Understanding Data Lake Change Data Capture
Introduction
In data management, two concepts have garnered significant attention: data lakes and change data capture (CDC).
Data Lake
Data lakes serve as vast repositories that store raw data in its native format until needed for analytics.
Change Data Capture
Change Data Capture (CDC) is a technique used to identify and capture data changes, ensuring that the data remains fresh and consistent across various systems.
Combining CDC with data lakes can significantly simplify data management by addressing several challenges commonly faced by ETL pipelines delivering data from transactional databases to analytical databases. These include maintaining data freshness, ensuring consistency, and improving efficiency in data handling. This article will explore the integration between data lakes and CDC, their benefits, implementation methods, key technologies and tools involved, best practices, and how to choose the right tools for your needs.
CDC architecture pattern
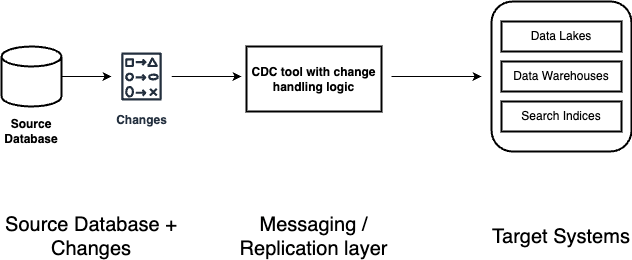
Common CDC Components
Change Detection
Timestamp-based / Query-based:
This method relies on table schemas to include a column to indicate when it was previously modified, i.e. LAST_UPDATED etc. Whenever the source system is updated, the LAST_UPDATED column should be designed to get updated with the current timestamp. This column can then be queried by consumer applications to get the records, and process the records that have been previously updated.
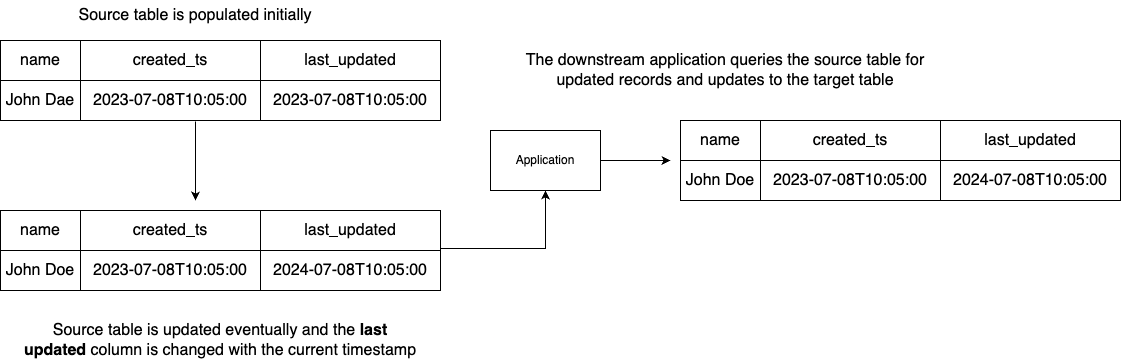
Pros:
- Its simple to implement and use
Cons:
- If source applications did not have the timestamp columns, the database design needs to be changed to include it
- Only supports soft deletes and not DELETE operations in the source table. This is because, once a DELETE operation is performed on the source database the record is removed and the consumer applications cannot track it automatically without the help of a custom log table or an audit trail.
- As there is no metadata to track, schema evolution scenarios require custom implementations to track the source database schema changes and update the target database schema appropriately. This is complex and hard to implement.
Trigger-based:
In a trigger-based CDC design, database triggers are used to detect changes in the data and are used to update target tables accordingly. This method involves having trigger functions automatically executed to capture and store any changes from the source table in the target table; these target tables are commonly referred to as shadow tables or change tables. For example, in this method, stored procedures are triggered when there are specific events in the source database, such as INSERTs, UPDATEs, DELETEs.
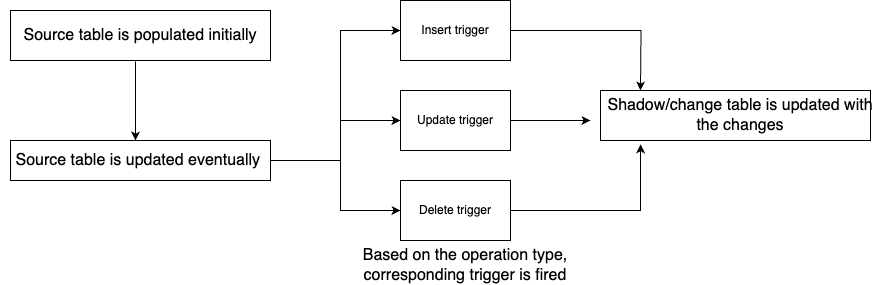
Pros:
- Simple to implement
- Triggers are supported natively by most database engines
Cons:
- Maintenance overhead - requires maintaining separate trigger for each operation in each table
- Performance overhead - in a highly concurrent database, addition of these triggers may significantly impact performance
- Trigger-based CDC does not inherently provide mechanisms for informing downstream applications about schema changes, complicating consumer-side adaptations.
