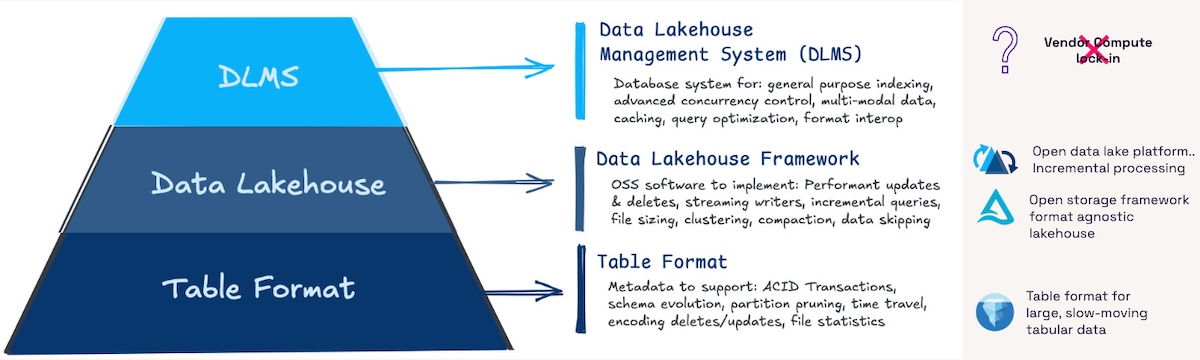
The Architect’s Guide to Open Table Formats and Object StorageDecember 31, 2024 by Brenna Buuckapache icebergdelta lakedata lakehousetable format
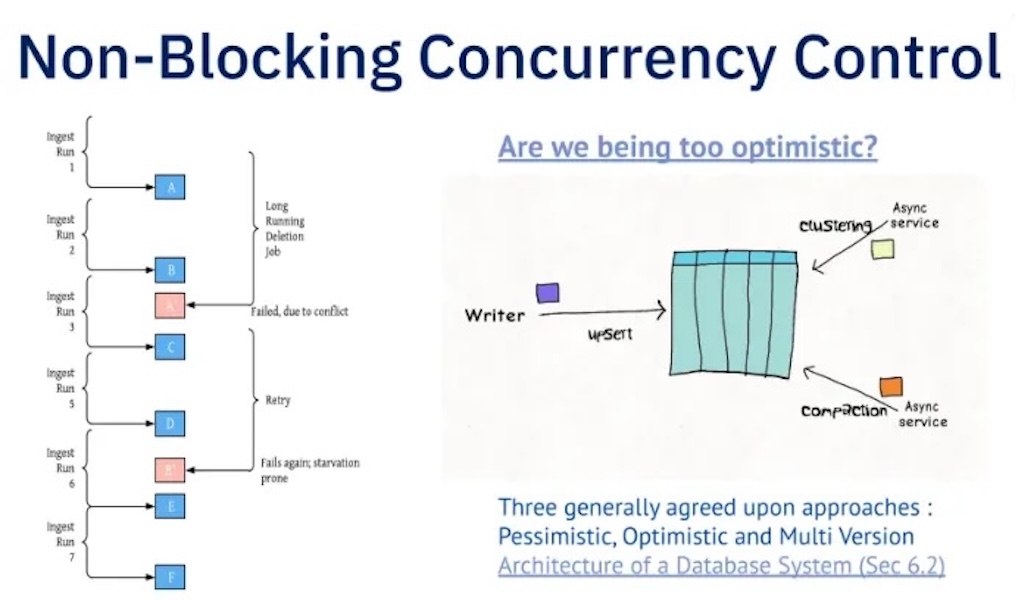
How lakehouse handles concurrent Read and WritesDecember 28, 2024 by Sanjeet Shuklaconcurrency control
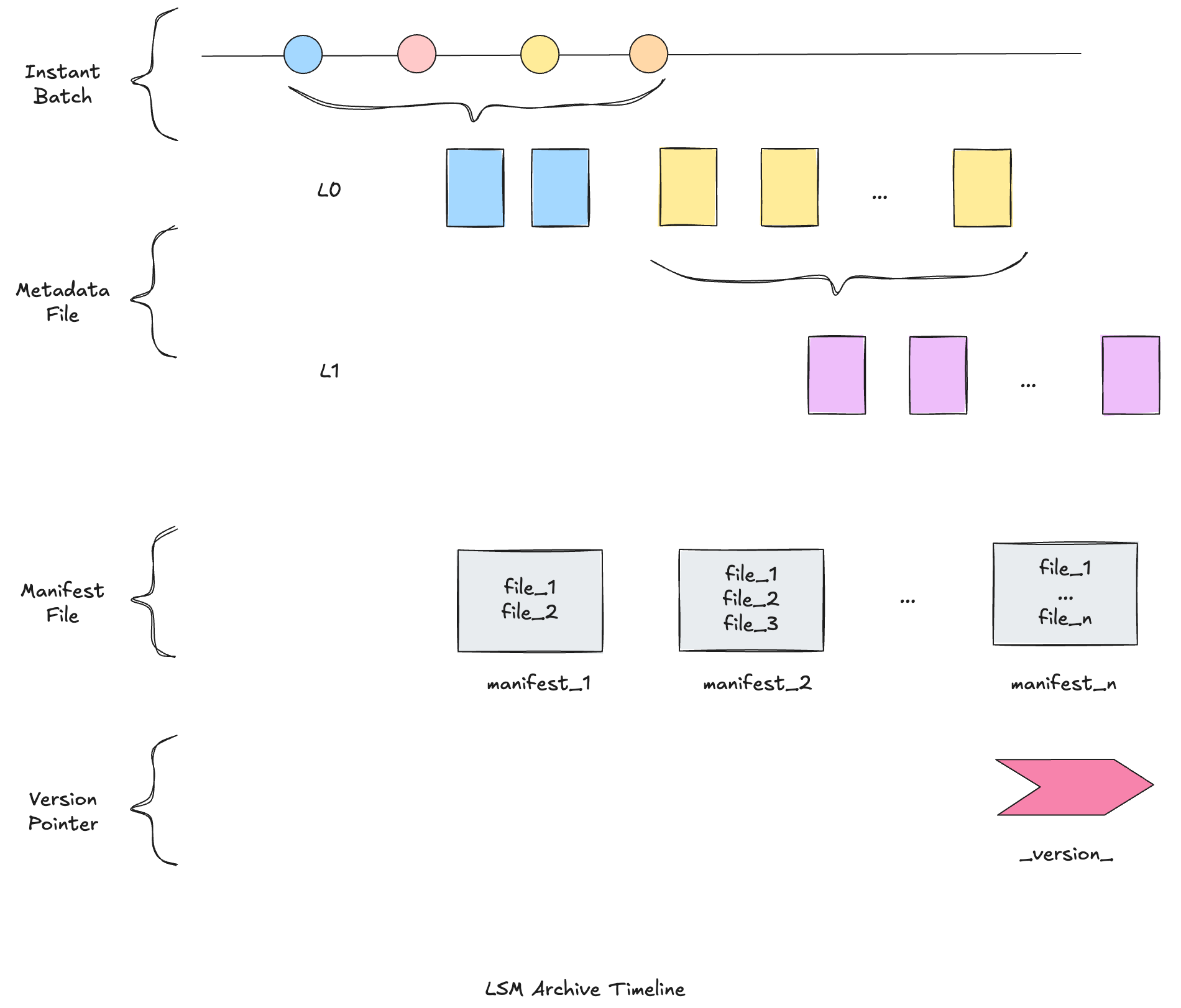
Announcing Apache Hudi 1.0 and the Next Generation of Data LakehousesDecember 16, 2024 by Vinoth Chandarhudi timelinereleasestreamingconcurrency control
Introducing Hudi's Non-blocking Concurrency Control for streaming, high-frequency writesDecember 6, 2024 by Danny Chanstreamingconcurrency control
