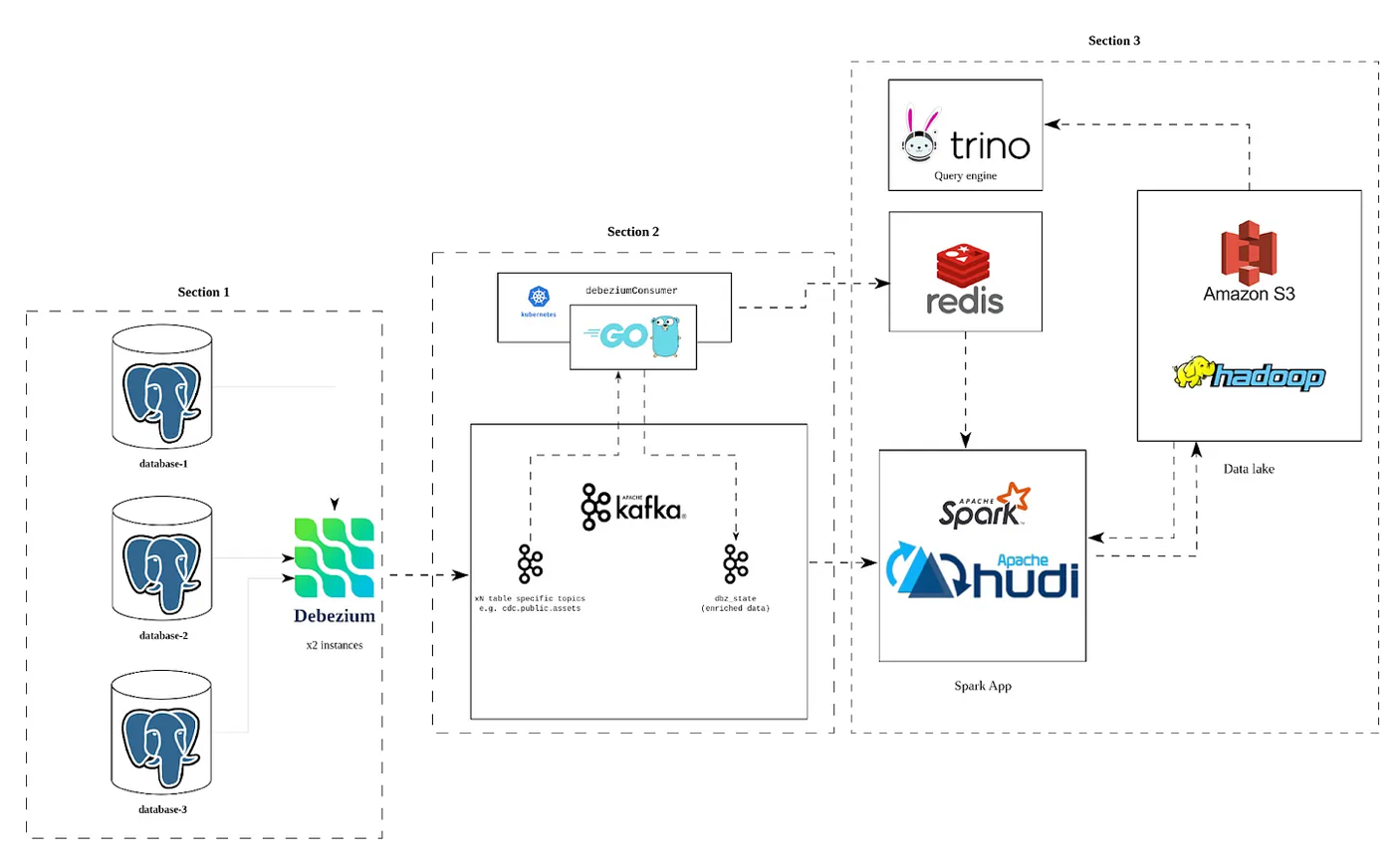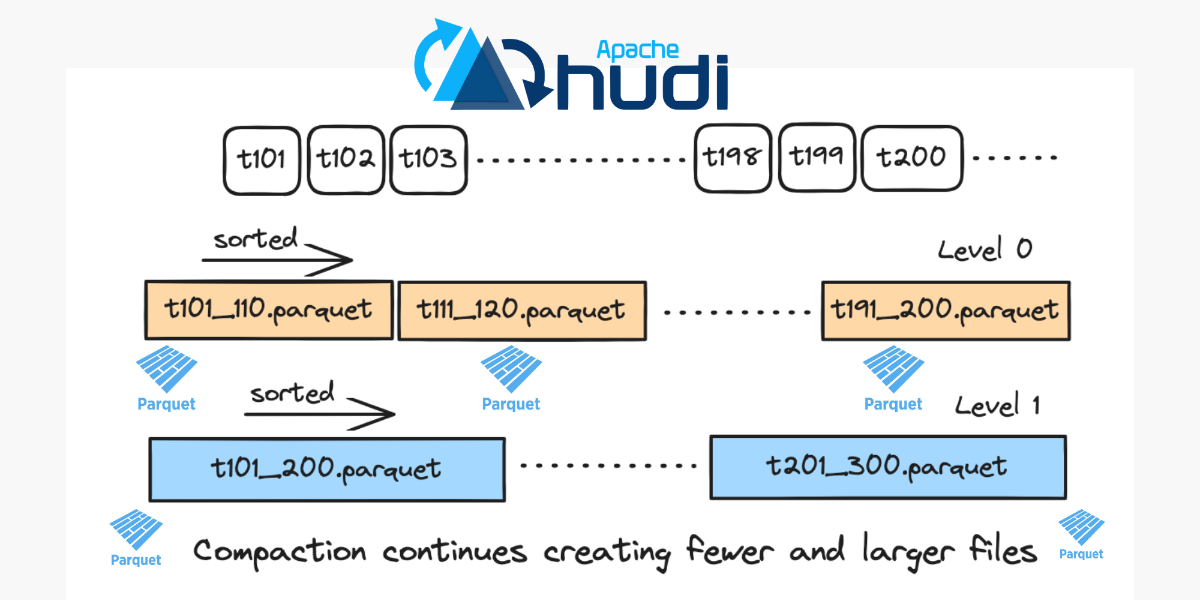
Exploring Apache Hudi’s New Log-Structured Merge (LSM) Timeline
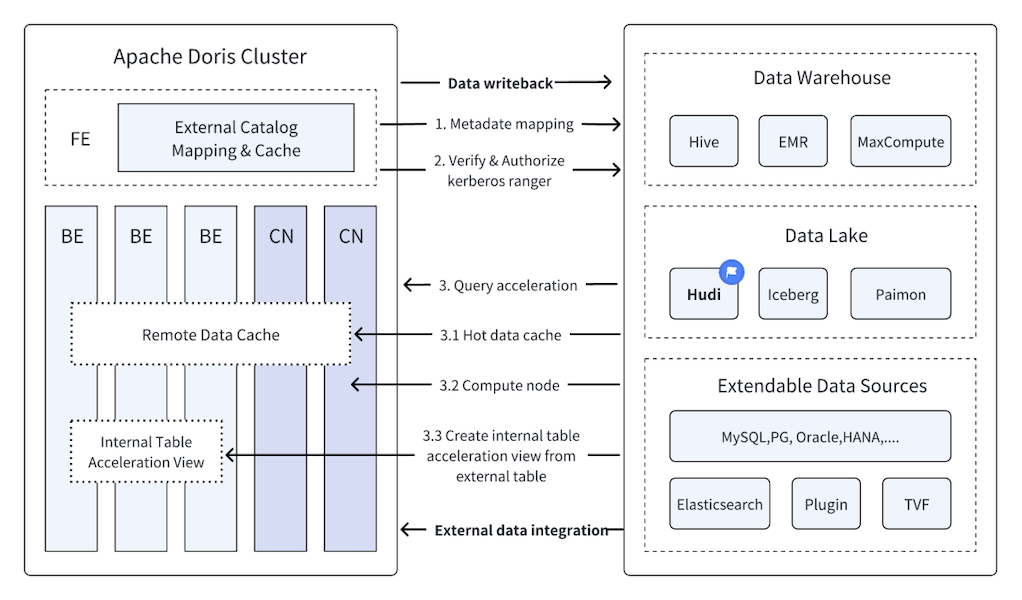
How Doris + Hudi Turned the Impossible Into the Everyday
