What is a Data Lakehouse & How does it Work?
A data lakehouse is a hybrid data architecture that combines the best attributes of data warehouses and data lakes to address their respective limitations. This innovative approach to data management brings the transactional capabilities of data warehouses to cloud-based data lakes, offering scalability at lower costs.
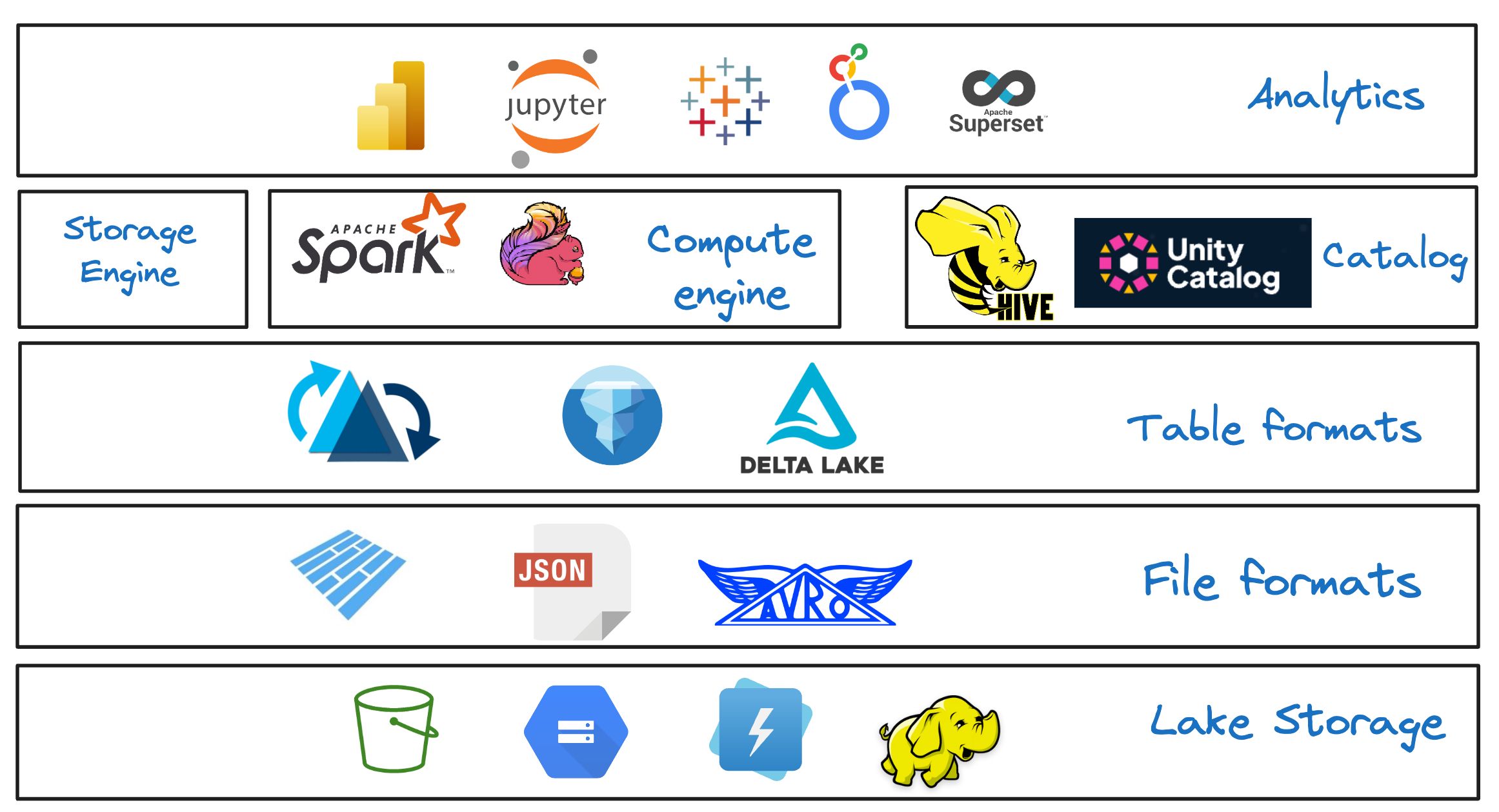
Figure: Data Lakehouse Architecture
The lakehouse architecture supports the management of various data types, such as structured, semi-structured, and unstructured, and caters to a wide range of use cases, including business intelligence, machine learning, and real-time streaming. This flexibility enables businesses to move away from the traditional two-tier architecture—using warehouses for relational workloads and data lakes for machine learning and advanced analytics. As a result, organizations can reduce operational costs and streamline their data strategies by working on a single data store.
