116 posts tagged with "Apache Hudi"
View All Tags
How to use Apache Hudi with Databricks

Apache Hudi: A Deep Dive with Python Code Examples

Apache Hudi vs. Delta Lake: Choosing the Right Tool for Your Data Lake on AWS
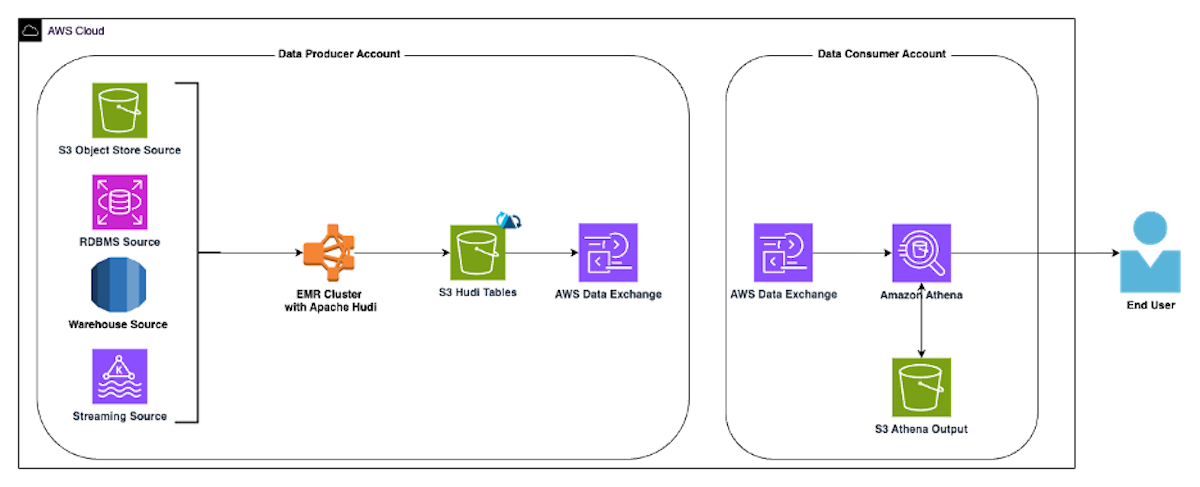
Use AWS Data Exchange to seamlessly share Apache Hudi datasets

Apache Hudi on AWS Glue
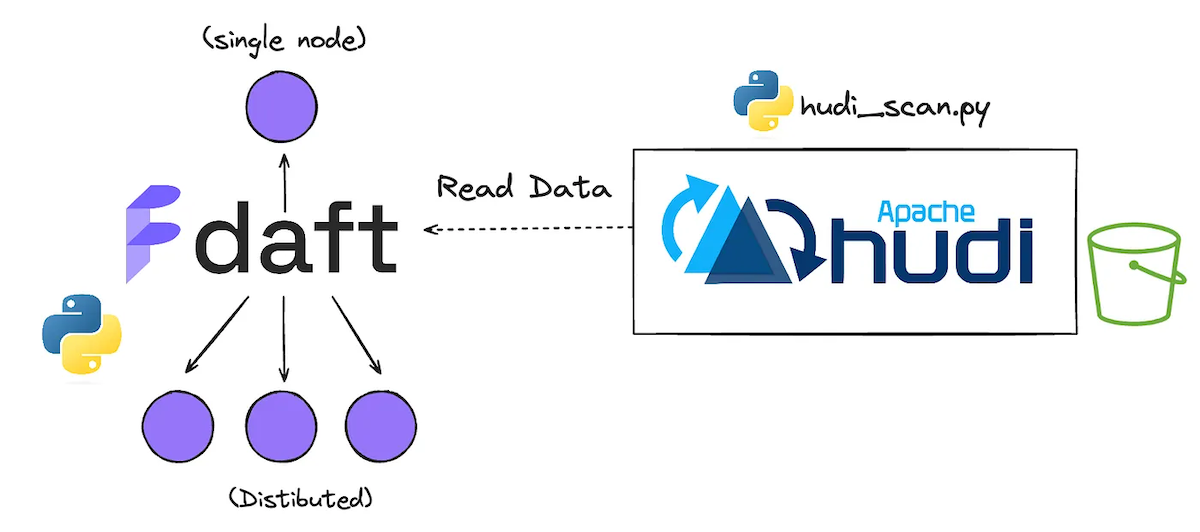
Building Analytical Apps on the Lakehouse using Apache Hudi, Daft & Streamlit

Learn how to read Hudi data with AWS Glue Ray using Daft (No Spark)
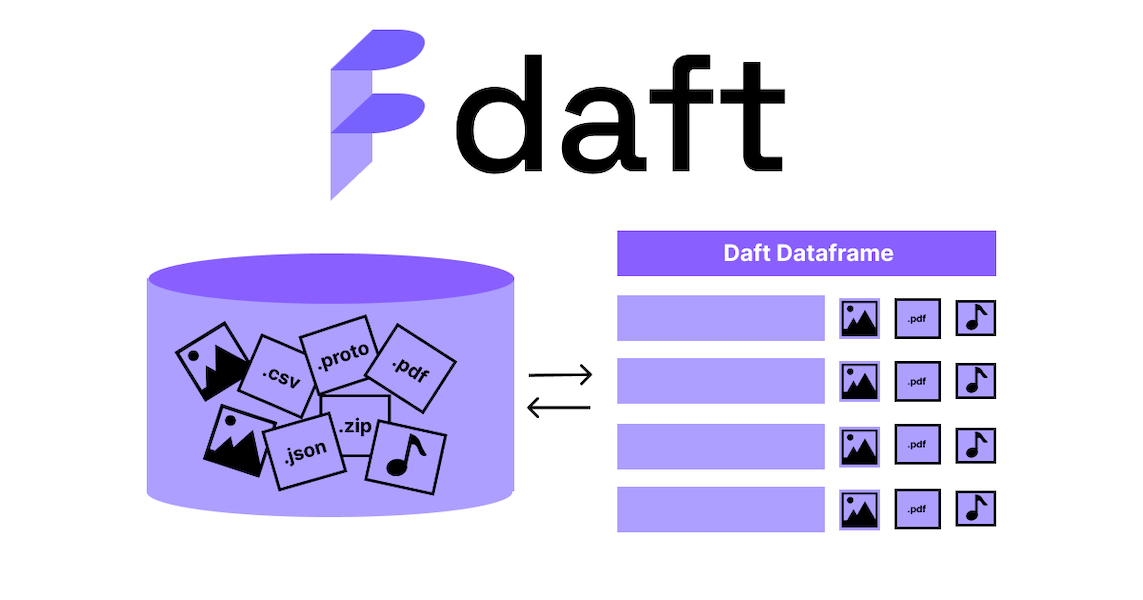
How to Query Apache Hudi Tables with Python Using Daft: A Spark-Free Approach