Why Walmart Chose Apache Hudi for Their Lakehouse
From Swamp to Stream: How Apache Hudi Transforms the Modern Data Lake
Integrating Apache Doris and Hudi for Data Querying and Migration
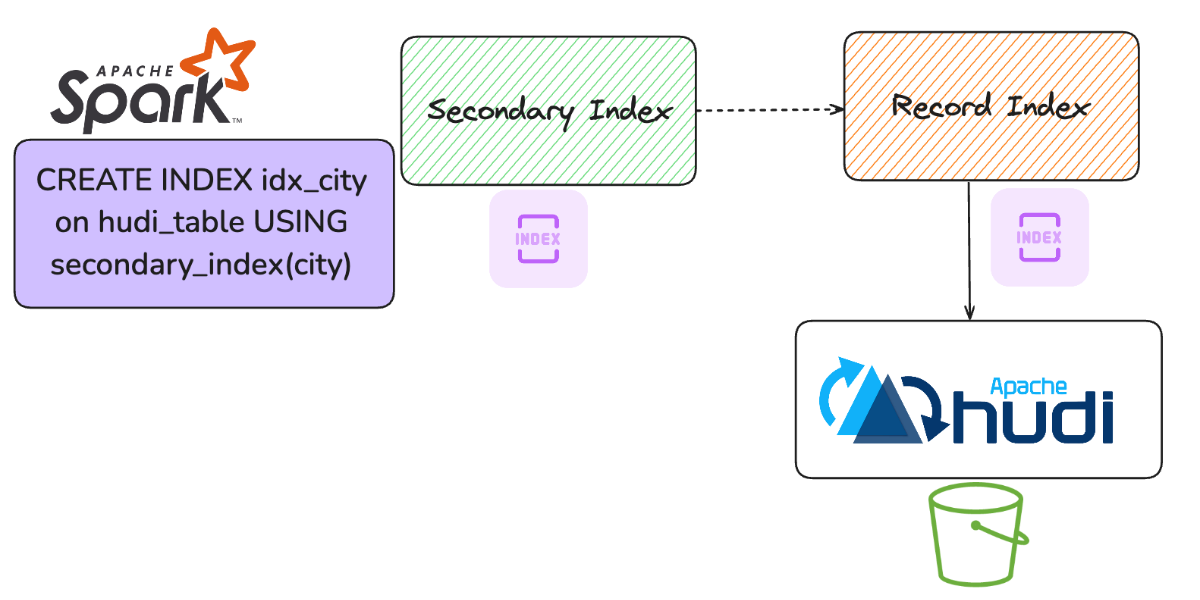