The Evolution of Data Storage Solutions: How did we go from Warehouses to Lakes to Lakehouses?
Historically, organizations have been investing in building centralized and scalable data architectures to enable more data access and to support different types of analytical workloads. As demand for these workloads has grown, data architectures have evolved to address the complex needs of modern data processing and storage.
Data warehouses were among the first to serve as centralized repositories for structured workloads, allowing organizations to derive historical insights from disparate data sources. However, they also introduce challenges, including proprietary storage formats that can result in lock-in issues, and limited support for analytical workloads, particularly with unstructured data like machine learning.
Data lakes emerged as the next generation of analytics architectures, enabling organizations to scale storage and compute independently, thereby optimizing resources and enhancing cost efficiency. They support storing all types of data—structured, semi-structured, and unstructured—in low-cost storage systems using open file formats like Apache Parquet and Apache ORC. Although data lakes offer flexibility with their schema-on-read approach, they lack transactional capabilities (ACID characteristics) and often face challenges related to data quality and governance.
The challenges presented by these two data management approaches led to the development of a new architecture called data lakehouse. A lakehouse brings the transactional capabilities of database management systems (DBMS) to scalable data lakes, enabling running various types of workloads on open storage formats.
Introducing: Data Lakehouses
A data lakehouse combines the reliability and performance of data warehouses with the scalability and cost-effectiveness of data lakes. This combined approach enables features such as time-travel, indexing, schema evolution, and performance optimization capabilities on openly accessible formats.
Specifically, a lakehouse architecture is characterized by the following attributes.
-
Open Data Architecture: A lakehouse stores data in open storage formats. This allows various analytical workloads to be run by different engines (from multiple vendors) on the same data, preventing lock-in to proprietary formats.
-
Support for Varied Data Types & Workloads: Data lakehouses accommodate a diverse range of data types—including structured, semi-structured, and unstructured—and are therefore equipped to handle various analytical workloads, such as business intelligence, machine learning, and real-time analytics.
-
Transactional support: Data lakehouses enhance reliability and consistency by providing ACID guarantees in transactions, such as INSERT or UPDATE, akin to those in an RDBMS-OLAP system. This ensures safe, concurrent reads and writes.
-
Less data copies: A data lakehouse minimizes data duplication since the compute engine can directly access data from open storage formats.
-
Schema management: Data lakehouses ensure that a specific schema is adhered to when writing new data into the storage. They also facilitate schema evolution over time without the need to rewrite the entire table, thus reducing storage and operational costs.
-
Data Quality and Governance: Lakehouses ensure data integrity and incorporate robust governance and auditing mechanisms. These features uphold high data quality standards, facilitate regulatory compliance (such as GDPR), and enable secure data management practices.
A data lakehouse architecture consists of six technical components that are modular, offering the flexibility to select and combine the best technologies based on specific requirements.
-
Lake Storage: The storage is where files from various operational systems land after ingestion through ETL/ELT processes. Cloud object stores such as Amazon S3, Azure Blob, and Google Cloud Storage support any type of data and can scale to virtually unlimited volumes. Their cost-effectiveness is a significant advantage over traditional data warehouse storage costs.
-
File Format: File Format: In a lakehouse architecture, file formats like Apache Parquet or ORC store the actual raw data on object storage. These open formats enable multiple engines to consume the data for various workloads. Being typically column-oriented, they offer significant advantages in data reading.
-
Table Format: A key component of a lakehouse architecture is the table format, which is open in nature and acts as a metadata layer above file formats like Apache Parquet. This layer abstracts the complexity of the physical data structure by defining a schema on top of immutable data files. It allows different engines to concurrently read and write on the same dataset, supporting ACID-based transactions. Table formats like Apache Hudi, Apache Iceberg, and Delta Lake bring essential features such as schema evolution, partitioning, and time travel.
