We will look at how to migrate a large parquet table to Hudi without having to rewrite the entire dataset.
Motivation:
Apache Hudi maintains per record metadata to perform core operations such as upserts and incremental pull. To take advantage of Hudi’s upsert and incremental processing support, users would need to rewrite their whole dataset to make it an Apache Hudi table. Hudi 0.6.0 comes with an experimental feature to support efficient migration of large Parquet tables to Hudi without the need to rewrite the entire dataset.
High Level Idea:
Per Record Metadata:
Apache Hudi maintains record level metadata for perform efficient upserts and incremental pull.

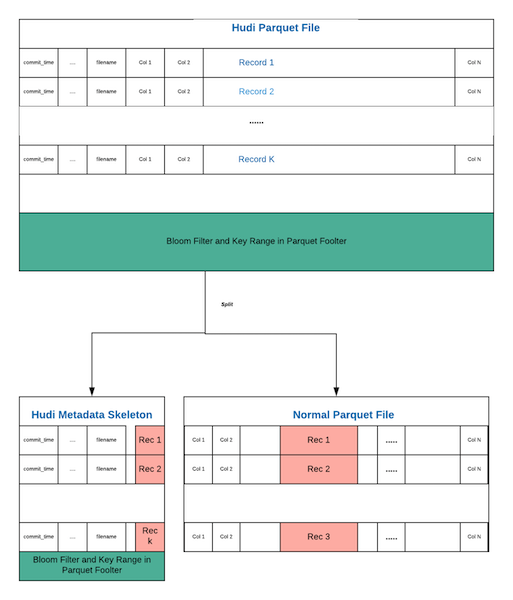
Apache HUDI physical file contains 3 parts
- For each record, 5 HUDI metadata fields with column indices 0 to 4
- For each record, the original data columns that comprises the record (Original Data)
- Additional Hudi Metadata at file footer for index lookup
The parts (1) and (3) constitute what we term as “Hudi skeleton”. Hudi skeleton contains additional metadata that it maintains in each physical parquet file for supporting Hudi primitives. The conceptual idea is to decouple Hudi skeleton data from original data (2). Hudi skeleton can be stored in a Hudi file while the original data is stored in an external non-Hudi file. A migration of large parquet would result in creating only Hudi skeleton files without having to rewrite original data.
Design Deep Dive:
For a deep dive on the internals, please take a look at the RFC document
Migration:
Hudi supports 2 modes when migrating parquet tables. We will use the term bootstrap and migration interchangeably in this document.
- METADATA_ONLY : In this mode, record level metadata alone is generated for each source record and stored in new bootstrap location.
- FULL_RECORD : In this mode, record level metadata is generated for each source record and both original record and metadata for each record copied
You can pick and choose these modes at partition level. One of the common strategy would be to use FULL_RECORD mode for a small set of "hot" partitions which are accessed more frequently and METADATA_ONLY for a larger set of "warm" partitions.
Query Engine Support:
For a METADATA_ONLY bootstrapped table, Spark - data source, Spark-Hive and native Hive query engines are supported. Presto support is in the works.
Ways To Migrate :
There are 2 ways to migrate a large parquet table to Hudi.
- Spark Datasource Write
- Hudi DeltaStreamer
We will look at how to migrate using both these approaches.
Configurations:
These are bootstrap specific configurations that needs to be set in addition to regular hudi write configurations.
