Build Your First Hudi Lakehouse with AWS S3 and AWS Glue

Soumil Shah is a Hudi community champion building YouTube content so developers can easily get started incorporating a lakehouse into their data infrastructure. In this video, Soumil shows you how to get started with AWS Glue, AWS S3, Hudi and Athena.
In this tutorial, you’ll learn how to:
- Create and configure AWS Glue
- Create a Hudi Table
- Create a Spark Data Frame
- Add data to the Hudi Table
- Query data via Athena
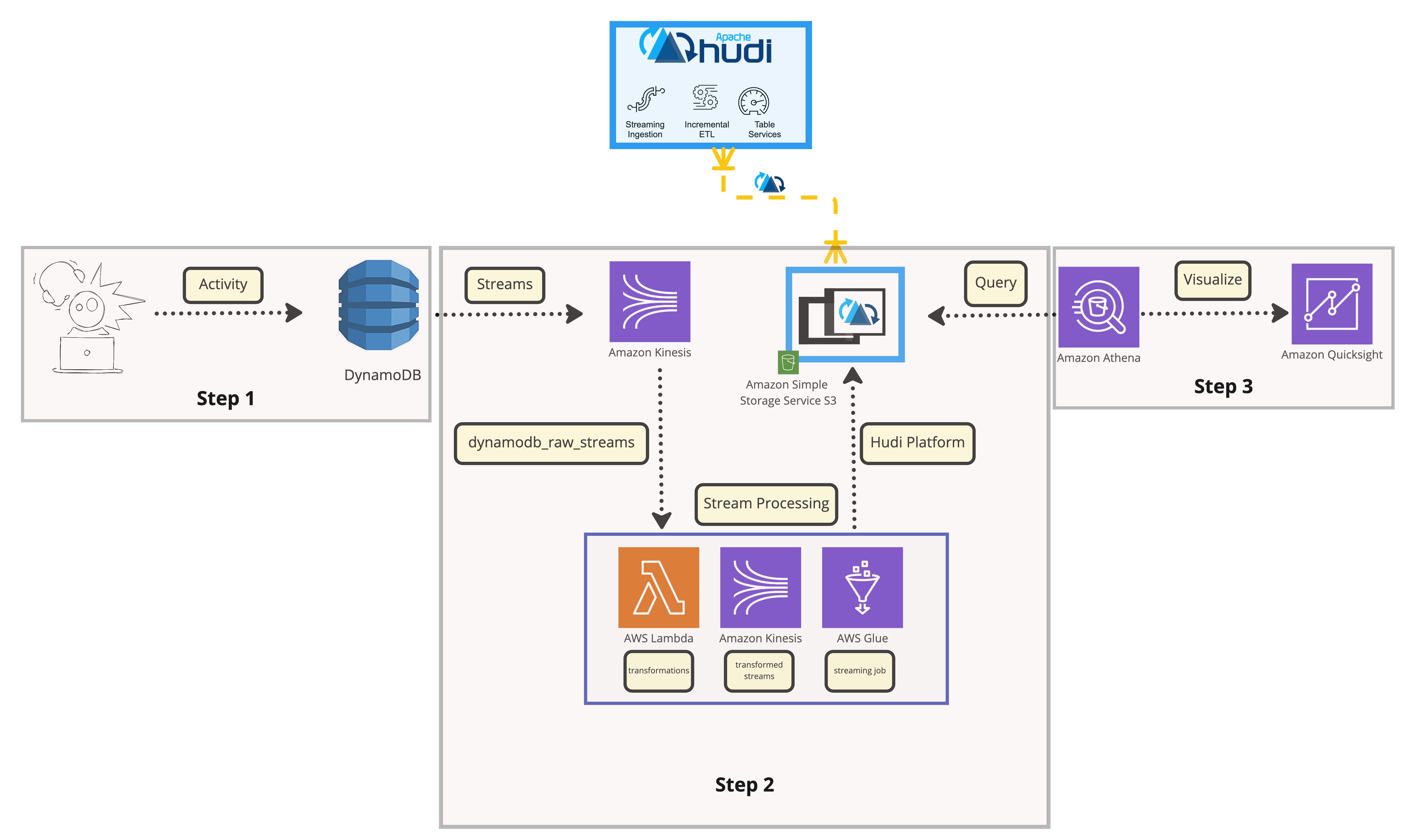
Step 1: Users in this architecture purchase things from online retailers and generate an order transaction that is kept in DynamoDB.
Step 2: The raw data layer stores the order transaction data that is fed into the data lake. To accomplish this, enable Kinesis Data Streams for DynamoDB, and we will stream real-time transactions from DynamoDB into kinesis data streams, process the streaming data with lambda, and insert the data into the next kinesis stream, where a glue streaming job will process and insert the data into Apache Hudi Transaction data lake.
Step 3: Users can build dashboards and derive insights using QuickSight.
Getting Started
To get started on building this data app, follow the YouTube video on Build Datalakes on S3 and Glue with Apache HUDI.
Follow the the step-by-step instructions.
Apply the code source.
Questions
If you run into blockers doing this tutorial, please reach out on the Apache Hudi community and tag soumilshah1995 to help debug.