber, across 100s of petabytes, by sequencing all deletes & updates into the same source Apache Kafka topic. There's more to concurrency control than locking and Hudi accomplishes all this without needing any external locking.
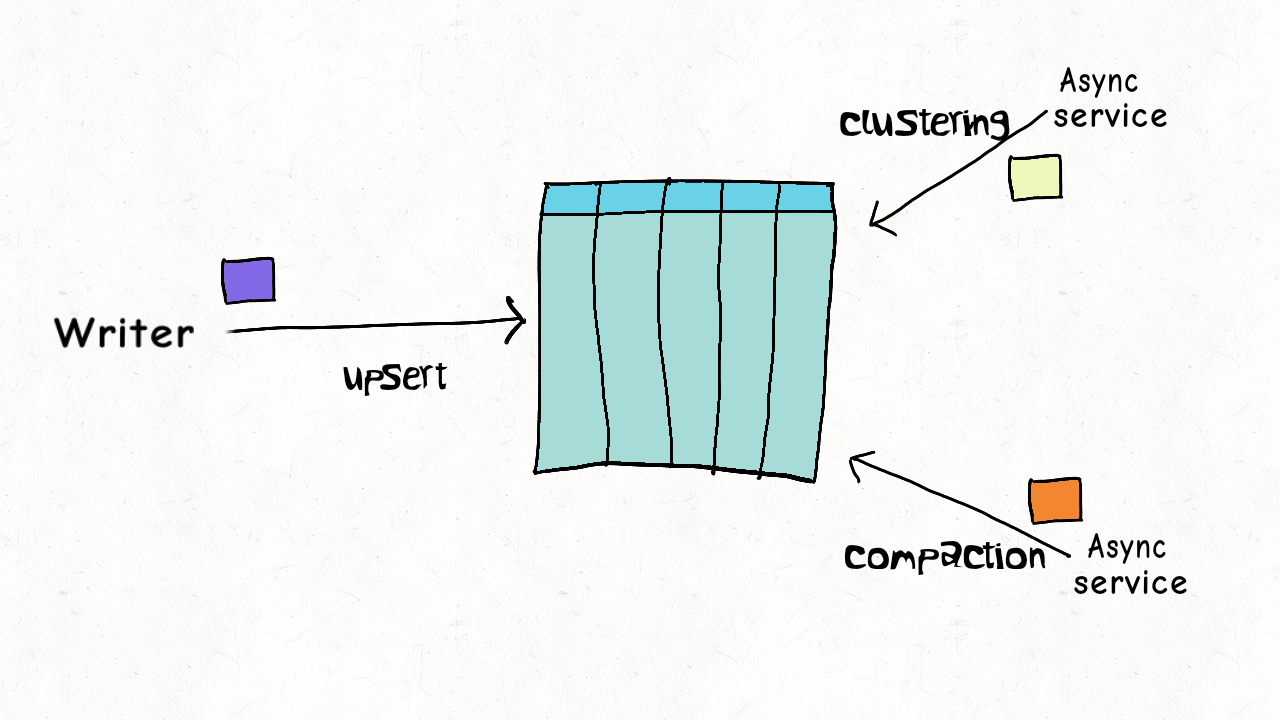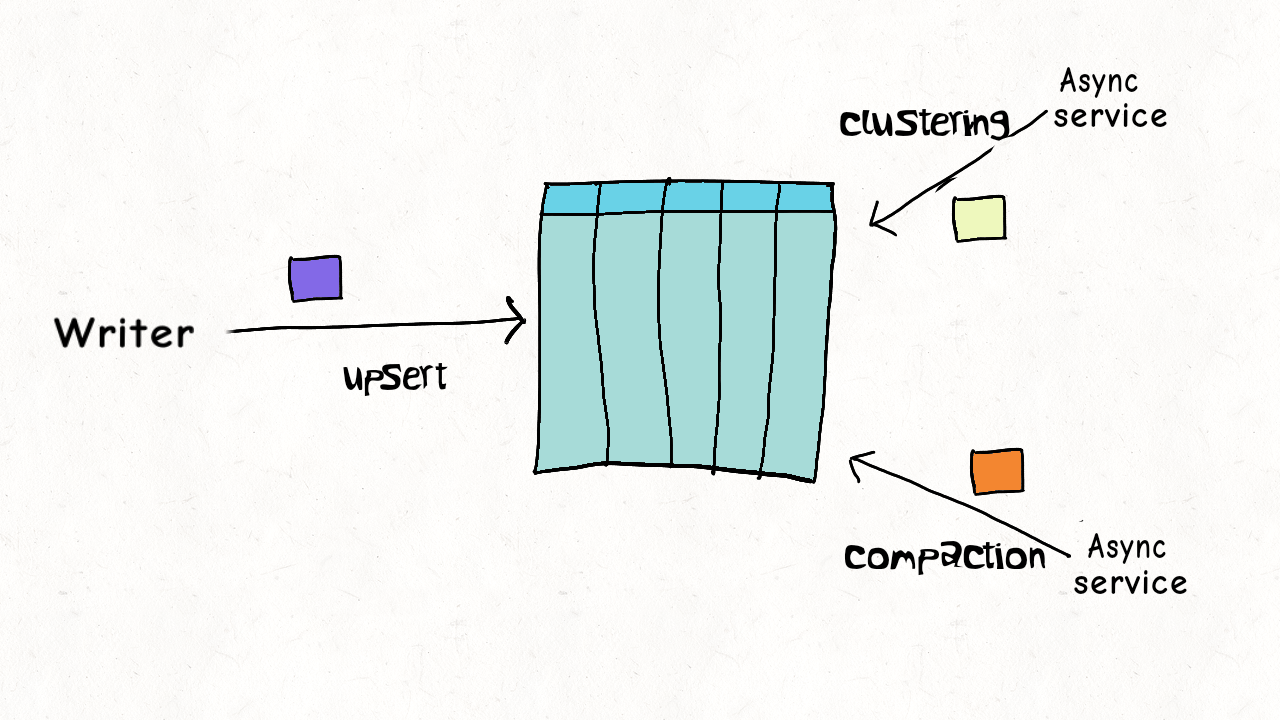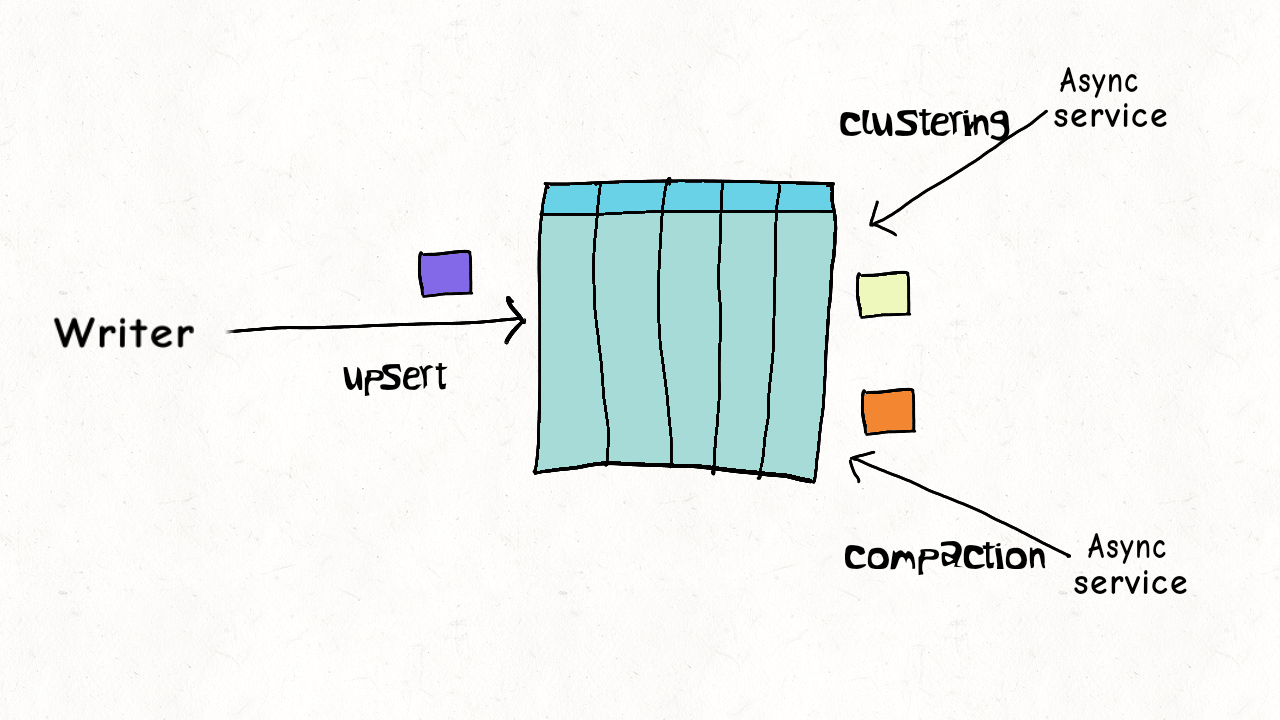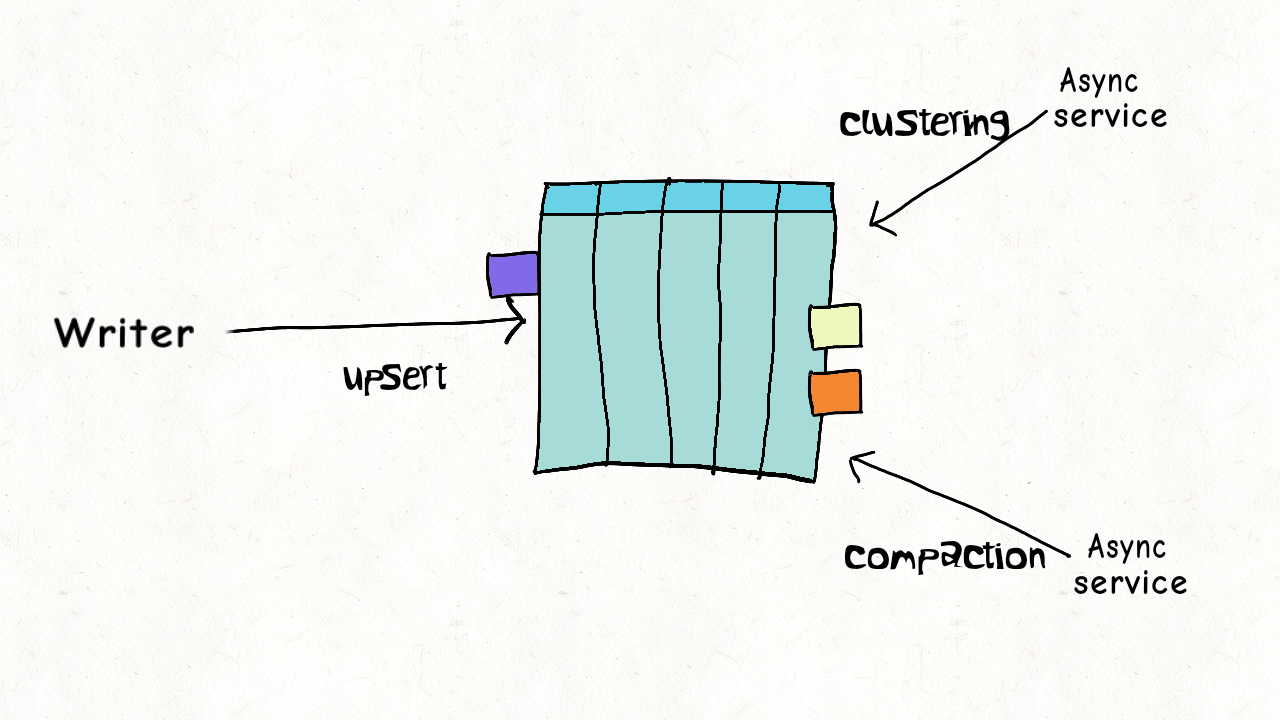
Model 3 : Multiple Writers
But it's not always possible to serialize the deletes into the same write stream or sql based deletes are required. With multiple distributed processes, some form of locking is inevitable, but like real databases Hudi's concurrency model is intelligent enough to differentiate actual writing to the table, from table services that manage or optimize the table. Hudi offers similar optimistic concurrency control across multiple writers, but table services can still execute completely lock-free and async. This means the delete job can merely encode deletes and the ingest job can log updates, while the compaction service again applies the updates/deletes to base files. Even though