Log-based:
Databases maintain transaction logs, a file that records all transactions and database modifications made by each transaction. By reading this log, CDC tools can identify what data has been changed, when it changed and the type of change. Because this method reads changes directly from the database transaction log, ensuring low-latency and minimal impact on database performance.
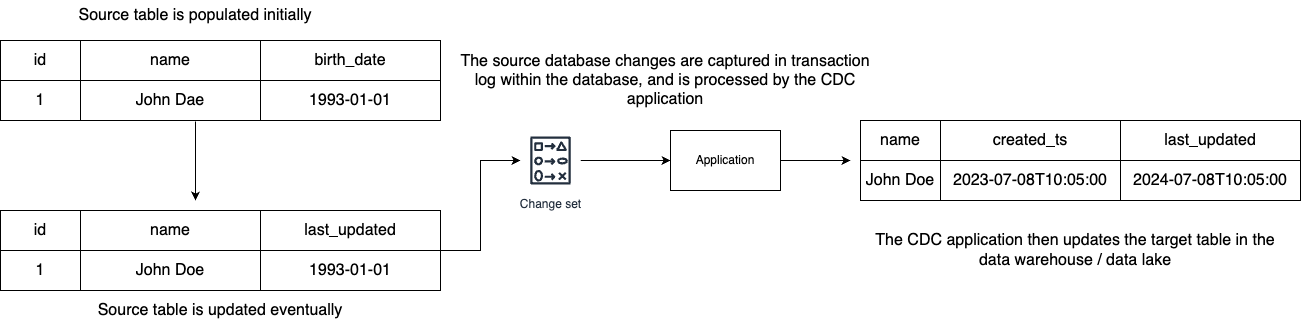
Pros:
- Supports all kinds of database transactions i.e. INSERTs, UPDATEs, DELETEs
- Minimal performance impact on the source/operational databases
- No schema changes required in source databases
- With a table format support, i.e. Apache Hudi, schema evolution can be supported
Cons:
- No standardization in publishing the transactional logs between databases - this results in complex design and development overhead to implement support for different database vendors
Data Extraction
Once changes are detected, the CDC system extracts the relevant data. This includes the type of operation (insert, update, delete), the affected rows, and the before-and-after state of the data if applicable.
Data Transformation
Extracted data often needs to be transformed before it can be used. This might include converting data formats, applying business rules, or enriching the data with additional context.
Data Loading
The transformed data is then loaded into the target system. This could be another database, a data warehouse, a data lake, or a real-time analytics platform. The loading process ensures that the target system reflects the latest state of the source database.
Why Combine CDC with Data Lakes?
Flexibility
In general, data lakes offer more flexibility at a lower cost, because of its tendency to support storing any type of data i.e. unstructured, semi-structured and structured data while data warehouses typically only support structured and in some cases semi-structured. This flexibility allows users to maintain a single source of truth and access the same dataset from different query engines. For example, the dataset stored in S3, can be queried using Redshift Spectrum and Amazon Athena.
Cost-effective
Data lakes, when compared to data warehouses, are generally cheaper in terms of storage costs as the volume grows in time. This allows users to implement a medallion architecture which involves storing a huge volume of data in three different levels i.e. bronze, silver and gold layer tables. Over time, data lake users typically implement tiered storage which further reduces storage cost by moving infrequently accessed data to colder storage systems. In a traditional data warehouse implementation, storage costs will be higher to maintain different levels of data and will continue growing as the source database grows.
Streamlined ETL Processes
CDC simplifies the Extract, Transform, Load (ETL) processes by continuously capturing and applying changes to the data lake. This streamlining reduces the complexity and resource intensity of traditional ETL operations, often involving bulk data transfers and significant processing overhead. By only dealing with data changes, CDC makes the process more efficient and reduces the load on source systems.
For organizations using multiple ingestion pipelines, for example a combination of CDC pipelines, ERP data ingestion, IOT sensor data, having a common storage layer may simplify data processing while giving you the opportunity to build unified tables combining data from different sources.
Designing a CDC Architecture
For organizations with specific needs or unique data environments, developing custom CDC solutions is a common practice, especially with open source tools/frameworks. These solutions offer flexibility and can be tailored to meet the exact requirements of the business. However, developing custom CDC solutions requires significant expertise and resources, making it a viable option for organizations with complex data needs. Examples include Debezium/Airbyte combined Apache Kafka.
Solution:
Apache Hudi is an open-source framework designed to streamline incremental data processing and data pipeline development. It efficiently handles business requirements such as data lifecycle management and enhances data quality. Starting with Hudi 0.13.0, the CDC feature was introduced natively, allowing logging before and after images of the changed records, along with the associated write operation type.
This enables users to
- Perform record-level insert, update, and delete for privacy regulations and simplified pipelines – for privacy regulations like GDPR and CCPA, companies need to perform record-level updates and deletions to comply with individuals' rights such as the "right to be forgotten" or consent changes. Without support for record-level updates/deletes this required custom solutions to track individual changes and rewrite large data sets for minor updates. With Apache Hudi, you can use familiar operations (insert, update, upsert, delete), and Hudi will track transactions and make granular changes in the data lake, simplifying your data pipelines.