Apache Hudi vs Apache Iceberg: A Comprehensive Comparison

Understanding Apache Hudi's Consistency Model Part 1

Understanding Apache Hudi's Consistency Model Part 3
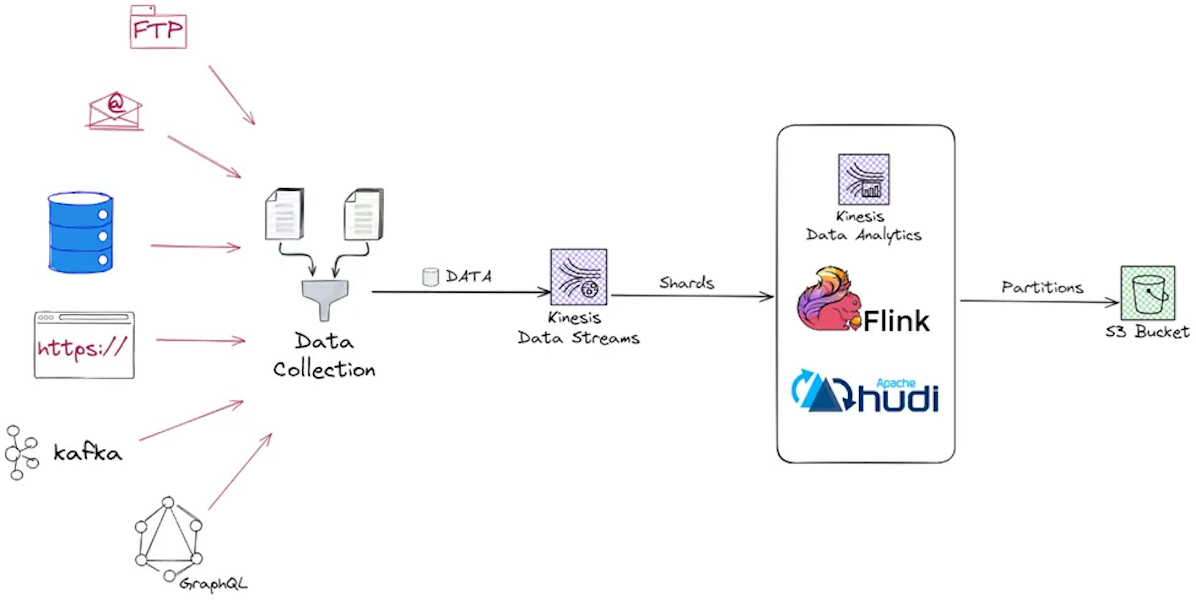
Build Real Time Streaming Pipeline with Kinesis, Apache Flink and Apache Hudi with Hands-on
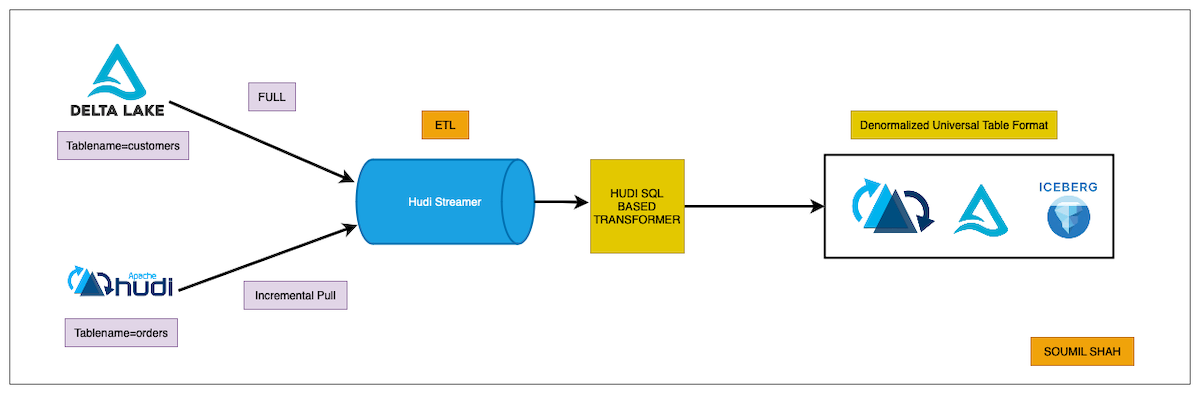
Hands-On Guide: Reading Data from Hudi Tables Incrementally, Joining with Delta Tables using HudiStreamer and SQL-Based Transformer
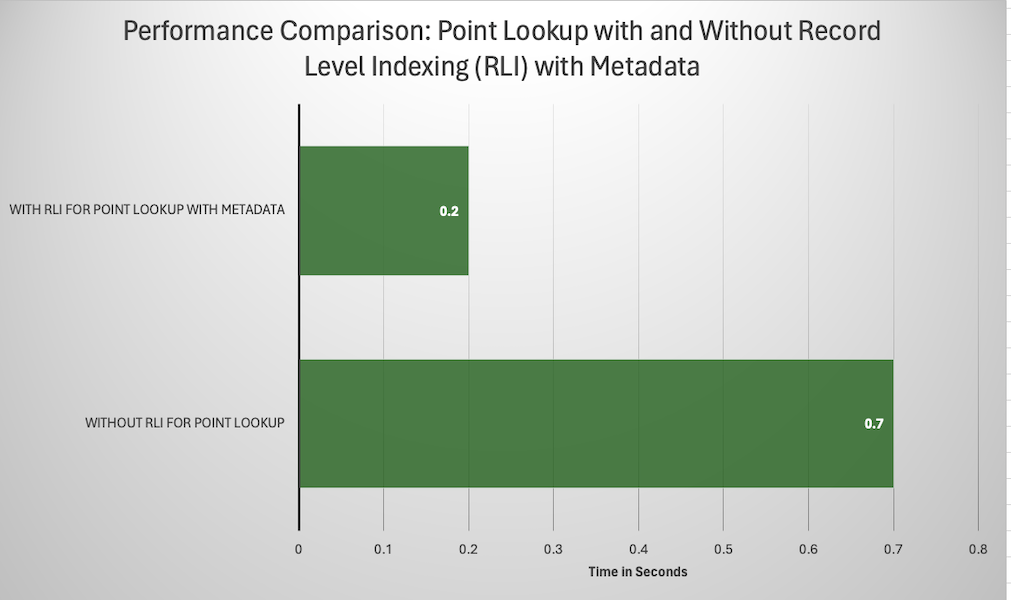
Record Level Indexing in Apache Hudi Delivers 70% Faster Point Lookups

Options on Kafka sink to open table Formats: Apache Iceberg and Apache Hudi

Cost Optimization Strategies for scalable Data Lakehouse

Open Table Formats (part-1): Apache Hudi (Hadoop Upserts Deletes and Incrementals)