Introducing Secondary Index in Apache Hudi Lakehouse Platform

Powering Amazon Unit Economics at Scale Using Apache Hudi
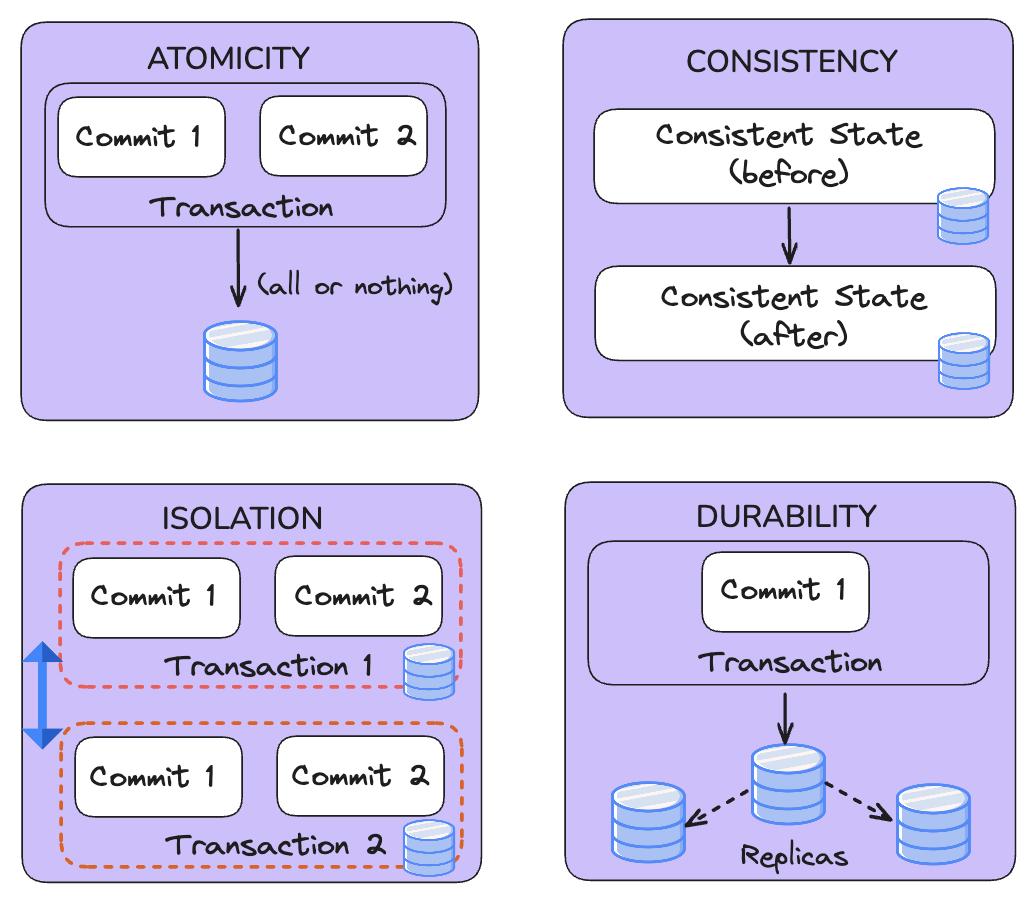
ACID Transactions in an Open Data Lakehouse

What is Clustering in an Open Data Lakehouse?
