Powering Amazon Unit Economics at Scale Using Apache Hudi
Amazon’s Profit Intelligence team built Nexus, a configuration-driven platform powered by Apache Hudi, to scale unit economics across thousands of retail use cases. Nexus manages over 1,200 tables, processes hundreds of billions of rows daily, and handles ~1 petabyte of data churn each month. This blog dives into their data lakehouse journey, Nexus architecture, Hudi integration, and key operational learnings.
Understanding and improving unit-level profitability at Amazon's scale is a massive challenge - one that requires flexibility, precision, and operational efficiency. In this blog, we walk through how Amazon’s Profit Intelligence team built a scalable, configuration-driven platform called Nexus, and how Apache Hudi became the cornerstone of its data lake architecture.
By combining declarative configuration with Hudi's advanced table management capabilities, the team has enabled thousands of retail business use cases to run seamlessly, allowing finance and pricing teams to self-serve insights on cost and profitability, without constantly relying on engineering intervention.
The Business Need: Profit Intelligence and Unit Economics
Within Amazon’s Worldwide Stores, the Selling Partner Services (SPS) team supports seller-facing operations. A key part of this effort is computing Contribution Profit - a granular metric that captures revenue, costs, and profitability at the unit level, such as a shipped item to the customer.
Contribution Profit powers decision-making for a range of downstream teams including:
- Pricing
- Forecasting
- Finance
The challenge? Supporting the scale and diversity of retail use cases across Amazon's global business, while maintaining a data platform that's both extensible and maintainable.
Amazon’s Data Lakehouse Journey
Over the past decade, the architecture behind Contribution Profit has gone through several phases of evolution, driven by the need to better support Amazon’s growing and diverse retail business use cases.
Early Phase
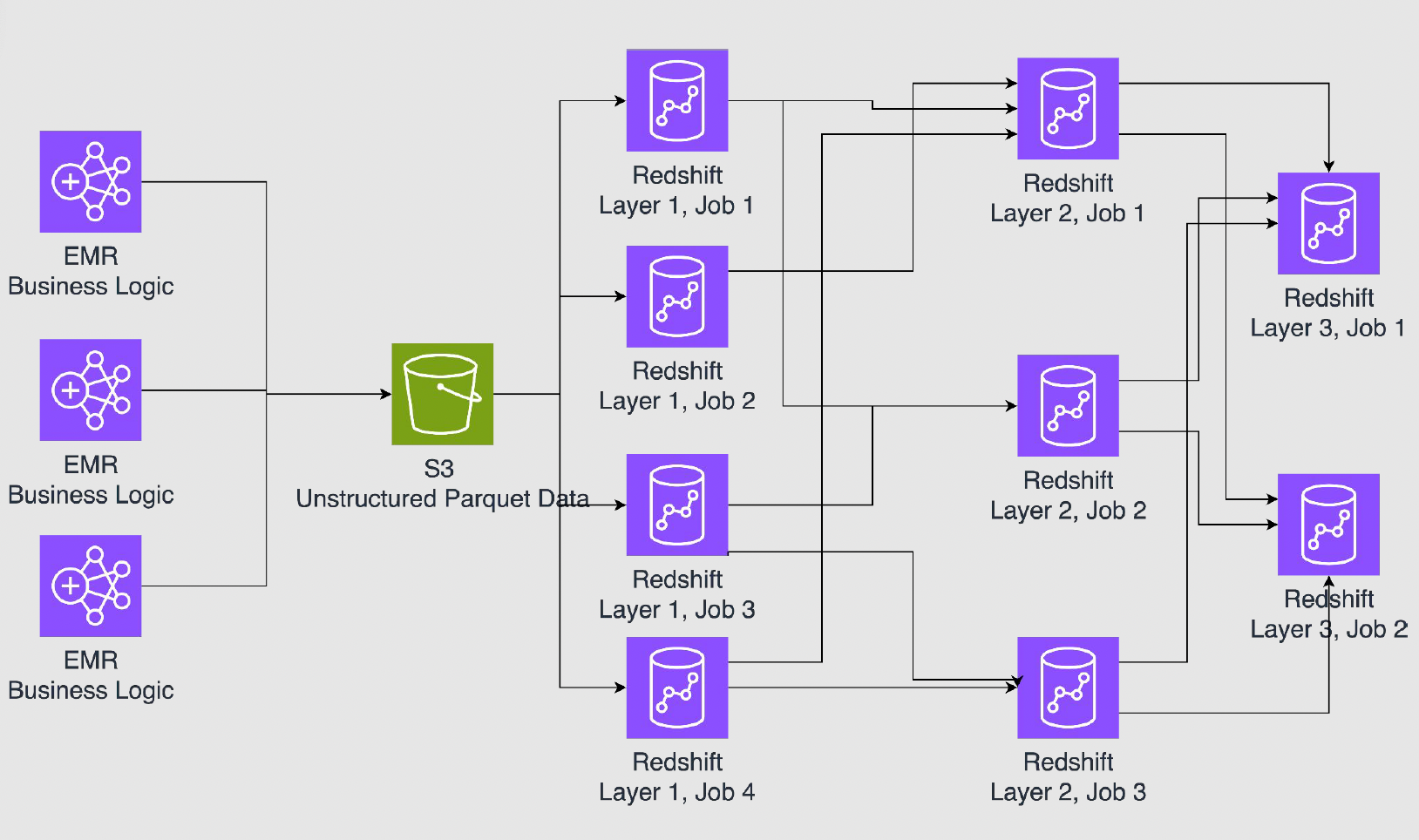
Initial implementations relied on ETL pipelines that published data to Redshift, often with unstructured job flows. Business logic could exist at various layers of the ETL and was written entirely in SQL, making it difficult to track, maintain, or modify. These pipelines lacked systematic enforcement of patterns, which led to fragmentation and technical debt.
Intermediate Phase
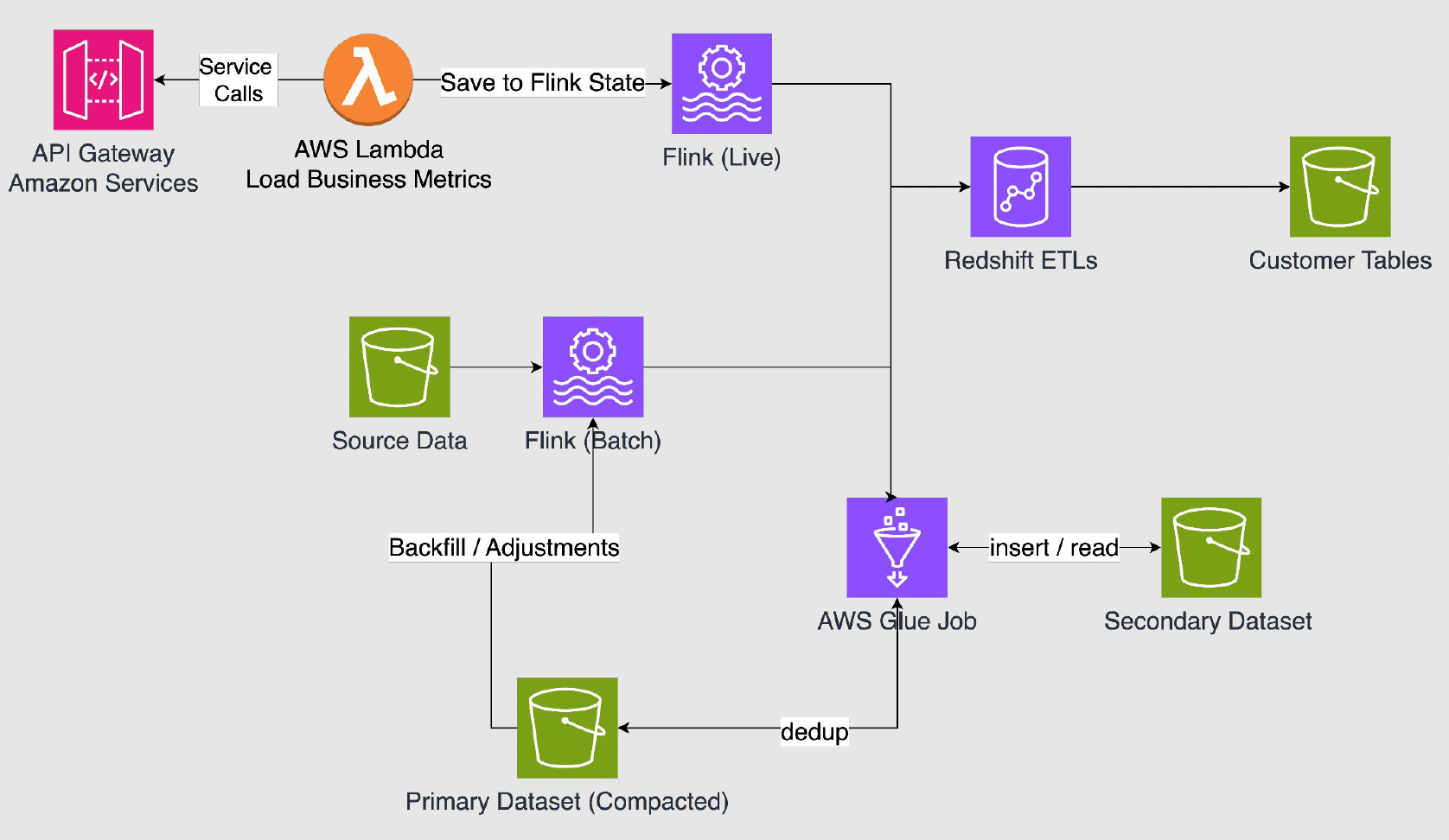
To improve scalability and support streaming workloads, the team transitioned to a setup involving Apache Flink and a custom-built data lake. Although this introduced broader data processing flexibility, it still had major drawbacks:
- Redshift-based ETLs remained in use.
- Business logic and schema changes required engineering involvement.
- There were ongoing scalability and maintainability issues with the custom data lake.
- Flink introduced operational challenges of its own, such as handling version upgrades through AWS Managed Flink and providing done signal in batch operation.
Current State: Nexus + Apache Hudi
Each of the prior approaches came with tradeoffs, especially around business logic being tightly coupled with code, making it hard for non-engineers to simulate or change metrics for a specific retail business.
Recognizing the need for better abstraction and operational maturity, the team built Nexus - a configuration-driven platform for defining and orchestrating data pipelines. All lake interactions including ingestion, transformation, schema evolution, and table management now go through Nexus. Nexus is powered by Apache Hudi, which provides the foundation for scalable ingestion, efficient upserts, schema evolution, and transactional guarantees on Amazon S3.
This new architecture enabled the team to decouple business logic from engineering code, allowing business teams to define logic declaratively. It also introduced standardization across workloads, eliminated redundant pipelines, and laid the groundwork for scaling unit economics calculations across thousands of use cases.