Modern Datalakes with Hudi, MinIO, and HMS

Navigating the Future: The Evolutionary Journey of Upstox’s Data Platform
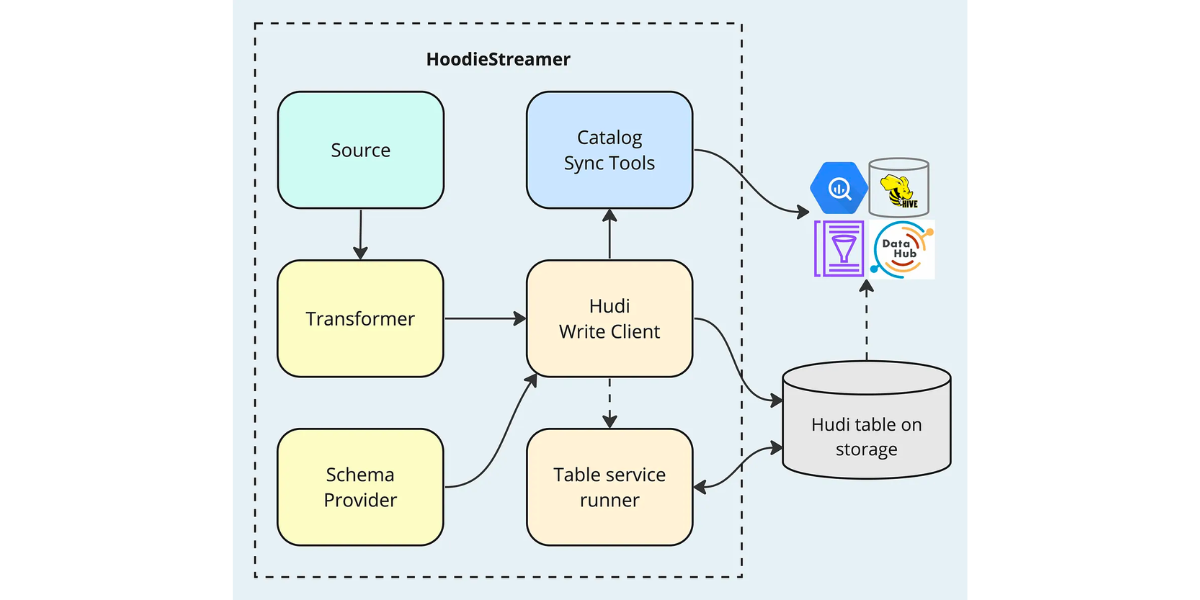
Apache Hudi: From Zero To One (9/10)
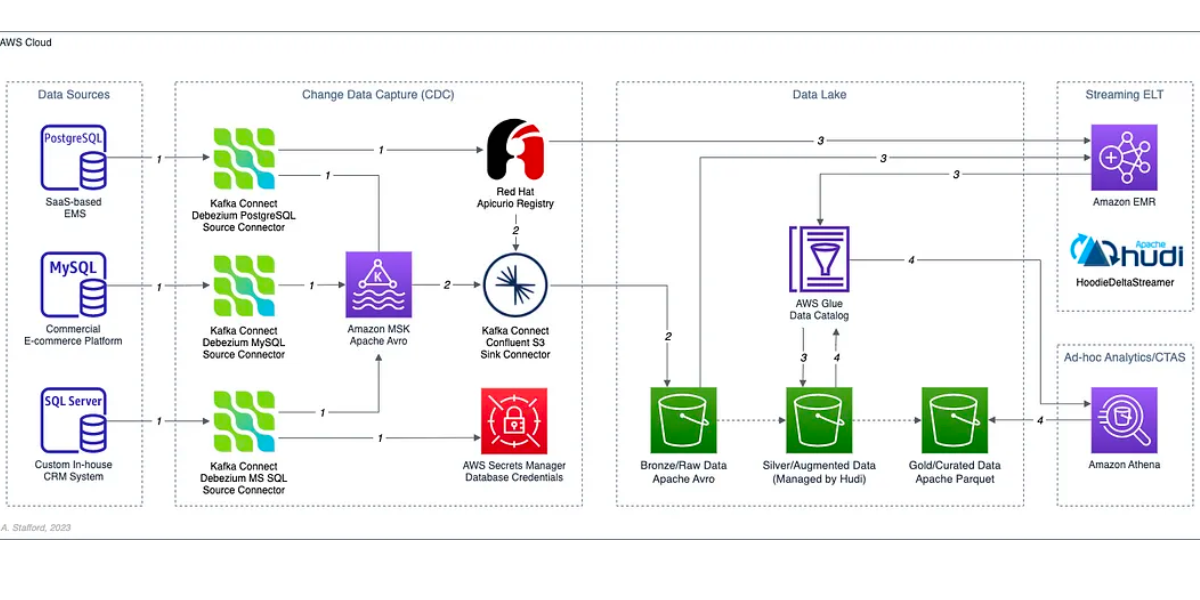
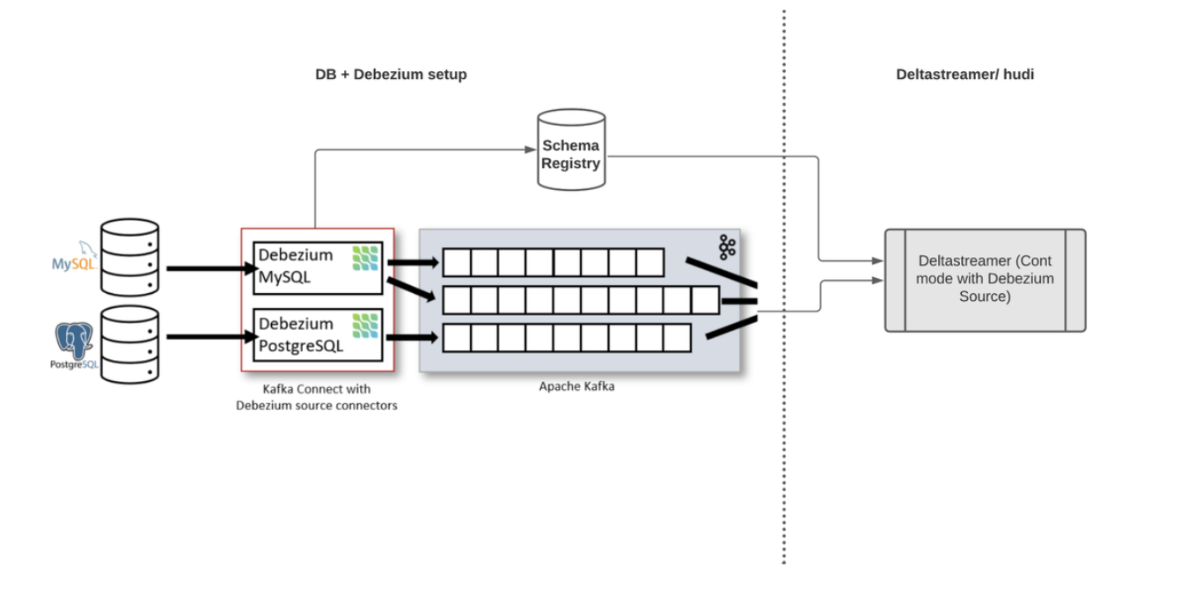
Building Data Lakes on AWS with Kafka Connect, Debezium, Apicurio Registry, and Apache Hudi

Empowering data-driven excellence: How the Bluestone Data Platform embraced data mesh for success

Enabling near real-time data analytics on the data lake

How a POC became a production-ready Hudi data lakehouse through close team collaboration