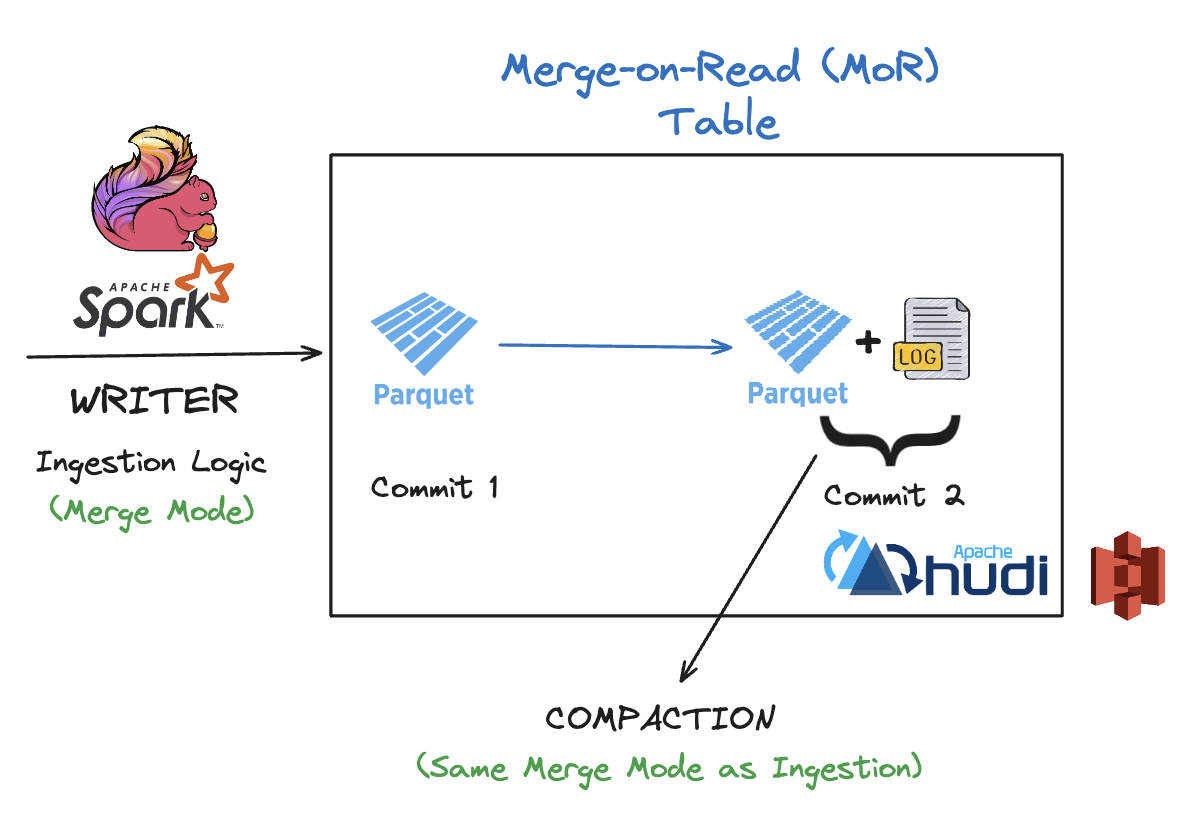
Data Deduplication Strategies in an Open Lakehouse Architecture