| Configuration Name | Default | Mandatory ? | Description |
|---|---|---|---|
| hoodie.bootstrap.base.path | Yes | Base Path of source parquet table. | |
| hoodie.bootstrap.parallelism | 1500 | Yes | Spark Parallelism used when running bootstrap |
| hoodie.bootstrap.keygen.class | Yes | Bootstrap Index internally used by Hudi to map Hudi skeleton and source parquet files. | |
| hoodie.bootstrap.mode.selector | org.apache.hudi.client.bootstrap.selector.MetadataOnlyBootstrapModeSelector | Yes | Bootstap Mode Selector class. By default, Hudi employs METADATA_ONLY boostrap for all partitions. |
| hoodie.bootstrap.partitionpath.translator.class | org.apache.hudi.client.bootstrap.translator. IdentityBootstrapPartitionPathTranslator | No | For METADATA_ONLY bootstrap, this class allows customization of partition paths used in Hudi target dataset. By default, no customization is done and the partition paths reflects what is available in source parquet table. |
| hoodie.bootstrap.full.input.provider | org.apache.hudi.bootstrap.SparkParquetBootstrapDataProvider | No | For FULL_RECORD bootstrap, this class provides the input RDD of Hudi records to write. |
| hoodie.bootstrap.mode.selector.regex.mode | METADATA_ONLY | No | Bootstrap Mode used when the partition matches the regex pattern in hoodie.bootstrap.mode.selector.regex . Used only when hoodie.bootstrap.mode.selector set to BootstrapRegexModeSelector. |
| hoodie.bootstrap.mode.selector.regex | .* | No | Partition Regex used when hoodie.bootstrap.mode.selector set to BootstrapRegexModeSelector. |
Spark Data Source:
Here, we use a Spark Datasource Write to perform bootstrap. Here is an example code snippet to perform METADATA_ONLY bootstrap.
import org.apache.hudi.{DataSourceWriteOptions, HoodieDataSourceHelpers}
import org.apache.hudi.config.{HoodieBootstrapConfig, HoodieWriteConfig}
import org.apache.hudi.keygen.SimpleKeyGenerator
import org.apache.spark.sql.SaveMode
val bootstrapDF = spark.emptyDataFrame
bootstrapDF.write
.format("hudi")
.option(HoodieWriteConfig.TABLE_NAME, "hoodie_test")
.option(DataSourceWriteOptions.OPERATION_OPT_KEY, DataSourceWriteOptions.BOOTSTRAP_OPERATION_OPT_VAL)
.option(DataSourceWriteOptions.RECORDKEY_FIELD_OPT_KEY, "_row_key")
.option(DataSourceWriteOptions.PARTITIONPATH_FIELD_OPT_KEY, "datestr")
.option(HoodieBootstrapConfig.BOOTSTRAP_BASE_PATH_PROP, srcPath)
.option(HoodieBootstrapConfig.BOOTSTRAP_KEYGEN_CLASS, classOf[SimpleKeyGenerator].getName)
.mode(SaveMode.Overwrite)
.save(basePath)
Here is an example code snippet to perform METADATA_ONLY bootstrap for August 20 2020 - August 29 2020 partitions and FULL_RECORD bootstrap for other partitions.
import org.apache.hudi.bootstrap.SparkParquetBootstrapDataProvider
import org.apache.hudi.client.bootstrap.selector.BootstrapRegexModeSelector
import org.apache.hudi.{DataSourceWriteOptions, HoodieDataSourceHelpers}
import org.apache.hudi.config.{HoodieBootstrapConfig, HoodieWriteConfig}
import org.apache.hudi.keygen.SimpleKeyGenerator
import org.apache.spark.sql.SaveMode
val bootstrapDF = spark.emptyDataFrame
bootstrapDF.write
.format("hudi")
.option(HoodieWriteConfig.TABLE_NAME, "hoodie_test")
.option(DataSourceWriteOptions.OPERATION_OPT_KEY, DataSourceWriteOptions.BOOTSTRAP_OPERATION_OPT_VAL)
.option(DataSourceWriteOptions.RECORDKEY_FIELD_OPT_KEY, "_row_key")
.option(DataSourceWriteOptions.PARTITIONPATH_FIELD_OPT_KEY, "datestr")
.option(DataSourceWriteOptions.PRECOMBINE_FIELD_OPT_KEY, "timestamp")
.option(HoodieBootstrapConfig.BOOTSTRAP_BASE_PATH_PROP, srcPath)
.option(HoodieBootstrapConfig.BOOTSTRAP_KEYGEN_CLASS, classOf[SimpleKeyGenerator].getName)
.option(HoodieBootstrapConfig.BOOTSTRAP_MODE_SELECTOR, classOf[BootstrapRegexModeSelector].getName)
.option(HoodieBootstrapConfig.BOOTSTRAP_MODE_SELECTOR_REGEX, "2020/08/2[0-9]")
.option(HoodieBootstrapConfig.BOOTSTRAP_MODE_SELECTOR_REGEX_MODE, "METADATA_ONLY")
.option(HoodieBootstrapConfig.FULL_BOOTSTRAP_INPUT_PROVIDER, classOf[SparkParquetBootstrapDataProvider].getName)
.mode(SaveMode.Overwrite)
.save(basePath)
Hoodie DeltaStreamer:
Hoodie Deltastreamer allows bootstrap to be performed using --run-bootstrap command line option.