Building an Open Source Data Lake House with Hudi, Postgres Hive Metastore, Minio, and StarRocks
Combine Transactional Integrity and Data Lake Operations with YugabyteDB and Apache Hudi
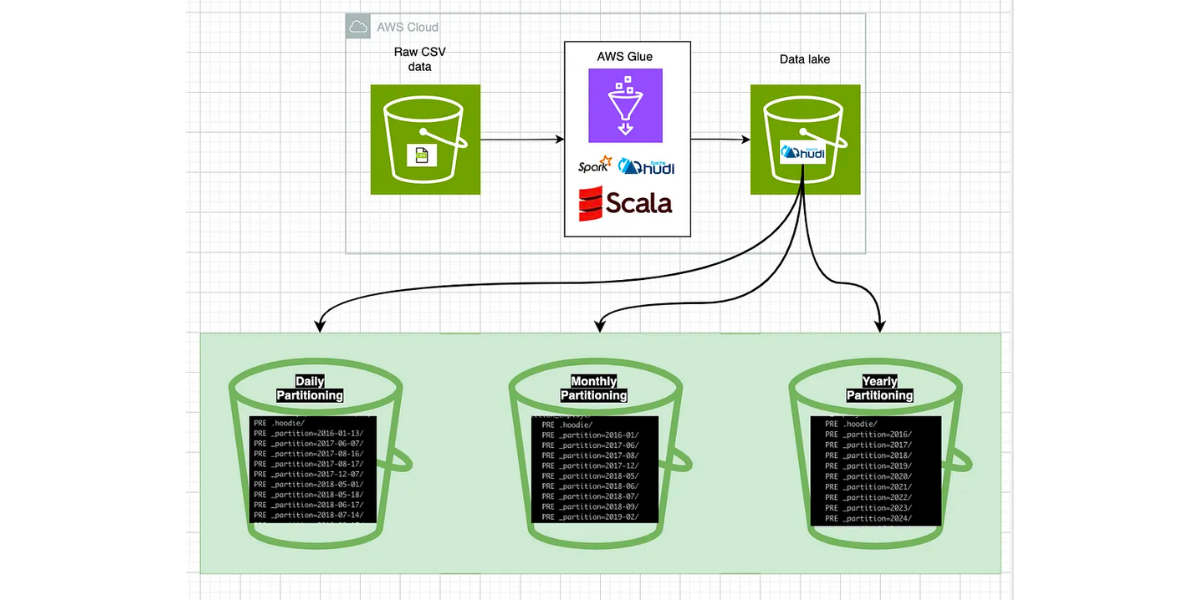
Apache Hudi: Managing Partition on a petabyte-scale table
Leverage Partition Paths of your data lake tables to Optimize Data Retrieval Costs on the cloud
Use Amazon Athena with Spark SQL for your open-source transactional table formats
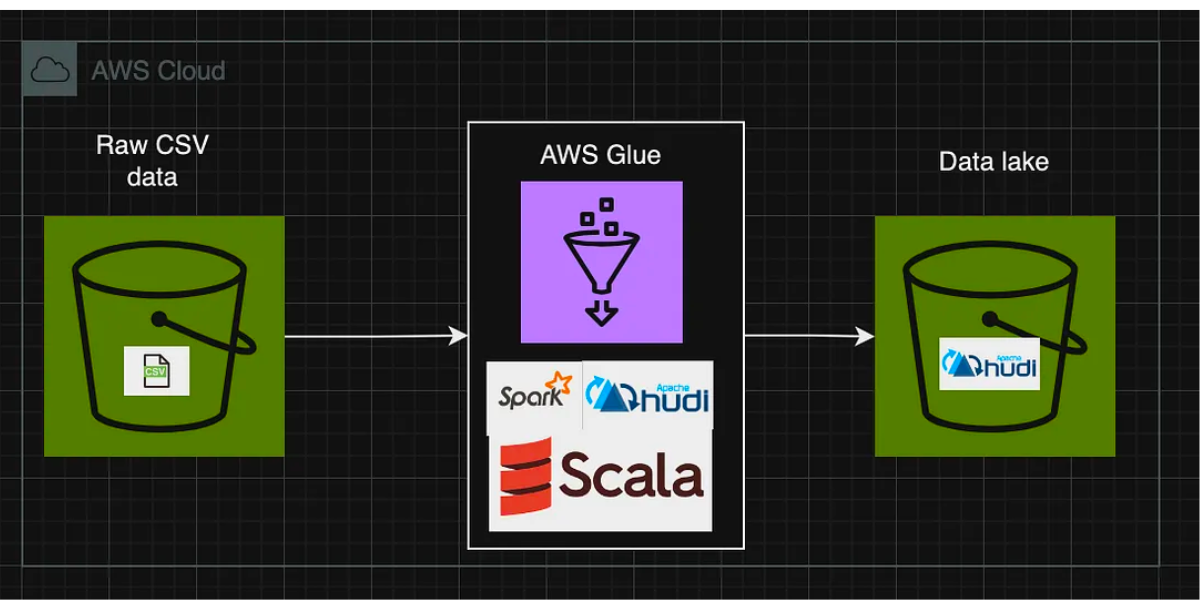
Data Engineering: Bootstrapping Data lake with Apache Hudi

Learn How to Move Data From MongoDB to Apache Hudi Using PySpark

Deleting Items from Apache Hudi using Delta Streamer in UPSERT Mode with Kafka Avro Messages
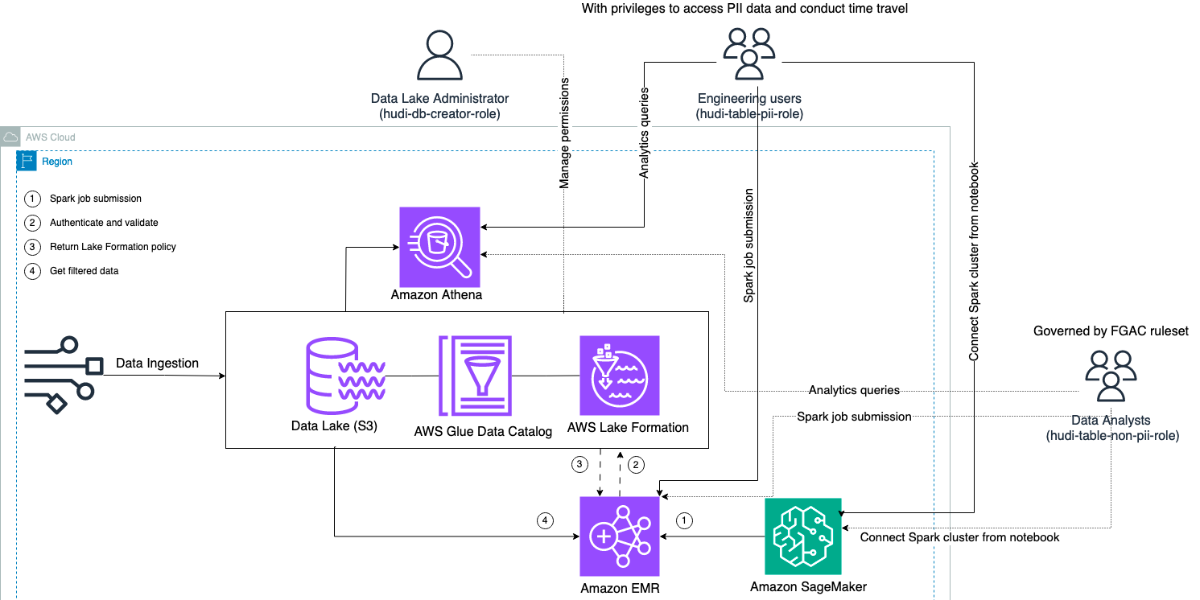
Enforce fine-grained access control on Open Table Formats via Amazon EMR integrated with AWS Lake Formation
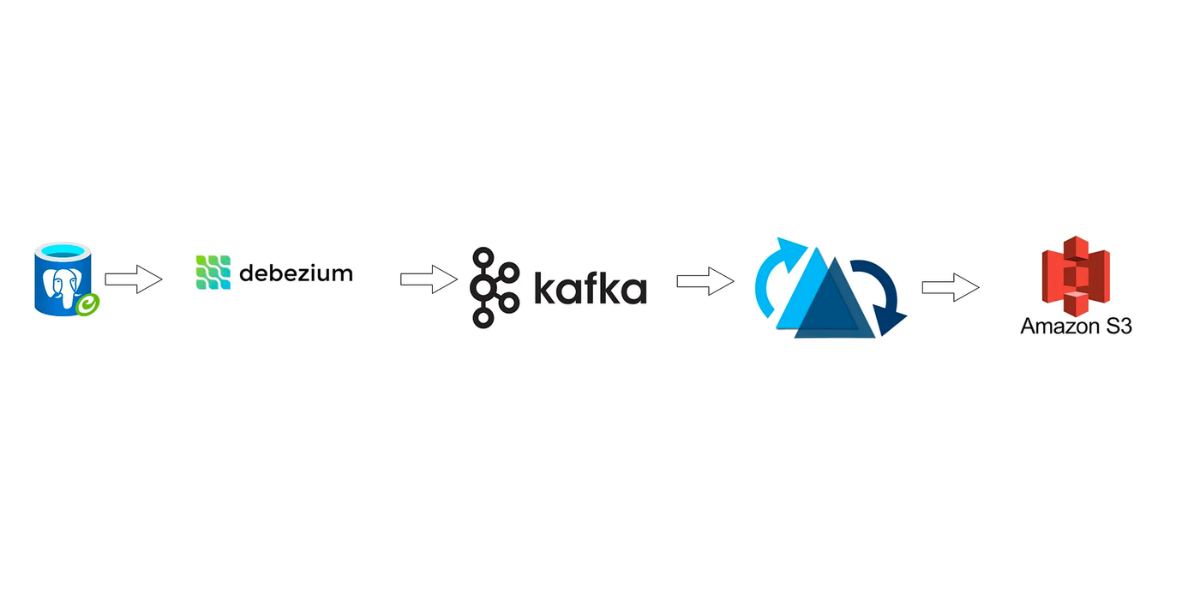
In-House Data Lake with CDC Processing, Hudi, Docker

