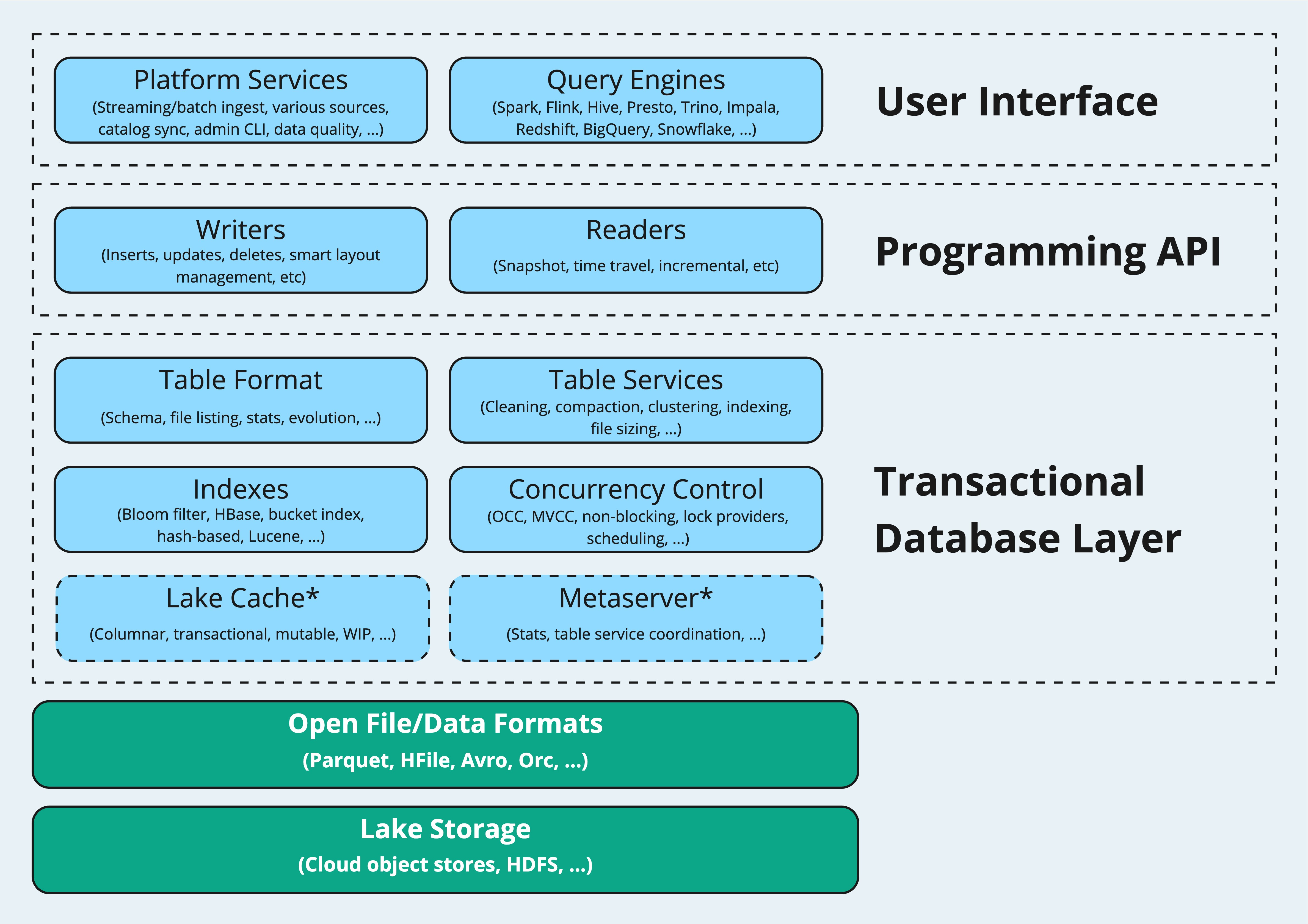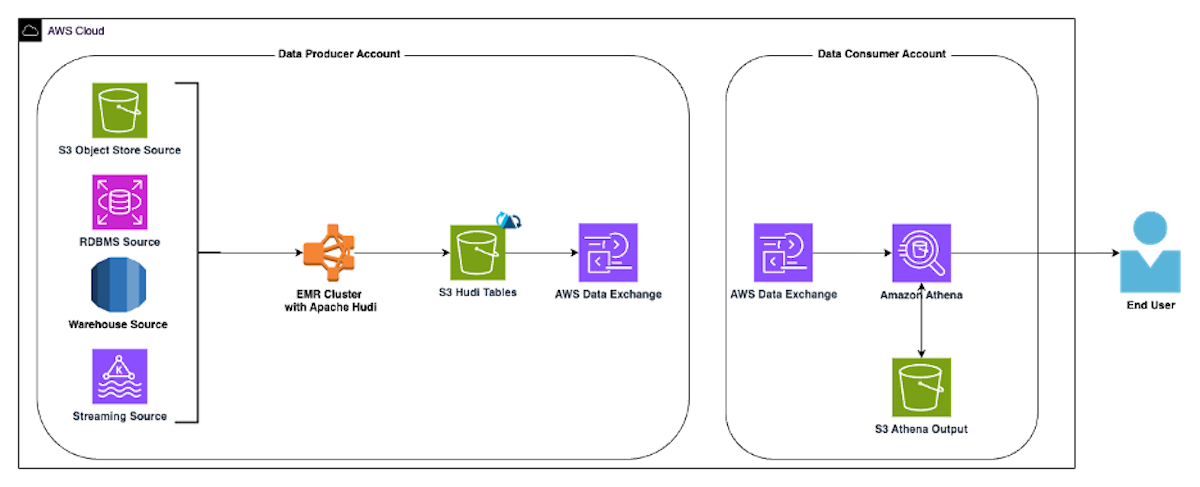
Use AWS Data Exchange to seamlessly share Apache Hudi datasets

Apache Hudi on AWS Glue
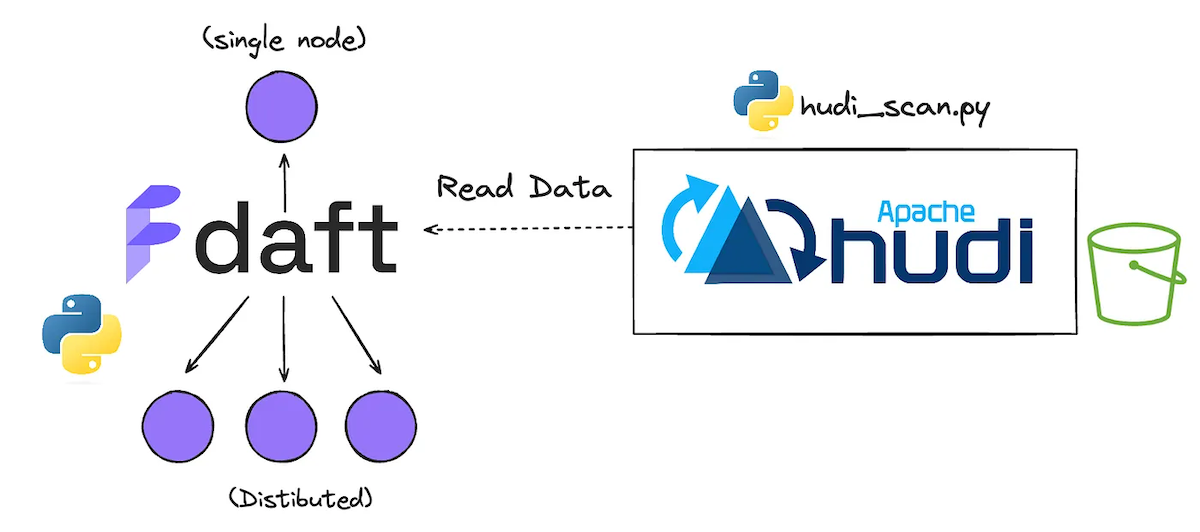
