Column File Formats: How Hudi Leverages Parquet and ORC
Introduction
Apache Hudi emerges as a game-changer in the big data ecosystem by transforming data lakes into transactional hubs. Unlike traditional data lakes which struggle with updates and deletes, Hudi empowers users with functionalities like data ingestion, streaming updates (upserts), and even deletions. This allows for efficient incremental processing, keeping your data pipelines agile and data fresh for real-time analytics. Hudi seamlessly integrates with existing storage solutions and boasts compatibility with popular columnar file formats like Parquet and ORC. Choosing the right file format is crucial for optimized performance and efficient data manipulation within Hudi, as it directly impacts processing speed and storage efficiency. This blog will delve deeper into these features, and explore the significance of file format selection.
How does data storage work in Apache Hudi
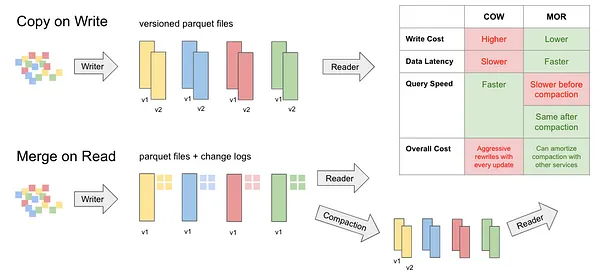
Apache Hudi offers two table storage options: Copy-on-Write (COW) and Merge-on-Read (MOR).
- COW tables:
- Data is stored in base files, with Parquet and ORC being the supported formats.
- Updates involve rewriting the entire base file with the modified data.
- MOR tables:
- Data resides in base files, again supporting Parquet and ORC formats.
- Updates are stored in separate delta files (using Apache Avro format) and later merged with the base file by a periodic compaction process in the background.
Parquet vs ORC for your Apache Hudi Base File
Choosing the right file format for your Hudi environment depends on your specific needs. Here's a breakdown of Parquet, and ORC along with their strengths, weaknesses, and ideal use cases within Hudi:
Apache Parquet
Apache Parquet is a columnar storage file format. It’s designed for efficiency and performance, and it’s particularly well-suited for running complex queries on large datasets.
Pros of Parquet:
- Columnar Storage: Unlike row-based files, Parquet is columnar-oriented. This means it stores data by columns, which allows for more efficient disk I/O and compression. It reduces the amount of data transferred from disk to memory, leading to faster query performance.
- Compression: Parquet has good compression and encoding schemes. It reduces the disk storage space and improves performance, especially for columnar data retrieval, which is a common case in data analytics.
Cons of Parquet:
- Write-heavy Workloads: Since Parquet performs column-wise compression and encoding, the cost of writing data can be high for write-heavy workloads.
- Small Data Sets: Parquet may not be the best choice for small datasets because the advantages of its columnar storage model aren’t as pronounced.
Use Cases for Parquet:
- Parquet is an excellent choice when dealing with large, complex, and nested data structures, especially for read-heavy workloads. Its columnar storage approach makes it an excellent choice for data lakehouse solutions where aggregation queries are common.
Optimized Row Columnar (ORC)
Apache ORC is another popular file format that is self-describing, and type-aware columnar file format.
Pros of ORC:
- Compression: ORC provides impressive compression rates that minimize storage space. It also includes lightweight indexes stored within the file, helping to improve read performance.
- Complex Types: ORC supports complex types, including structs, lists, maps, and union types.
Cons of ORC:
- Less Community Support: Compared to Parquet, ORC has less community support, meaning fewer resources, libraries, and tools for this file format.
- Write Costs: Similar to Parquet, ORC may have high write costs due to its columnar nature.
Use Cases for ORC:
- ORC is commonly used in cases where high-speed writing is necessary.
Choosing the Right Format:
- Prioritize query performance: If complex analytical queries are your primary use case, Parquet is the clear winner due to its superior columnar access.
- Balance performance and cost: ORC offers a good balance between read/write performance and compression, making it suitable for general-purpose data storage in Hudi.
Remember, the best format depends on your specific Hudi application. Consider your workload mix, and performance requirements to make an informed decision.
Conclusion
In conclusion, understanding file formats is crucial for optimizing your Hudi data management. Parquet for COW and MOR tables excels in analytical queries with its columnar storage and rich metadata. ORC for COW and MOR tables strikes a balance between read/write performance and compression for general-purpose storage. Avro comes into play for storing delta table data in MOR tables. By considering these strengths, you can make informed decisions on file formats to best suit your big data workloads within the Hudi framework.
Unleash the power of Apache Hudi for your big data challenges! Head over to https://hudi.apache.org/ and dive into the quickstarts to get started. Want to learn more? Join our vibrant Hudi community! Attend the monthly Community Call or hop into the Apache Hudi Slack to ask questions and gain deeper insights.