-
Storage Engine: The storage engine in a lakehouse orchestrates essential data management tasks including clustering, compaction, cleaning, and indexing to streamline data organization in cloud object storages for improved query performance. Both open source and proprietary lakehouse platforms are equipped with native storage engines that enhance these capabilities, optimizing the storage layout effectively.
-
Catalog: Often referred to as a metastore, the catalog is a crucial component of the lakehouse architecture that facilitates efficient search and discovery by tracking all tables and their metadata. It records table names, schemas (column names and types), and references to each table's specific metadata (table format).
-
Compute Engine: The compute engine in a lakehouse processes data and ensures efficient read and write performance. It interacts with data using read and write APIs provided by table formats. Compute engines are tailored to specific workloads, with options such as Trino and Presto for low-latency ad hoc SQL, Apache Flink for streaming, and Apache Spark for machine learning tasks.
Advantages of Data Lakehouses
A lakehouse architecture, characterized by its open data storage formats and cost-effective options, offers numerous advantages. Here are some key benefits:
| Attributes | Description |
|---|---|
| Open Data Foundation | Data in a lakehouse is stored in open file formats like Apache Parquet and table formats such as Apache Hudi, Iceberg, or Delta Lake. This allows various engines to concurrently work on the same data, enhancing accessibility and compatibility. |
| Unified Data Platform | Lakehouses combine the functionalities of data warehouses and lakes into a single platform, supporting both types of workloads efficiently. This integration simplifies data management and accelerates analytics processes. |
| Centralized Data Repository for Diverse Data Types | A lakehouse architecture can store and manage structured, semi-structured, and unstructured data, serving different types of analytical workloads. |
| Cost Efficiency | Using low-cost cloud storage options and reducing the need for managing multiple systems significantly lowers overall engineering and ETL costs. |
| Performance and Scalability | Lakehouses allow independent scaling of storage and compute resources, which can be adjusted based on demand, ensuring high concurrency and cost-effective scalability. |
| Enhanced Query Performance | Lakehouse’s storage engine component optimizes data layout in formats like Parquet and ORC to offer high performance comparable to traditional data warehouses, on large datasets. |
| Data Governance and Management | Lakehouses centralize data storage and management, streamlining the deployment of governance policies and security measures. This consolidation makes it easier to monitor, control, and secure data. |
| Improved Data Quality and Consistency | Lakehouses enforce strict schema adherence and provide transactional consistency, which minimizes write job failures and ensures data reliability. |
| Support for various Compute Engines | A lakehouse architecture supports SQL-based engines, ML tools, and streaming engines, making it versatile for handling diverse analytical demands on a single data store. |
Implementing a Data Lakehouse
The modular and open design of data lakehouse architecture allows for selection of best-of-breed engines and tools according to specific requirements. Therefore, the implementation of a lakehouse can vary based on the use case. This section outlines common considerations for implementing a lakehouse architecture. Given the variability in complexity (workloads, security, etc.) and tool stack, large-scale implementations may require tailored approaches.
Data Ingestion
The first phase in a lakehouse architecture involves extracting and loading data into a cloud-based low cost data lake such as Amazon S3, where it lands in its raw format (Parquet files). This approach utilizes the "schema-on-read" method, which means there's no need to process data immediately upon arrival. Once the data is in place, transformation logic can be applied to shift towards a "schema-on-write" setup, which organizes the data for specific analytical workloads such as ad hoc SQL queries or machine learning.
Metadata & Transactional Layer
To enable transactional capabilities, Apache Hudi, Apache Iceberg or Delta Lake can be chosen as the table format. They provide a robust metadata layer with a table-like schema atop the physical data files in the object store. Together with the storage engine, they bring in data optimization strategies to maintain fast and efficient query performance. The metadata layer also facilitates capabilities such as time-travel querying, version rollbacks, and schema evolution akin to a traditional data warehouse.
Processing Layer
The compute engine is a crucial component in a lakehouse architecture that processes the data files managed by the table format. Depending on the specific workload, SQL-based distributed query engines like Presto or Trino can be used for ad-hoc interactive analytics, or Apache Spark for distributed ETL tasks. Lakehouse table formats provide several optimizations such as indexes, and statistics, along with data layout optimizations including clustering, compaction, and Z-ordering. These enable the compute engines to achieve performance comparable to traditional data warehouses.