Building Analytical Apps on the Lakehouse using Apache Hudi, Daft & Streamlit

Learn how to read Hudi data with AWS Glue Ray using Daft (No Spark)
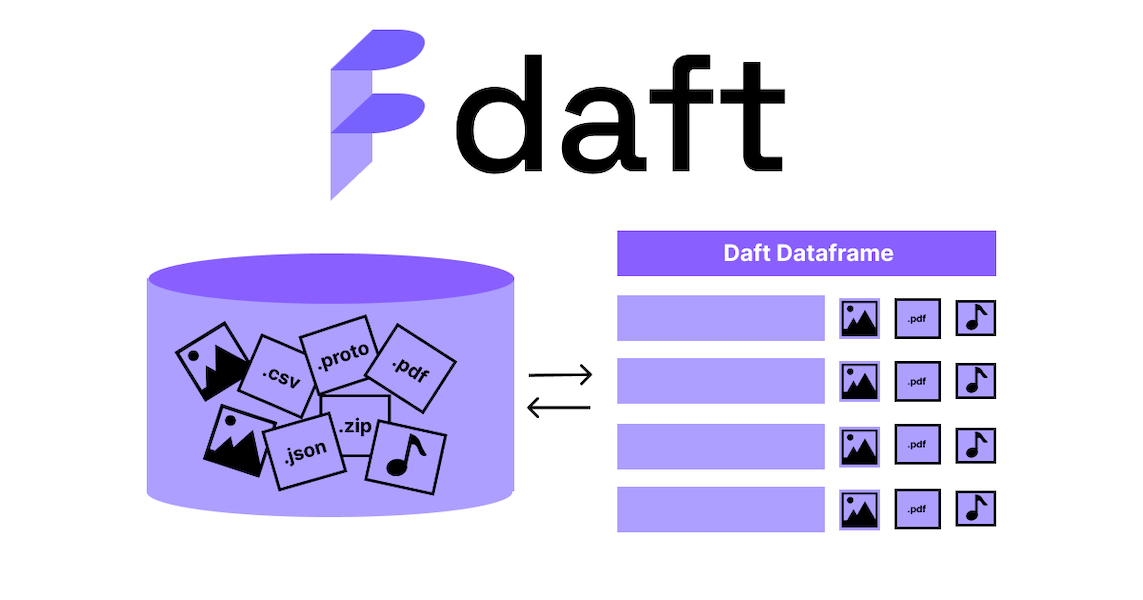
How to Query Apache Hudi Tables with