Use open table format libraries on AWS Glue 5.0 for Apache SparkDecember 4, 2024 by Sotaro Hikita and Noritaka Sekiyamaannouncementapache sparktable formataws
Apache Iceberg vs Hudi: Key Features, Performance & Use CasesDecember 3, 2024 by Dani Pálmaapache icebergcomparisonestuary
Hudi’s Automatic File Sizing Delivers Unmatched PerformanceNovember 19, 2024 by Aditya Goenkadata lakehouse
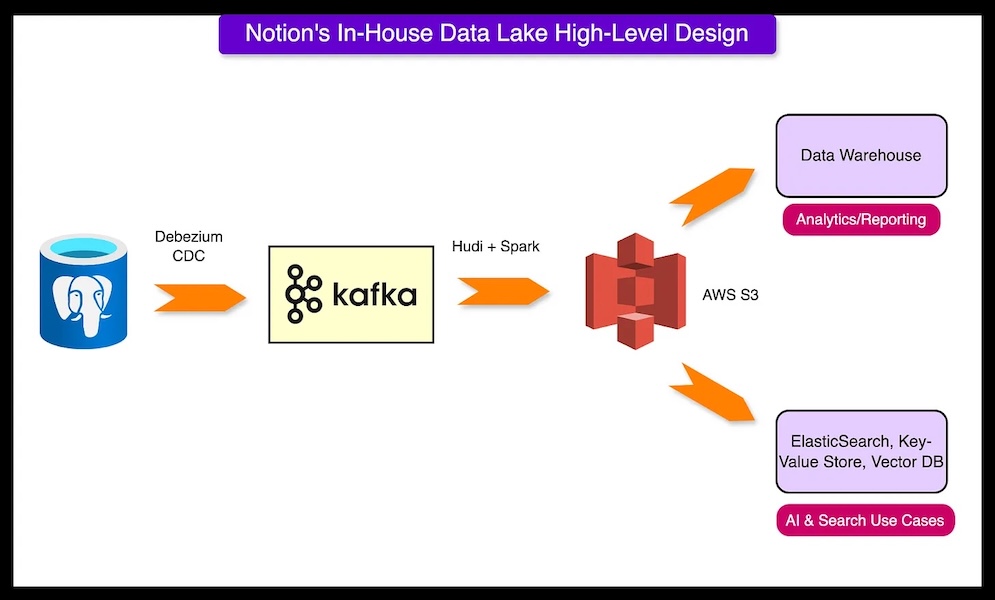
Storing 200 Billion Entities: Notion’s Data Lake ProjectNovember 12, 2024 by ByteByteGodata lakehouse
Understanding COW and MOR in Apache Hudi: Choosing the Right Storage StrategyNovember 12, 2024 by Deepak Nishadcowmor