Introduction to Apache Hudi
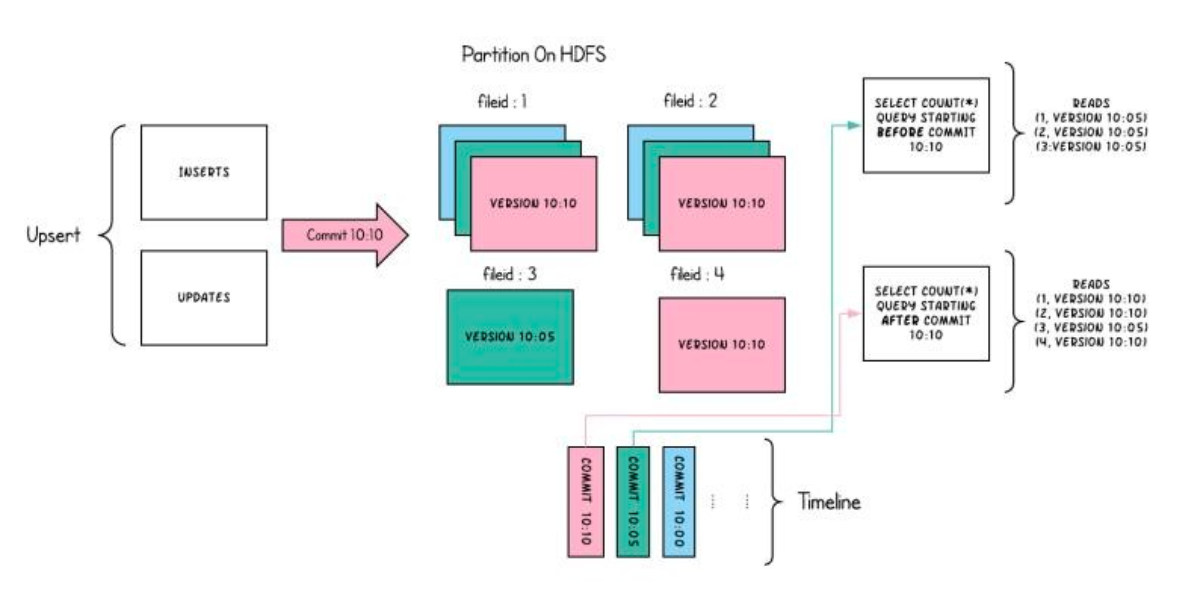
Small Talk about Apache Hudi

Build a federated query solution with Apache Doris, Apache Flink, and Apache Hudi
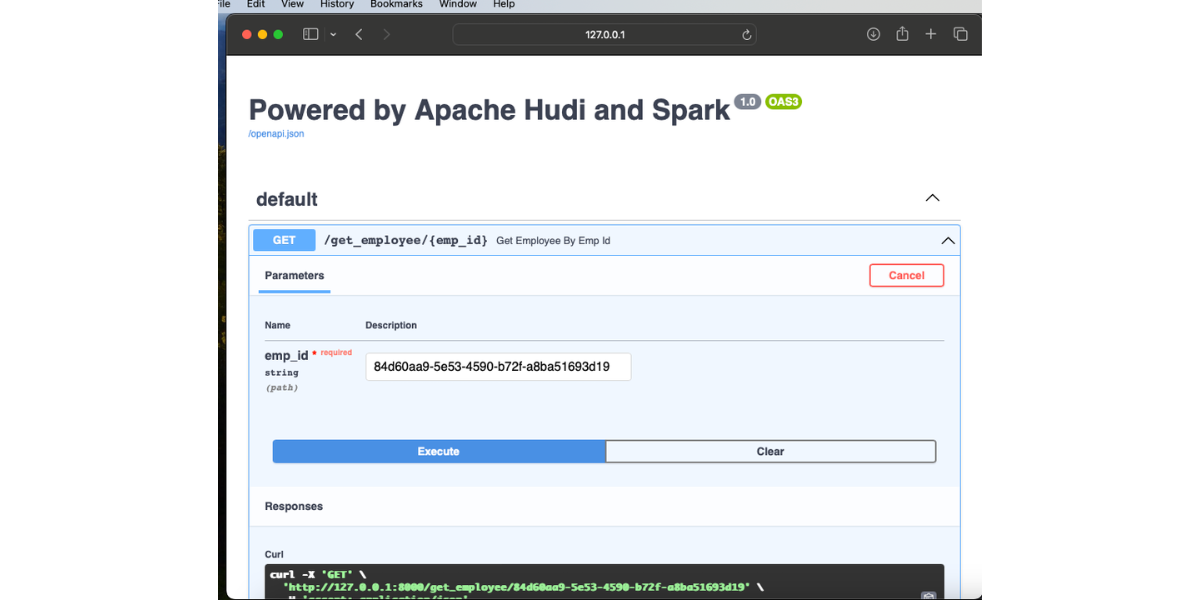
From Data lake to Microservices: Unleashing the Power of Apache Hudi's Record Level Index with FastAPI and Spark Connect