Key Modules of Nexus
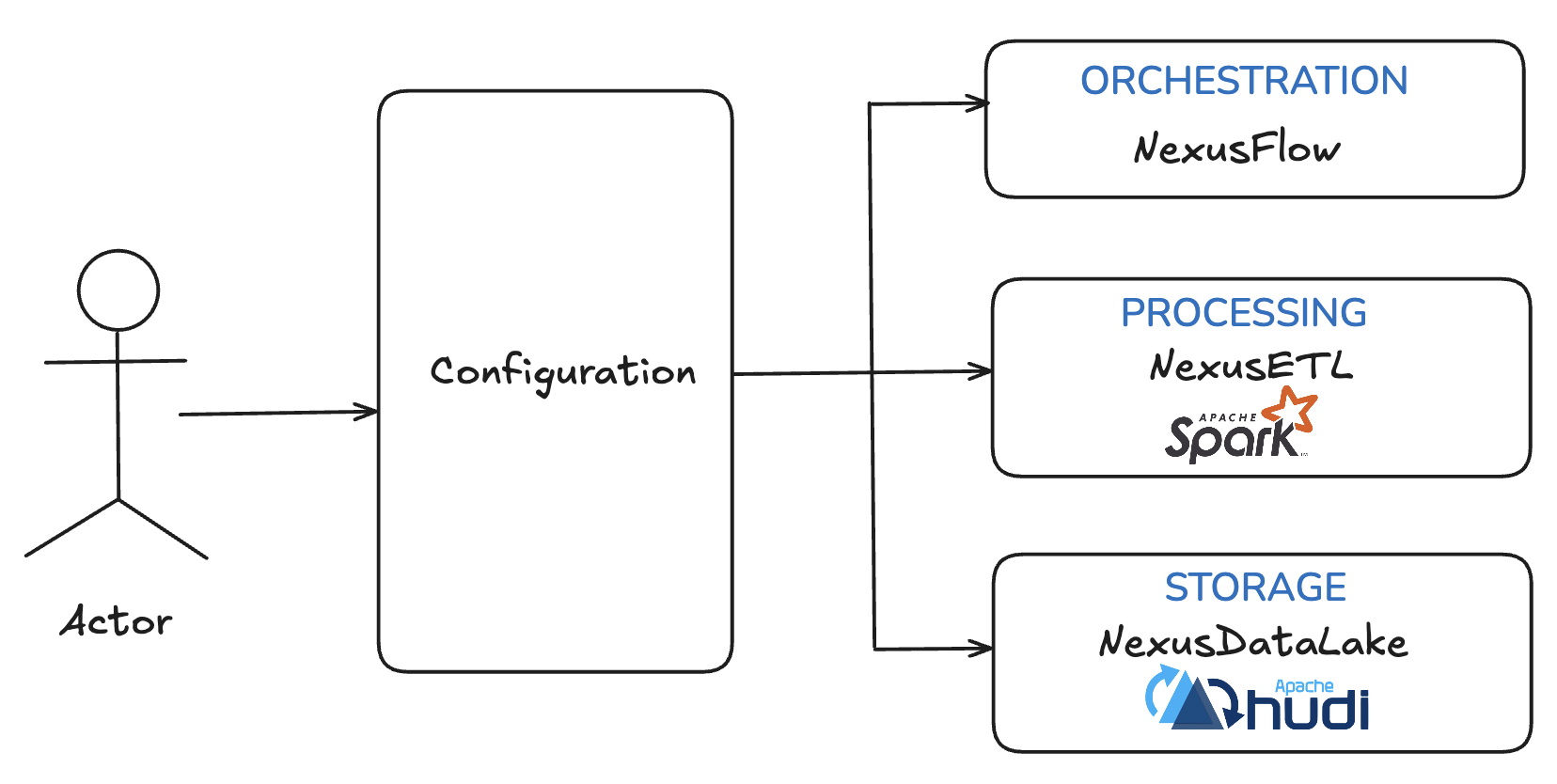
Nexus consists of four core components:
Configuration Layer
The topmost layer where users define their business logic in a declarative format. These configurations are typically generated and enriched with metadata by internal systems.