Python Using Daft: A Spark-Free Approach

Apache Hudi vs Apache Iceberg: A Comprehensive Comparison

Understanding Apache Hudi's Consistency Model Part 1
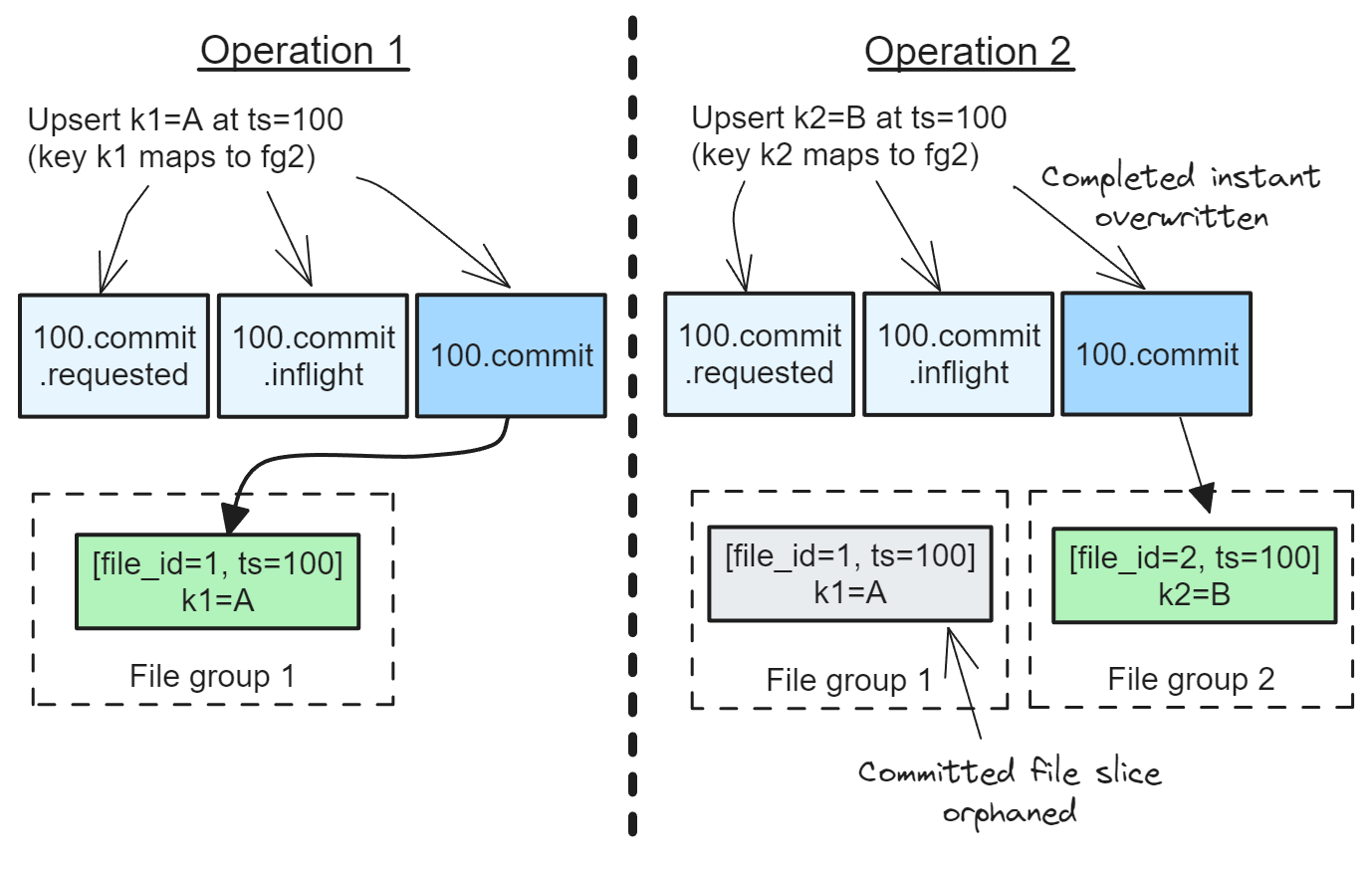