Apache Hudi 2023: A Year In Review

What is Apache Hudi
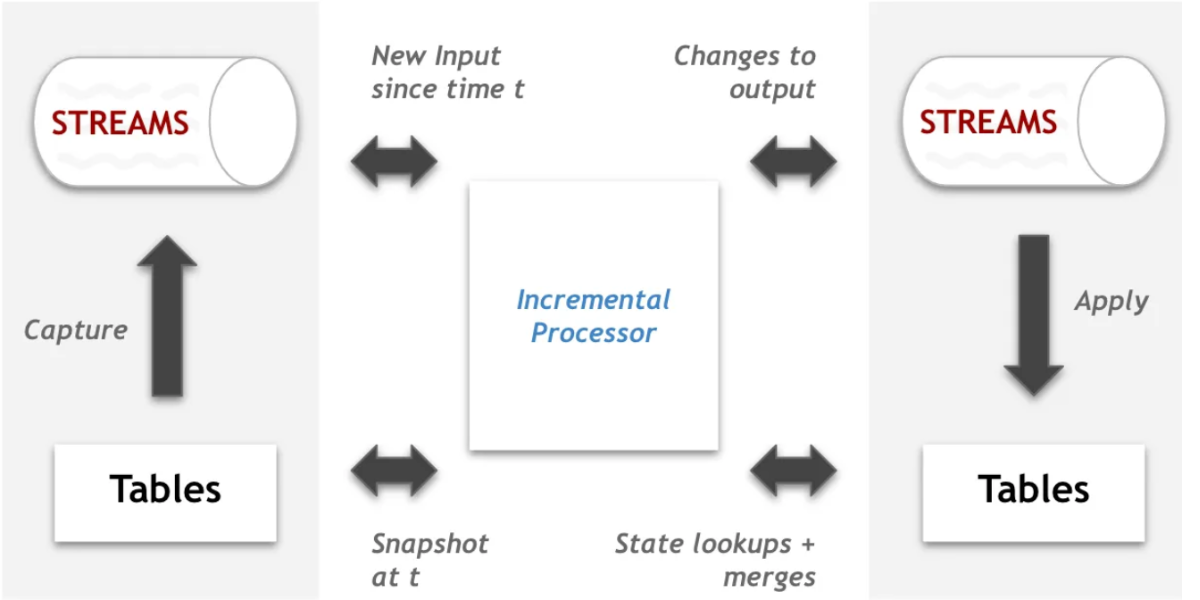
Getting started with Apache Hudi
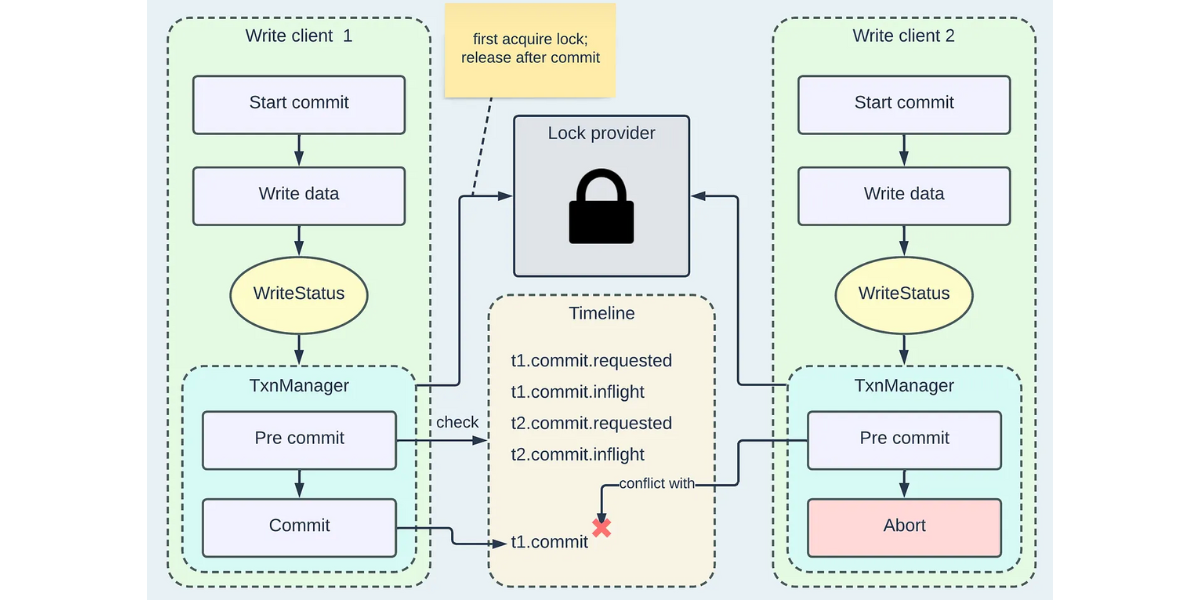
Apache Hudi: From Zero To One (7/10)
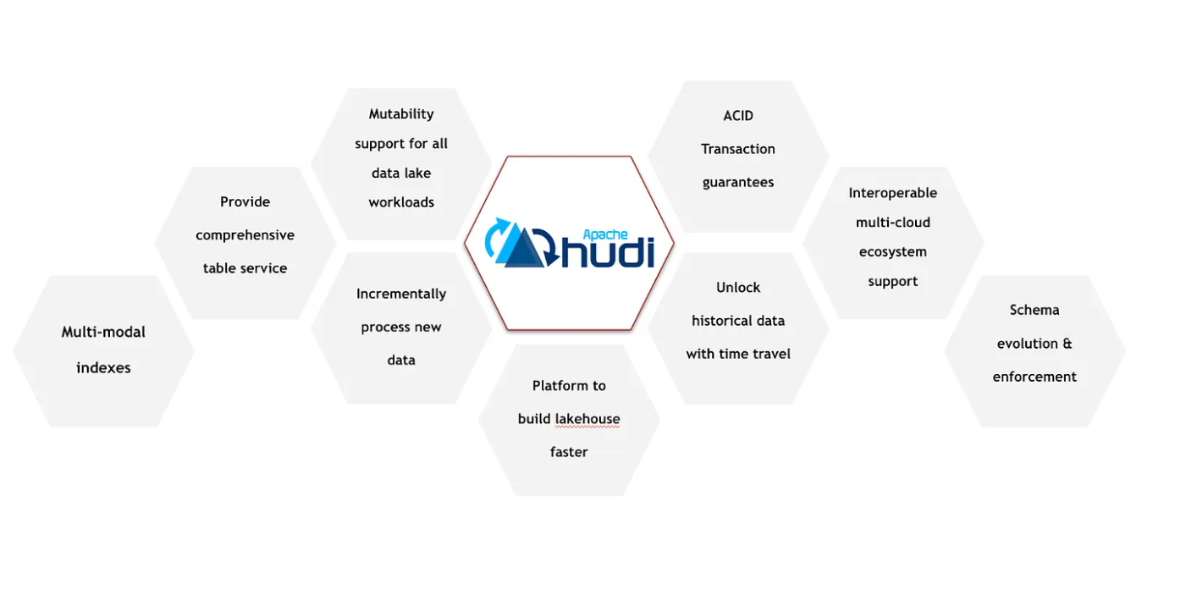
Getting started with Apache Hudi

Mastering Data Lakes: A Deep Dive into MINIO, Hudi, and Delta Streamer
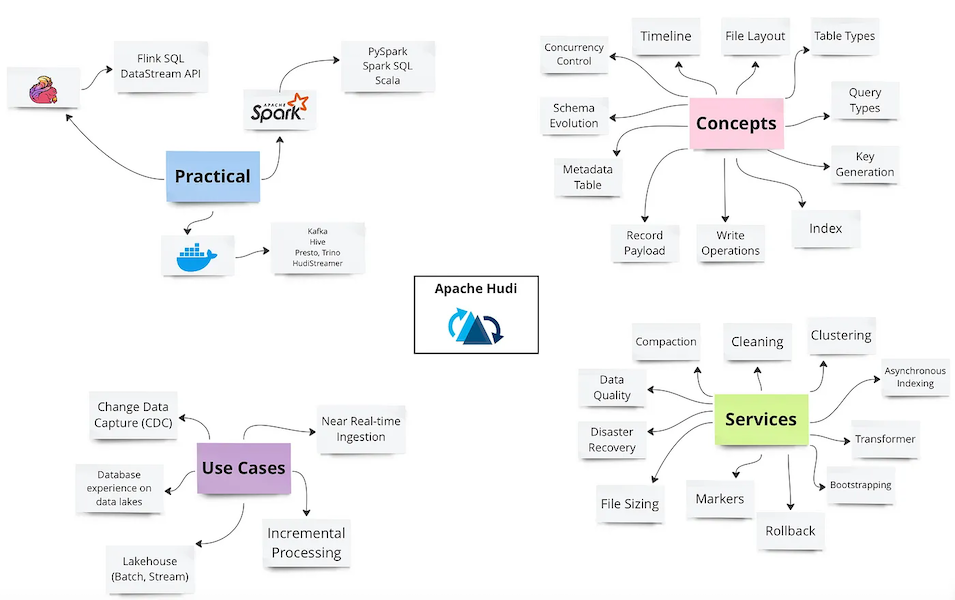
Apache Hudi (Part 1): History, Getting Started
Real-Time Data Processing with Postgres, Debezium, Kafka, Schema Registry, and Delta Streamer Guide for Begineers