NexusFlow (Orchestration)
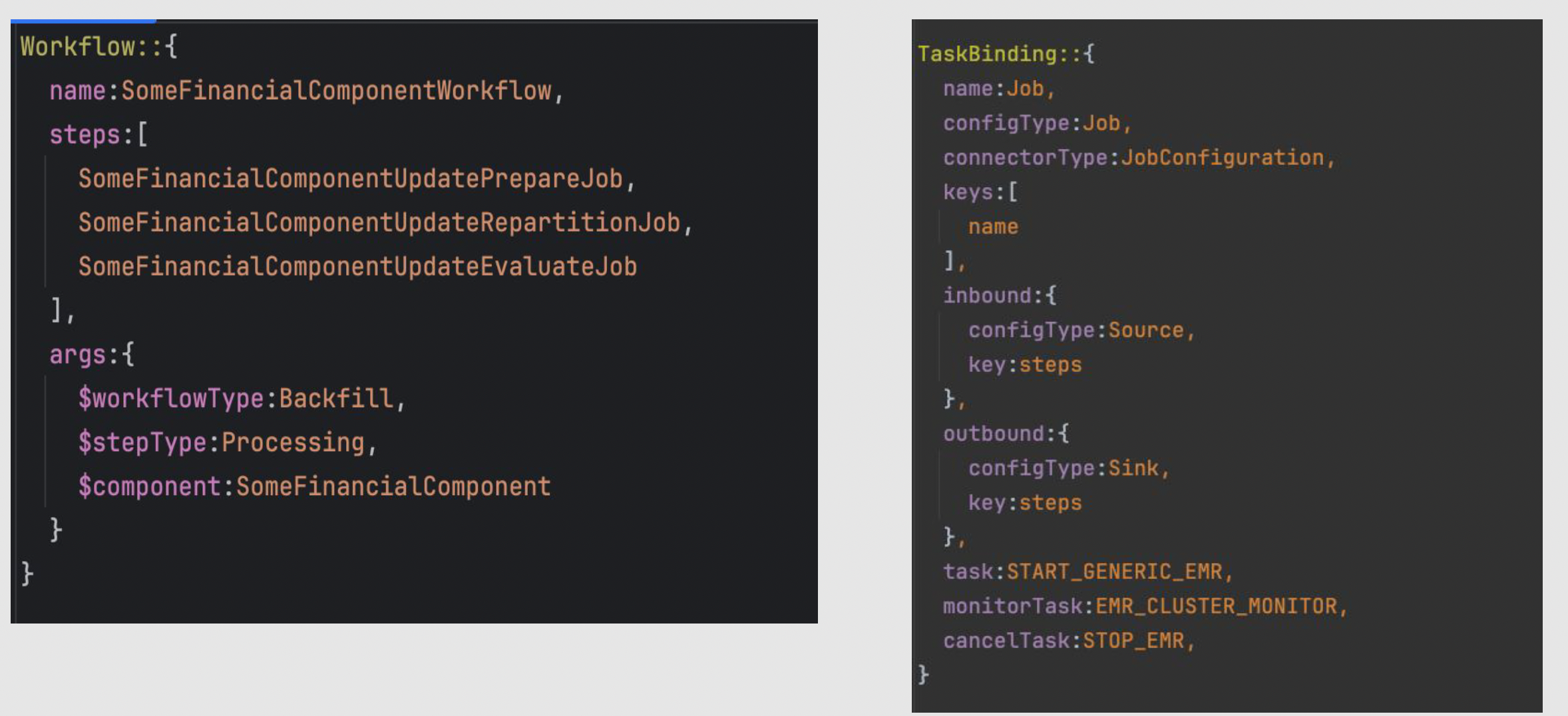
Figure: Sample NexusFlow Config
Responsible for generating and executing workflows. It operates on two levels:
- Logical Layer: Comprising NexusETL jobs and other tasks.
- Physical Layer: Implemented via AWS Step Functions to orchestrate EMR jobs and related dependencies. NexusFlow supports extensibility through a federated model and can execute diverse task types like Spark jobs, Redshift queries, wait conditions, and legacy ETLs.
