Apache Hudi 2023: A Year In Review


In the warm glow of the holiday season, I am delighted to convey a message of deep appreciation on behalf of the Hudi Project Management Committee (PMC) to all the contributors and users in the community who made 2023 an extraordinary year for Hudi.
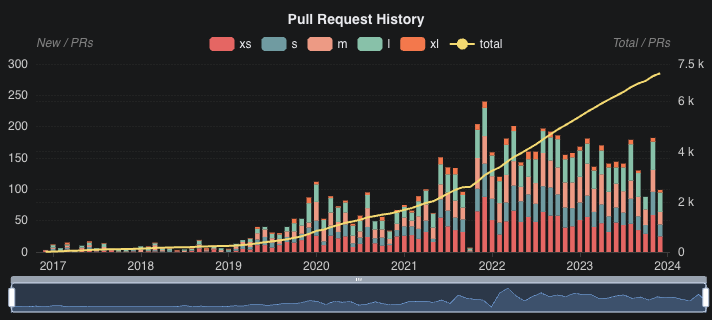
In 2023, the Hudi community continued strong engagement and activities, evident in the 1,832 pull requests created, with a significant 1,363 of these being merged. We proudly welcomed 2 new PMC members and 3 new Committers. Our community Slack channel witnessed a remarkable 44% increase in users, with numbers exceeding 3,800. Our presence on social media platforms has grown impressively, with our X (Twitter) account garnering 2,274 followers, and our newly established LinkedIn page rapidly gaining 2,245 followers in just three months. Let’s take a moment to reflect on and celebrate the myriad of exciting developments and accomplishments that have defined the year 2023 for the Hudi community.
Development Highlights
The year 2023 has been exceptionally productive for Hudi, marked by significant advancements and innovations. There have been three major releases: 0.13.0, 0.14.0, and the trailblazing 1.0.0-beta1 that have collectively reshaped the database experience for Hudi data lakehouses. Here are some brief summaries highlighting key features introduced:
Indexing has elevated to a whole new level
Hudi's new Record Level Index is a game-changing feature that boosts write performance for large tables. It achieves this by efficiently storing per-record locations, enabling rapid retrieval during index look-ups. Benchmarks indicate a 72% improvement in write latency compared to the Global Simple Index, alongside notable reductions in query latency for equality-matching queries. The new Consistent Hash Index dynamically scales the buckets for hash-based indexing schemes. By addressing data skew issues inherent in bucket index, it can achieve blazing fast look-up similar to the Record Level Index during the write process. Functional Index enables the creation and deletion of indexes on specific columns, providing users with additional means to speed up queries and adjust partitioning.
Write throughput achieves remarkable advancement
A common reason why developers choose Apache Hudi is for its industry leading write throughput and performance. The community has continued innovations on write performance including Early-conflict detection for OCC which proactively validates concurrent writes before they are written to disk, avoiding significant resource wastage and enhancing throughput. Up-leveling this, the Non-Blocking Concurrency Control introduced in 1.0 further optimizes multi-writer throughput by allowing conflicts to be resolved later in query or via compaction. Responding to popular community requests, partial update capability was implemented to allow updates to be applied only to changed fields, particularly benefiting the dimension tables that are usually super wide.
Programming APIs have a brand-new look
HoodieRecordMerger is a new abstraction that unifies the merging semantics and makes use of the engine-native representation for records in the process. Benchmark shows a ballpark of 10-20% boost for upsert performance. File Group Reader is another API that standardizes File Group access, reducing MoR tables' read latencies by approximately 20%. Enabling position-based merging and page-skipping can further accelerate snapshot queries by 5.7 times.
Usability receives significant attention
Table-valued function hudi_table_changes
simplifies performing incremental queries via SQLs.
Auto-generated keys
allows users to omit providing a record key field, especially useful for append-only tables. Among many other
user-friendly updates, two more notable ones are the addition of a
hudi-cli-bundle jar
and a revamped configuration page.
Platform capabilities are substantially enhanced
Changed Data Capture
was supported by logging additional information alongside writers. The changed data, including before
and after images, can be served through incremental queries, offering rich analytical insights.
Metaserver
offers centralized management services for operating numerous tables in lakehouse projects, signifying a major
step in Hudi's platform features.
HoodieStreamer
(formerly HoodieDeltaStreamer) remains a highly popular tool for data ingestion:
new sources
such as Protobuf Kafka source, GCS incremental source, and Pulsar source were added, further expanding
the integration capabilities.