Introducing Apache Hudi support with AWS Glue crawlers

Hudi Streamer (Delta Streamer) Hands-On Guide: Local Ingestion from Parquet Source
Apache Hudi: From Zero To One (6/10)
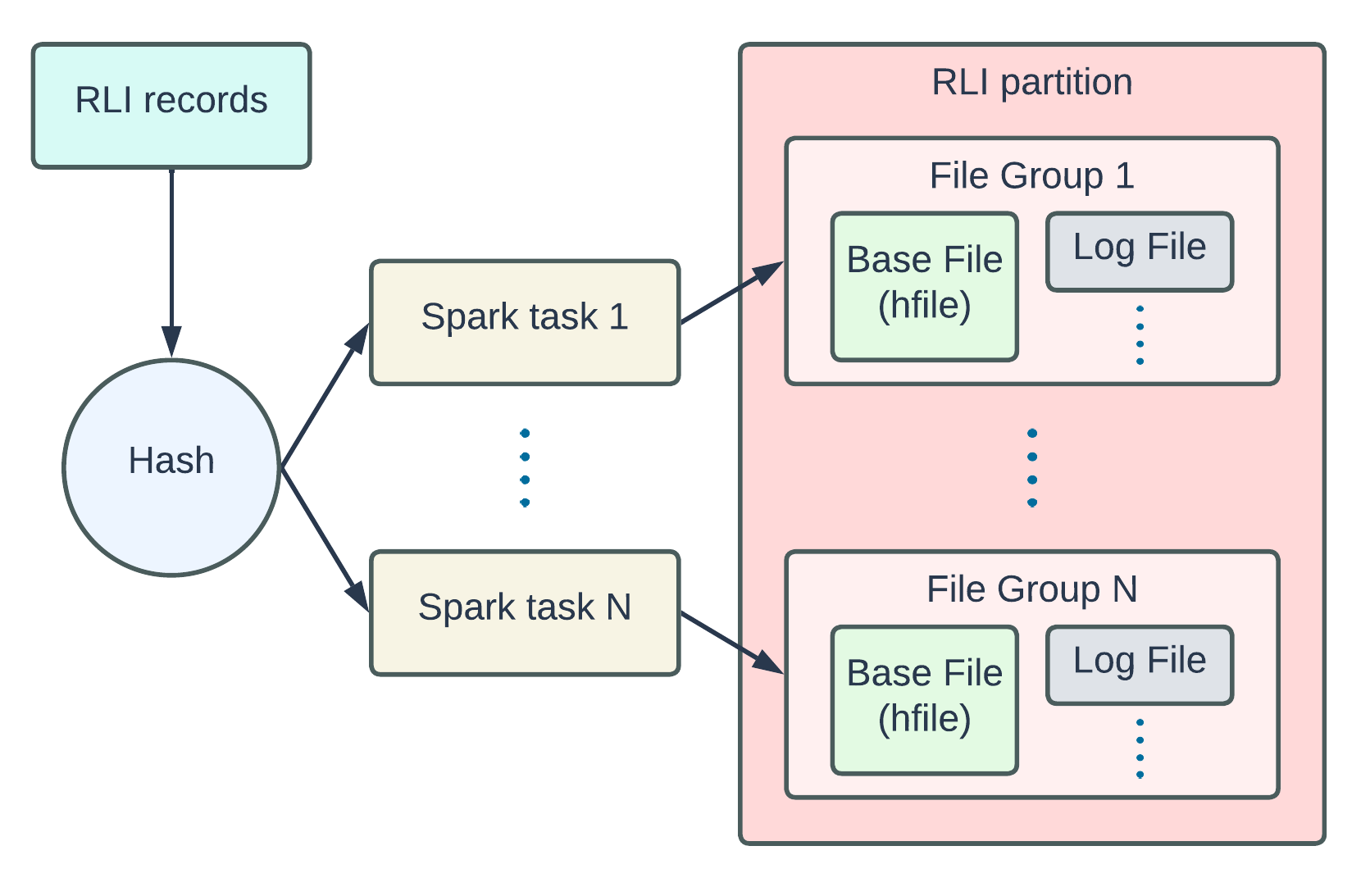
Record Level Index: Hudi's blazing fast indexing for large-scale datasets
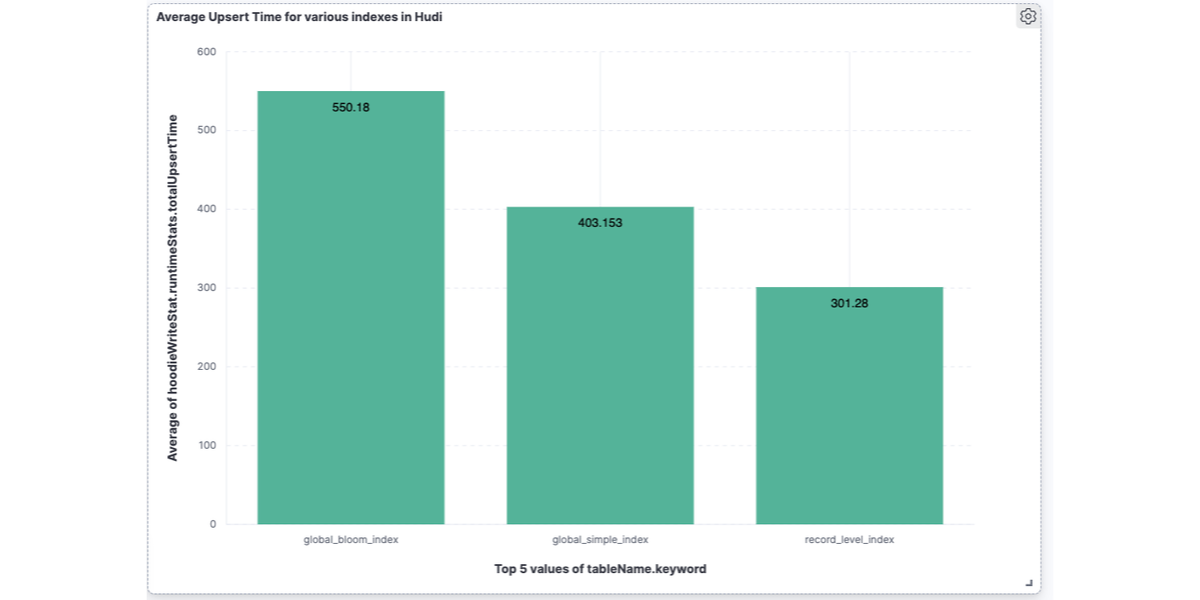
UPSERT Performance Evaluation of Hudi 0.14 and Spark 3.4.1: Record Level Index vs. Global Bloom & Global Simple Indexes