NexusETL (Execution)
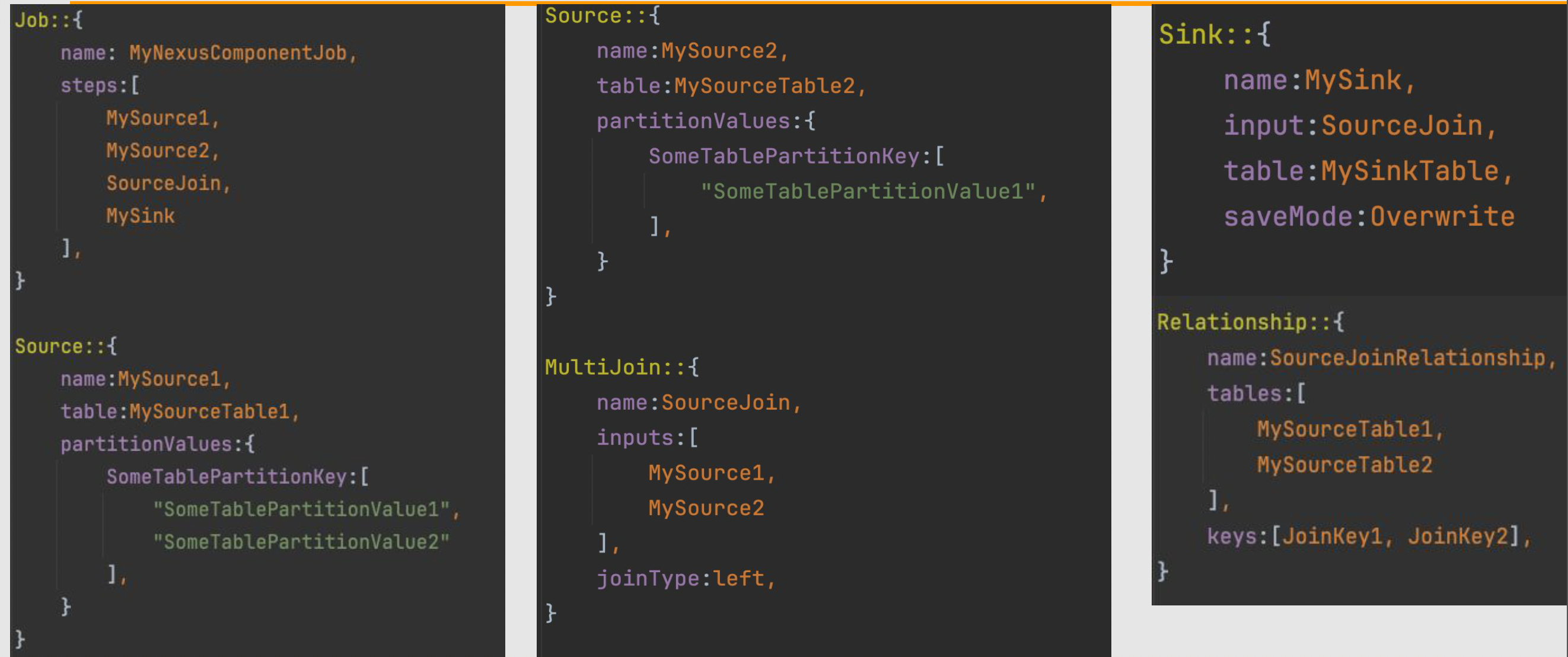
Figure: Sample NexusETL Config
Executes Spark-based data transformation jobs. Jobs are defined entirely in configuration, with support for:
- Built-in transforms like joins and filters
- Custom UDFs
- Source/Sink/Transform operators: It operates at the job abstraction level and is typically invoked by NexusFlow during orchestration.
NexusDataLake (Storage)
Figure: Sample NexusDataLake Config
A storage abstraction layer built on Apache Hudi. NexusDataLake manages:
- Table creation
- Schema inference and evolution
- Catalog integration: All interactions with Hudi, such as inserts, upserts, table schema changes, and metadata syncs are funneled through NexusETL and NexusFlow, maintaining consistency across the platform.
By standardizing how data is defined, processed, and stored, Nexus has enabled a scalable, maintainable, and extensible architecture. Every data lake interaction - from ingestion to table maintenance, is performed through this configuration-first model, which now powers hundreds of use cases across Amazon retail.
Why Apache Hudi?
Apache Hudi has been central to Nexus’ success, providing the core data lake storage layer for scalable ingestion, updates, and metadata management. It enables fast, incremental updates at massive scale while maintaining transactional guarantees on top of Amazon S3.
In Amazon’s current architecture:
- Copy-on-Write (COW) table type is used for all Hudi tables.
- Workloads generate hundreds of billions of row updates daily, with write patterns spanning concentrated single-partition updates and wide-range backfills across up to 90 partitions.
- All Hudi interactions, including inserts, schema changes, and metadata syncs, are managed through Nexus.