Ecosystem integrations undergo notable expansions
On AWS, Athena supported Hudi 0.12.2 and Hudi's metadata table, elevating query performance. AWS Glue crawlers added Hudi support with Glue 4.0 working with Hudi 0.12.1, and AWS EMR extended the support matrix to cover Hudi 0.13 and 0.14. GCP improved Hudi integration in BigQuery with a new manifest file integration for improved performance. Starburst also added a Hudi connector. Execution engine support has also been extended to newer versions, including Spark 3.4 and 3.5, as well as Flink 1.16, 1.17, and 1.18.
Interoperability is the key
While Apache Hudi continues its strong growth momentum, some members of the community also decided it is time to start building interoperability bridges across Lakehouse table formats with Delta Lake and Iceberg. The recent announcement about OneTable becoming open source marks a big leap forward for all developers looking to build a data lakehouse architecture. This development not only emphasizes Hudi's commitment to openness but also enables a wider range of users to experience the technological advantages offered by Hudi.
Stay tuned for 2024
The File Group Reader APIs are poised for widespread adoption, promising benefits for numerous query engines. We also anticipate broad adoption for Non-Blocking Concurrency Control. And there's more on the horizon, including innovations like infinite timeline, secondary indexes, multi-table transactions, and the support for unstructured data. For the latest updates and detailed insights, I encourage you to visit the roadmap page.
Content Spotlight
Below is a curated list highlighting noteworthy pieces of content from the diverse Hudi community in 2023:
- Create Hudi-based near-real-time transactional data lake - AWS
- Automate schema evolution at scale with Apache Hudi - AWS
- Zoom implemented streaming log ingestion and efficient GDPR deletes using Hudi - AWS
- Lakehouse at Fortune 1 scale - Walmart
- Setting Uber’s Transactional Data Lake in Motion - Uber
- Notion’s journey: transition from Snowflake to Hudi - Notion
- Scaling and governing Robinhood's data lakehouse - Robinhood
- Feature comparison: Hudi vs Delta vs Iceberg - Kyle Weller, Onehouse
- Apache Hudi 1.0 preview: A database experience on the data lake - Sagar Sumit & Bhavani Sudha Saktheeswaran, Hudi PMC
- Hudi Metafields demystified and Knowing your data partitioning vices - Bhavani Sudha Saktheeswaran, Hudi PMC
- Record Level Index: blazing fast indexing for large-scale datasets - Shiyan Xu & Sivabalan Narayanan, Hudi PMC
- Apache Hudi from zero to one: a 10-post blog series - Shiyan Xu, Hudi PMC
- Hudi Workshop: Build a ride-share lakehouse platform on AWS - Soumil Shah, Jaganath Achari, Nadine Farah
Additionally, the official Hudi website is a treasure trove of valuable learning materials. Begin your journey on the documentation page, and then explore a wealth of talks, videos, and blogs to deepen your understanding and knowledge of Hudi.
Engage with the Community
Throughout 2023, the Hudi community played an important role in the data industry altogether, gathering and featuring in many virtual syncs, live events, meet-ups, and conference presentations. We marked our presence at a variety of events, listed here in no particular order: Re:Invent, PrestoCon, Trino Fest, Current, the Data & AI Summit, Flink Forward, the Open-source Data Summit, ApacheCon, AI.dev, QCon, OSA Con, DEWCon, and Data Council.

As we reflect on an eventful 2023, the Hudi community continues to thrive and welcomes diverse forms of engagement. For those looking to connect, our Slack group is an excellent place for general inquiries, being watched out by Hudi experts and an LLM-backed question bot. You can also participate in our weekly office hours and monthly community syncs to stay updated and involved. To keep abreast of the latest developments, follow Hudi's LinkedIn page, X (Twitter) account, and YouTube channel.
If you encounter any issues or have feature requests, we encourage you to file them through GitHub issues or JIRA tickets. For more in-depth discussions and contributions to the ongoing development of Hudi, subscribing (by sending an empty email) to our dev mailing list is a great option.
And for those inspired to contribute directly to the project, our contribution guide is your starting point. Your involvement, whether it's by contributing code, sharing ideas, or simply giving our GitHub repository a star, is greatly valued. Together, let's continue to shape Hudi's future and drive innovation in the open-source community. Here's to an even more vibrant and successful 2024 ahead!