Catalog Layer
The catalog layer in a lakehouse architecture is responsible for tracking all tables and maintaining essential metadata. It ensures that data is easily accessible to query engines, supporting efficient data management, accessibility, and governance. Options for catalog implementation include Unity Catalog, AWS Glue, Hive Metastore, and file system-based ones. This layer plays a key role in upholding data quality and governance standards by establishing policies for data validation, security measures, and compliance protocols.
Use Cases
A Lakehouse architecture is used for a multitude of use cases. Here are some prominent examples.
Unified Batch & Streaming
Traditional analytics architectures often separate real-time and batch storage, using specialized data stores for real-time insights and data lakes for delayed batch processing. Lakehouse platforms bridge this divide by introducing streaming capabilities to data lakes, allowing data ingestion within minutes and the creation of faster incremental pipelines. This integration reduces data freshness issues and eliminates the need for significant upfront infrastructure investments, making it a scalable and cost-effective solution for complex analytics.
Diverse Analytical Workloads
Lakehouse architecture supports various data types—structured, semi-structured, and unstructured—enabling users to run both BI and ML workloads on the same dataset without the need for costly data duplication or movement. This unified approach allows data scientists and analysts to easily access and manipulate data for training ML models, deploying AI algorithms, and conducting in-depth BI analysis. By eliminating the need to create and maintain separate BI extracts and cubes, lakehouses reduce both storage and compute costs while maintaining a simple, self-service model for end-users. As a result, organizations can streamline their data operations and enhance analytical flexibility, making it easier to derive insights across different domains.
Cost-Effective Data Management
Lakehouses leverage the low-cost storage of cloud-based data lakes while providing sophisticated data management and querying capabilities similar to data warehouses. This dual advantage makes it an economical choice for startups and enterprises alike that need to manage costs without compromising on analytics capabilities. Additionally, the open, unified architecture of a lakehouse eliminates non-monetary costs, such as running and maintaining ETL pipelines and creating multiple data copies, further streamlining operations.
Real World Examples
ByteDance, Notion and Halodoc are some of the examples of how lakehouse architecture is being adopted in the industry. ByteDance has built an exabyte-level data lakehouse using Apache Hudi to enhance their recommendation systems. The implementation of Hudi's Merge-on-read (MOR) tables, indexing, and Multi-Version Concurrency Control (MVCC) features allow ByteDance to provide real-time machine learning capabilities, providing instant and relevant recommendations.
Notion scaled its data infrastructure by building an in-house lakehouse to handle rapid data growth and meet product demands, especially for Notion AI. The architecture uses S3 for storage, Kafka and Debezium for data ingestion, and Apache Hudi for efficient data management. This setup resulted in significant cost savings, faster data ingestion, and enhanced capabilities for analytics and product development.
Similarly, Halodoc's adoption of a lakehouse architecture allows them to enhance healthcare services by enabling real-time processing and analytics. This architecture helps Halodoc tackle challenges associated with managing vast healthcare data volumes, thus improving patient care through faster, more accurate decision-making and supporting both batch and stream processing crucial for timely health interventions.
Key Data Lakehouse Technologies
Open Source Solutions
Apache Hudi
Apache Hudi is an open source transactional data lakehouse platform built around a database kernel. It provides table-level abstractions over open file formats like Apache Parquet and ORC thereby delivering core warehouse and database functionalities directly in the data lake and supporting transactional capabilities such as updates and deletes.
Hudi also incorporates critical table services tightly integrated with its database kernel. These services can be run automatically, managing aspects like table bookkeeping, metadata, and storage layouts across both ingested and derived data. These capabilities, combined with specific platform services (ingestion, catalog sync tool, admin CLI, etc.) in Hudi, elevates its role from merely a table format to a comprehensive and robust data lakehouse platform. Apache Hudi has a broad support for various data sources and query engines, such as Apache Spark, Apache Flink, AWS Athena, Presto, Trino and StarRocks.