Understanding Apache Hudi's Consistency Model Part 2

Understanding Apache Hudi's Consistency Model Part 3
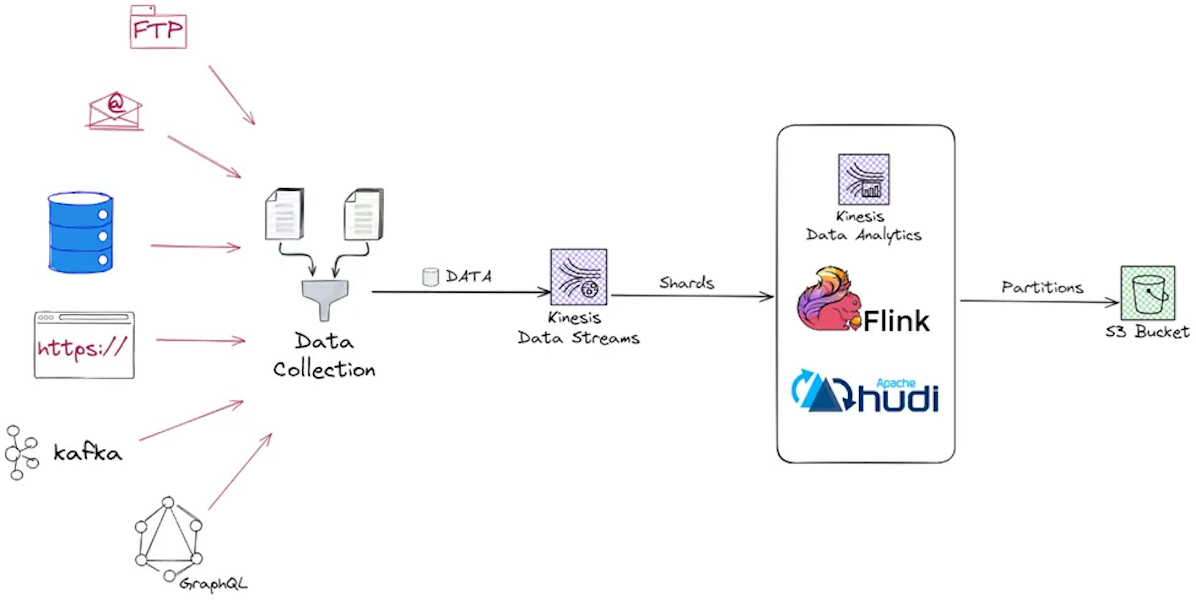
Build Real Time Streaming Pipeline with Kinesis, Apache Flink and Apache Hudi with Hands-on