the delete job and ingest job can contend and starve each other like like we mentioned above, their run-times are much lower and the wastage is drastically lower, since the compaction does the heavy-lifting of parquet/columnar data writing.
All this said, there are still many ways we can improve upon this foundation.
- For starters, Hudi has already implemented a marker mechanism that tracks all the files that are part of an active write transaction and a heartbeat mechanism that can track active writers to a table. This can be directly used by other active transactions/writers to detect what other writers are doing and abort early if conflicts are detected, yielding the cluster resources back to other jobs sooner.
- While optimistic concurrency control is attractive when serializable snapshot isolation is desired, it's neither optimal nor the only method for dealing with concurrency between writers. We plan to implement a fully lock-free concurrency control using CRDTs and widely adopted stream processing concepts, over our log merge API, that has already been proven to sustain enormous continuous write volumes for the data lake.
- Touching upon key constraints, Hudi is the only lake transactional layer that ensures unique key constraints today, but limited to the record key of the table. We will be looking to expand this capability in a more general form to non-primary key fields, with the said newer concurrency models.
Finally, for data lakes to transform successfully into lakehouses, we must learn from the failing of the "hadoop warehouse" vision, which shared similar goals with the new "lakehouse" vision. Designers did not pay closer attention to the missing technology gaps against warehouses and created unrealistic expectations from the actual software. As transactions and database functionality finally goes mainstream on data lakes, we must apply these lessons and remain candid about the current shortcomings. If you are building a lakehouse, I hope this post encourages you to closely consider various operational and efficiency aspects around concurrency control. Join our fast growing community by trying out Apache Hudi or join us in conversations on Slack.