If you are planning to use delta-streamer after the initial boostrap to incrementally ingest data to the new hudi dataset, you need to pass either --checkpoint or --initial-checkpoint-provider to set the initial checkpoint for the deltastreamer.
Here is an example for running METADATA_ONLY bootstrap using Delta Streamer.
spark-submit --package org.apache.hudi:hudi-spark-bundle_2.11:0.6.0
--conf 'spark.serializer=org.apache.spark.serializer.KryoSerializer' \
--class org.apache.hudi.utilities.deltastreamer.HoodieDeltaStreamer \
--run-bootstrap \
--target-base-path <Hudi_Base_Path> \
--target-table <Hudi_Table_Name> \
--props <props_file> \
--checkpoint <initial_checkpoint_if_you_are_going_to_use_deltastreamer_to_incrementally_ingest> \
--hoodie-conf hoodie.bootstrap.base.path=<Parquet_Source_base_Path> \
--hoodie-conf hoodie.datasource.write.recordkey.field=_row_key \
--hoodie-conf hoodie.datasource.write.partitionpath.field=datestr \
--hoodie-conf hoodie.bootstrap.keygen.class=org.apache.hudi.keygen.SimpleKeyGenerator
spark-submit --package org.apache.hudi:hudi-spark-bundle_2.11:0.6.0
--conf 'spark.serializer=org.apache.spark.serializer.KryoSerializer' \
--class org.apache.hudi.utilities.deltastreamer.HoodieDeltaStreamer \
--run-bootstrap \
--target-base-path <Hudi_Base_Path> \
--target-table <Hudi_Table_Name> \
--props <props_file> \
--checkpoint <initial_checkpoint_if_you_are_going_to_use_deltastreamer_to_incrementally_ingest> \
--hoodie-conf hoodie.bootstrap.base.path=<Parquet_Source_base_Path> \
--hoodie-conf hoodie.datasource.write.recordkey.field=_row_key \
--hoodie-conf hoodie.datasource.write.partitionpath.field=datestr \
--hoodie-conf hoodie.bootstrap.keygen.class=org.apache.hudi.keygen.SimpleKeyGenerator \
--hoodie-conf hoodie.bootstrap.full.input.provider=org.apache.hudi.bootstrap.SparkParquetBootstrapDataProvider \
--hoodie-conf hoodie.bootstrap.mode.selector=org.apache.hudi.client.bootstrap.selector.BootstrapRegexModeSelector \
--hoodie-conf hoodie.bootstrap.mode.selector.regex="2020/08/2[0-9]" \
--hoodie-conf hoodie.bootstrap.mode.selector.regex.mode=METADATA_ONLY
Known Caveats
- Need proper defaults for the bootstrap config : hoodie.bootstrap.full.input.provider. Here is the ticket
- DeltaStreamer manages checkpoints inside hoodie commit files and expects checkpoints in previously committed metadata. Users are expected to pass checkpoint or initial checkpoint provider when performing bootstrap through deltastreamer. Such support is not present when doing bootstrap using Spark Datasource. Here is the ticket.