- Simplified and efficient file management and near real-time data access – Streaming IoT and ingestion pipelines need to handle data insertion and update events without creating performance issues due to numerous small files. Hudi automatically tracks changes and merges files to maintain optimal sizes, eliminating the need for custom solutions to manage and rewrite small files.
- Simplify CDC data pipeline development – meaning users can store data in the data lake using open storage formats, while integrations with Presto, Apache Hive, Apache Spark, and various data catalogs give you near real-time access to updated data using familiar tools.
Revised architecture:
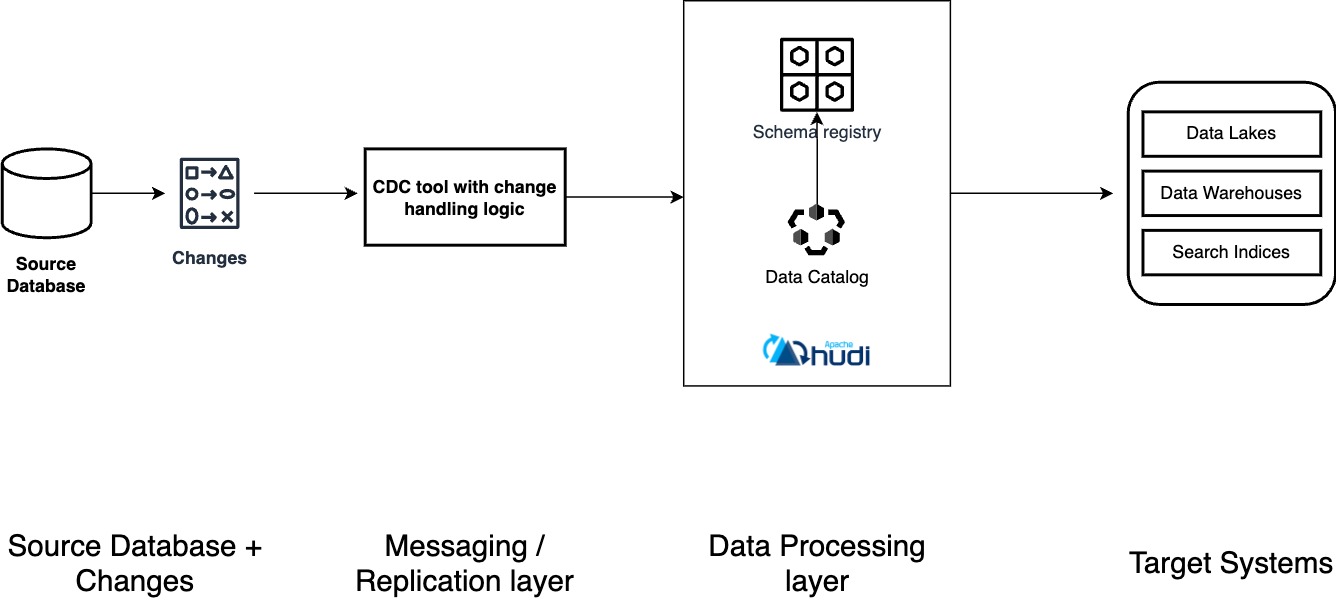
In this architecture, with the addition of the data processing layer, we have added two important components
- A data catalog – acting as a metadata repository for all your data assets across various data sources. This component is updated by the writer i.e. Spark/Flink and is used by the readers i.e. Presto/Trino. Common examples include AWS Glue Catalog, Hive Metastore and Unity Catalog.
- A schema registry – acting centralized repository for managing and validating schemas. It decouples schemas from producers and consumers, which allows applications to serialize and deserialize messages. Schema registry is also important to ensure data quality. Common examples include, Confluent schema registry, Apicurio schema registry and Glue schema registry.
- Apache Hudi – acting as a platform used in conjunction with Spark/Flink which refers to the schema registry and writes to the data lake and simultaneously catalogs the data to the data catalog.
The tables written by Spark/Flink + Hudi can now be queried from popular query engines such as Presto, Trino, Amazon Redshift, and Spark SQL.
Implementation Blogs/Guides
Over time, the Apache Hudi community has written great step-by-step blogs/guides to help implement Change Data Capture architectures. Some of these blogs can be referred to here.
Conclusion
Combining data lakes with Change Data Capture (CDC) techniques offers a powerful solution for addressing the challenges associated with maintaining data freshness, consistency, and efficiency in ETL pipelines.
Several methods exist for implementing CDC, including timestamp-based, trigger-based, and log-based approaches, each with its own advantages and drawbacks. Log-based CDC, in particular, stands out for its minimal performance impact on source databases and support for various transactions, though it requires handling different database vendors' transaction log formats.
Using tools like Apache Hudi can significantly enhance the CDC process by streamlining incremental data processing and data pipeline development. Hudi provides efficient storage management, supports record-level operations for privacy regulations, and offers near real-time access to data. It also simplifies the management of streaming data and ingestion pipelines by automatically tracking changes and optimizing file sizes, thereby reducing the need for custom solutions.