Key Capabilities used with Apache Hudi
-
Efficient Upserts
Hudi’s design primitives such as indexes for Copy-on-Write (CoW) tables enable high-throughput update patterns by avoiding the need to join against the entire dataset to determine which files to rewrite, which is particularly critical for our daily workloads. -
Incremental Processing
By using Hudi’s native incremental pull capabilities, downstream systems are able to consume only the changes between commits. This is essential for efficiently updating Contribution Profit metrics that power business decision-making. -
Metadata Table
Enabling the metadata table (hoodie.metadata.enable=true) significantly reduced job runtimes by avoiding expensive file listings on S3. This is an important optimization given the scale at which we process updates across more than 1200 Hudi tables. -
Schema Evolution
Table creation and evolution are fully managed through configuration in Nexus. Hudi’s built-in support for schema evolution has allowed the team to onboard new use cases and adapt to changing schemas without requiring expensive rewrites or manual interventions.
Key Learnings from Operating Hudi at Amazon Scale
Operating Apache Hudi at the scale and velocity required by Amazon’s Profit Intelligence workloads surfaced a set of hard-earned lessons, especially around concurrency, metadata handling, and cost optimization. These learnings reflect both architectural refinements and operational trade-offs that others adopting Hudi at large scale may find useful.
1. Concurrency Control
At Amazon’s ingestion scale - hundreds of billions of rows per day and thousands of concurrent table updates, multi-writer concurrency is a reality, not an edge case.
The team initially used Optimistic Concurrency Control (OCC), which works well in environments with low write conflicts. OCC assumes that concurrent writers rarely overlap, and when they do, the job retries after detecting a conflict. However, in high-contention scenarios, like multiple jobs writing to the same partition within a short time window, this led to frequent retries and job failures.
To resolve this, the team pivoted to a new table structure designed to minimize concurrent insertions. This change helped reduce contention by lowering the likelihood of multiple writers operating on overlapping partitions simultaneously. The updated design enabled using OCC while avoiding the excessive retries and failures we had initially encountered.
2. Metadata Table Management: Async vs Sync Trade-Offs
Apache Hudi’s metadata table dramatically improves performance by avoiding expensive file listings on cloud object stores like S3. It maintains a persistent index of files, enabling faster operations such as file pruning, and data skipping.
The team enabled Hudi’s metadata table early (hoodie.metadata.enable=true) and started off with synchronous cleaning but switched to asynchronous cleaning to reduce job runtime. However, we ran into an issue when experimenting with asynchronous cleaning. Due to a known issue (#11535), async cleaning wasn’t properly cleaning up metadata entries.
To ensure the metadata tables were properly cleaned, we switched all of our Hudi workloads back to synchronous cleaning.
3. Cost Management
While Apache Hudi helped Amazon reduce data duplication and improve ingestion efficiency, we quickly realized that operational costs were not driven by storage - but by the API interaction patterns with S3.
Breakdown of the cost profile:
- 70% of total cost came from
PUTrequests (writes) - Combined
PUT + GEToperations accounted for 80% of the bill - Storage cost remained a small fraction, even with 3+ PB of total data under management
Their data ingestion patterns contributed to this:
- Daily workloads: Heavy concentration (99%) of updates into a single partition
- Backfill workloads: Spread evenly across 30–90 partitions
To manage this:
- We moved to S3 Intelligent-Tiering to reduce unused data storage costs
- Enabled EMR cluster auto-scaling to dynamically adjust compute resources
- Batched writes and carefully tuned Hudi configurations (e.g.,
write.batch.size,compaction.small.file.limit) to reduce unnecessary file churn
Operational Scale: Nexus by the Numbers
| Metric | Value |
|---|---|
| Tables Managed | 1200+ (5–15 updates/day per table) |
| Legacy SQL Deprecated | 300,000+ lines |
| Total Data Managed | ~3 Petabytes |
| Monthly Data Changes | ~1 Petabyte added/deleted |
| Daily Record Updates | Hundreds of billions |
| Developer Time Saved | 300+ days |
Nexus with Apache Hudi as the foundation has significantly improved the scale, modularity, and maintainability of the data lake operations at Amazon. As the business use cases scale, the team is also focused on managing the increasing complexity of the data lake, while ensuring that both technical and non-technical stakeholders can interact with Nexus effectively.
This blog is based on Amazon’s presentation at the Hudi Community Sync. If you are interested in watching the recorded version of the video, you can find it here.