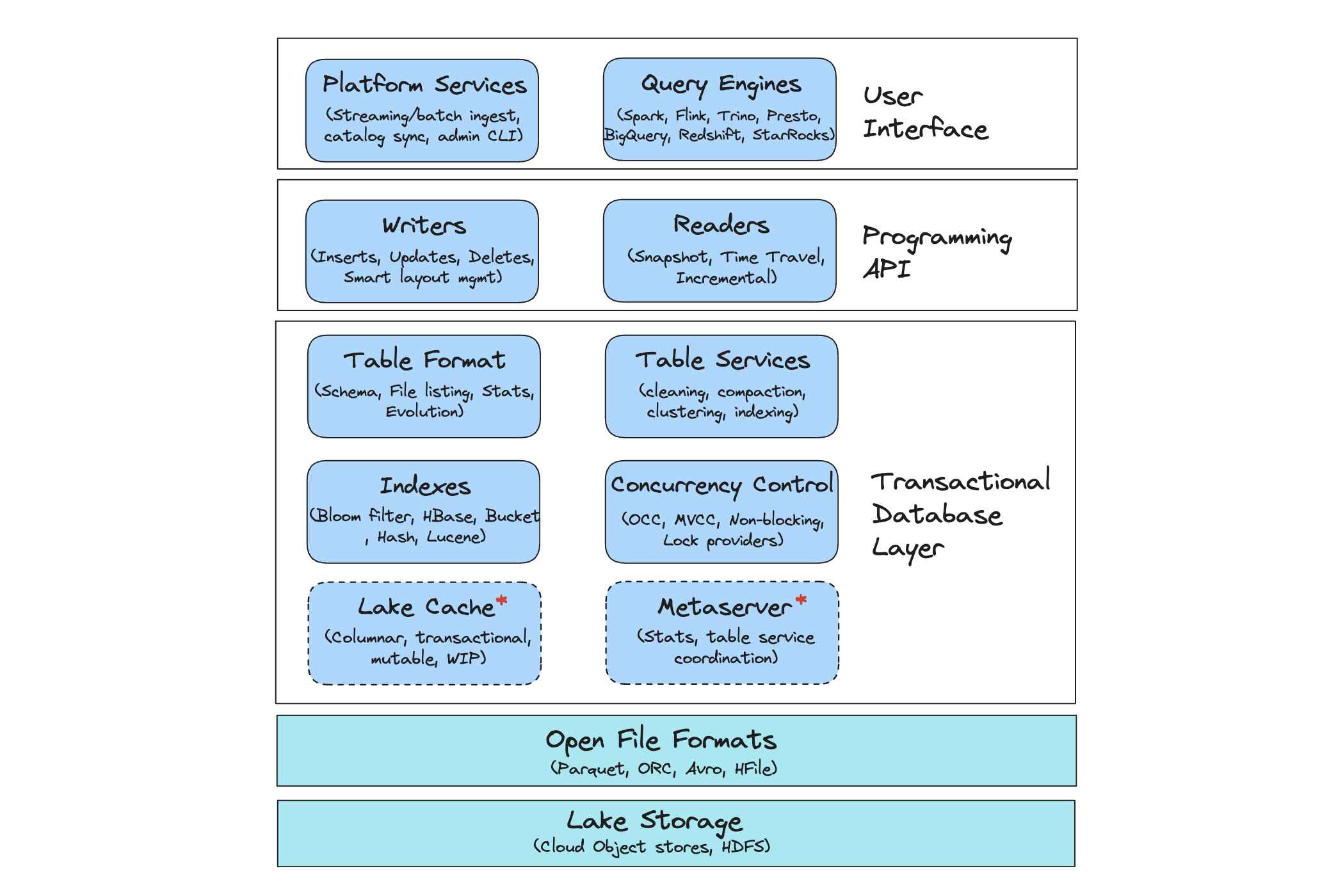
Figure: Apache Hudi Architectural stack
Below are some of the key features of Hudi’s lakehouse platform.
- Mutability Support: Hudi enables quick updates and deletions through an efficient, pluggable indexing mechanism supporting workloads such as streaming, out-of-order data, and data deduplication.
- Incremental Processing: Hudi optimizes for efficiency by enabling incremental processing of new data. This feature allows you to replace traditional batch processing pipelines with more dynamic, incremental streaming, enhancing data ingestion and reducing processing times for analytical workloads.
- ACID Transactions: Hudi brings ACID transactional guarantees to data lakes, offering consistent and atomic writes along with different concurrency control techniques essential for managing longer-running transactions.
- Time Travel: Hudi includes capabilities for querying historical data, allowing users to roll back to previous versions of tables to debug or audit changes.
- Comprehensive Table Management: Hudi brings automated table services that continuously orchestrate clustering, compaction, cleaning, and indexing, ensuring high performance for analytical queries.
- Query Performance Optimization: Hudi introduces a novel multi-modal indexing subsystem that speeds up write transactions and enhances query performance, especially in large or wide tables.
- Schema Evolution and Enforcement: With Hudi, you can adapt the schema of your tables as your data evolves, enhancing pipeline resilience by quickly identifying and preventing potential data integrity issues.
Apache Iceberg
Apache Iceberg is a table format designed for managing large-scale analytical datasets in cloud data lakes, facilitating a lakehouse architecture. Technically, Iceberg serves as a table format specification, providing APIs and libraries that enable compute engines to interact with tables according to this specification. It introduces features essential for data lake workloads, including schema evolution, hidden partitioning, ACID-compliant transactions, and time travel capabilities. These features ensure robust data management, akin to that found in traditional data warehouses.
Delta Lake
Delta Lake is another open source table format that enables building a lakehouse architecture on top of cloud data lakes. By offering an ACID-compliant layer that operates over cloud object stores, Delta Lake addresses the typical performance and consistency issues associated with data lakes. It enables features like schema enforcement and evolution, time travel, efficient metadata handling and DML operations, which are crucial for handling large-scale workloads on data lakes effectively.
Vendor Lakehouse Platforms
Onehouse
Onehouse offers a universal data platform that streamlines data ingestion and transformation into a lakehouse architecture. It eliminates lakehouse table format friction by working seamlessly with Apache Hudi, Apache Iceberg and Delta Lake tables (thanks to Apache XTable). The platform supports continuous data ingestion from diverse sources, including events streams such as Kafka, databases and cloud storage, enabling real-time data updates while ensuring data integrity through automated table optimizations and rigorous data quality measures. Onehouse provides a fully managed ingestion pipeline with serverless autoscaling and cost-efficient infrastructure. With its flexible querying capabilities across multiple engines and formats, Onehouse empowers organizations to efficiently manage and utilize their data.
Databricks
The Databricks Lakehouse Platform unifies data engineering, machine learning, and analytics on a single platform. It combines the reliability, governance, and performance of data warehouses with the scalability, flexibility, and low cost of data lakes. By offering Delta Lake as its foundational storage layer and UniFormat for interoperability between Apache Iceberg and Apache Hudi, the platform supports ACID transactions, scalable metadata handling, and unifies batch and streaming data processing.
Snowflake
The Snowflake Data Cloud provides a unified, fully managed platform for seamless data management and advanced analytics capabilities. It offers near-infinite scalability, robust security, and native support for diverse data types and SQL workloads. Snowflake currently supports Apache Iceberg as the open table format to facilitate a lakehouse architecture. This integration allows users to leverage Iceberg's rich table metadata and Parquet file storage within Snowflake's ecosystem, enabling seamless data handling, multi-table transactions, dynamic data masking, and row-level security, all while using customer-supplied cloud storage.
The Future of Data Lakehouses
The future of data lakehouses is shaped by their truly open data architecture, which meets the ongoing need for flexible, scalable, and cost-effective data management solutions. They offer a unified platform capable of efficiently handling both streaming and batch workloads, supporting a wide array of analytical workloads including BI and ML. With the rapid advancement of artificial intelligence, including generative AI, there is an increasing demand for robust platforms that provide the foundation for building and deploying powerful models. Lakehouse architecture rises to this challenge, offering a solid base for the evolving demands of modern data analytics.
Conclusion
The data lakehouse architecture utilizes an open data foundation to blend the best features of data lakes and warehouses, establishing a versatile platform that effectively handles a range of analytical workloads. This architecture marries cost-effective data management with robust performance, offering a cohesive system for both batch and streaming data processes. By enabling organizations to work on a single data store, this approach not only simplifies management but also equips businesses to swiftly integrate new technologies and adapt to evolving market demands. Additionally, by supporting diverse data types and analytical workloads, the lakehouse framework eliminates the need for a two-tier architecture, which helps save costs and enhances the efficiency of data teams.