Tipico Facilitates Faster Data Access with a Modern Data Strategy on AWS

It's Time for the Universal Data Lakehouse
Load data incrementally from transactional data lakes to data warehouses
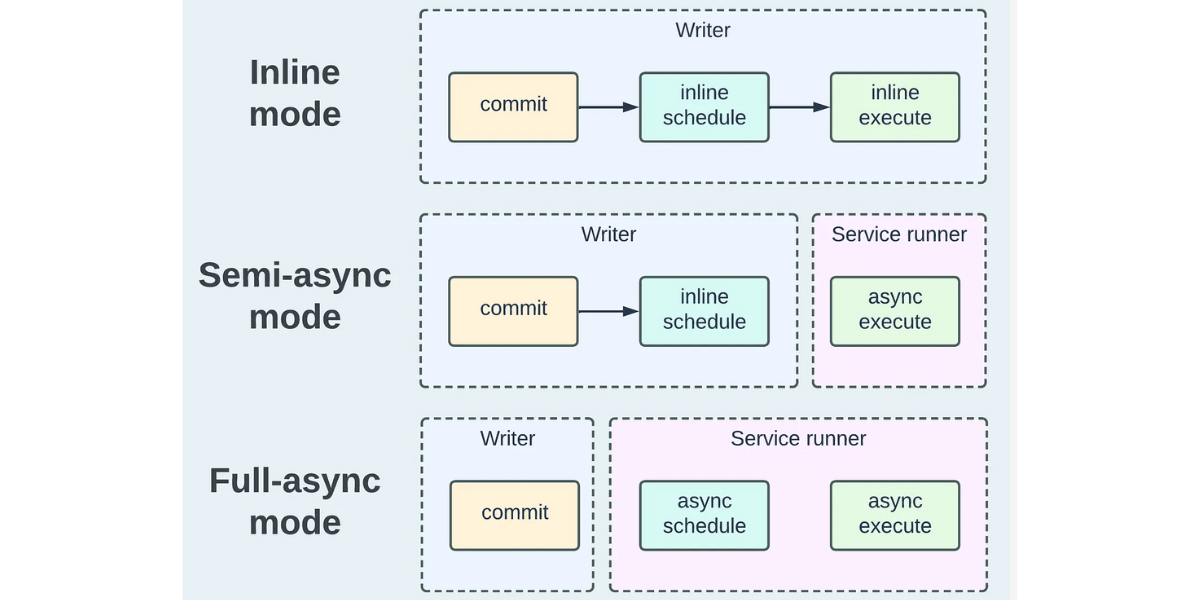
Apache Hudi: From Zero To One (5/10)
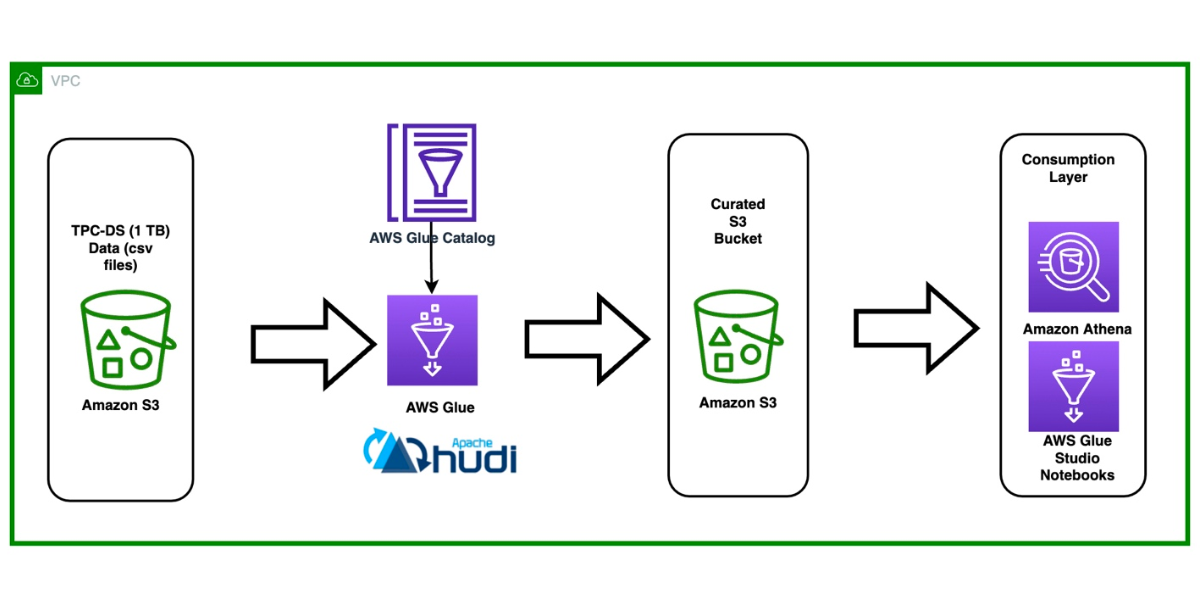
Get started with Apache Hudi using AWS Glue by implementing key design concepts – Part 1

StarRocks query performance with Apache Hudi and Onehouse

Apache Hudi: Copy on Write(CoW) Table
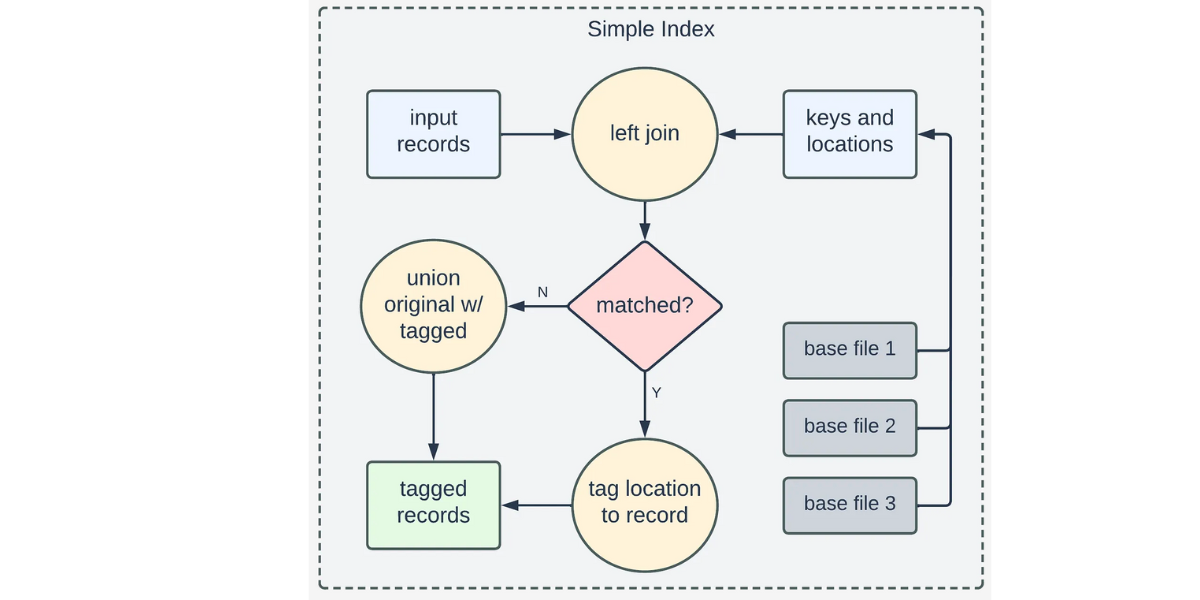
Apache Hudi: From Zero To One (4/10)

Exploring the Architecture of Apache Iceberg, Delta Lake, and Apache Hudi

A Beginner’s Guide to Apache Hudi with PySpark — Part 1 of 2
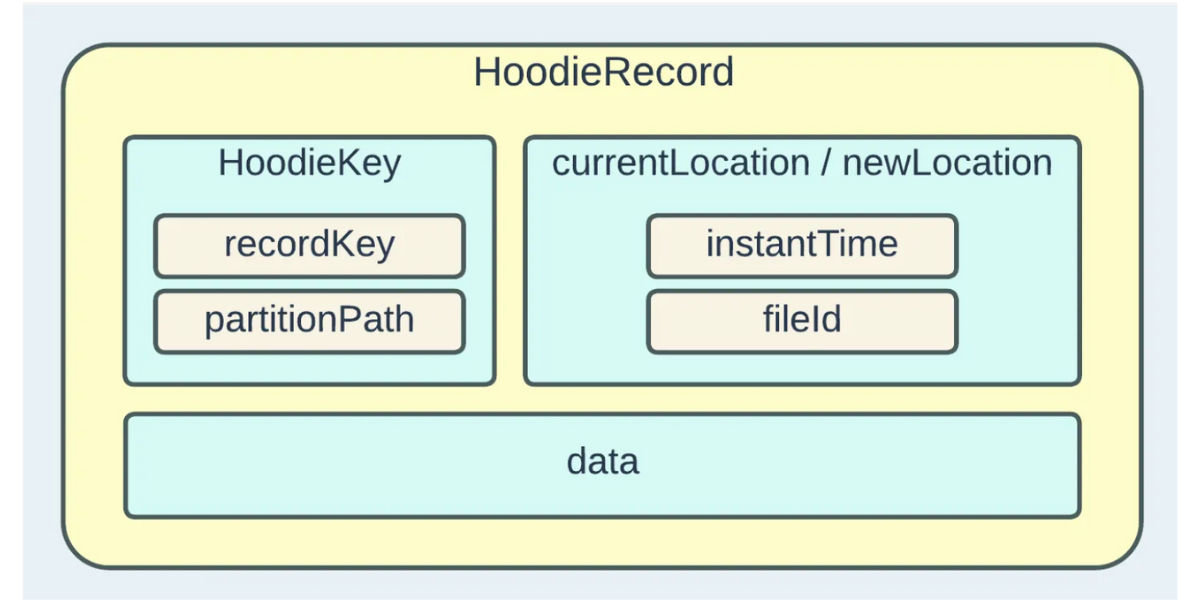
Apache Hudi: From Zero To One (3/10)
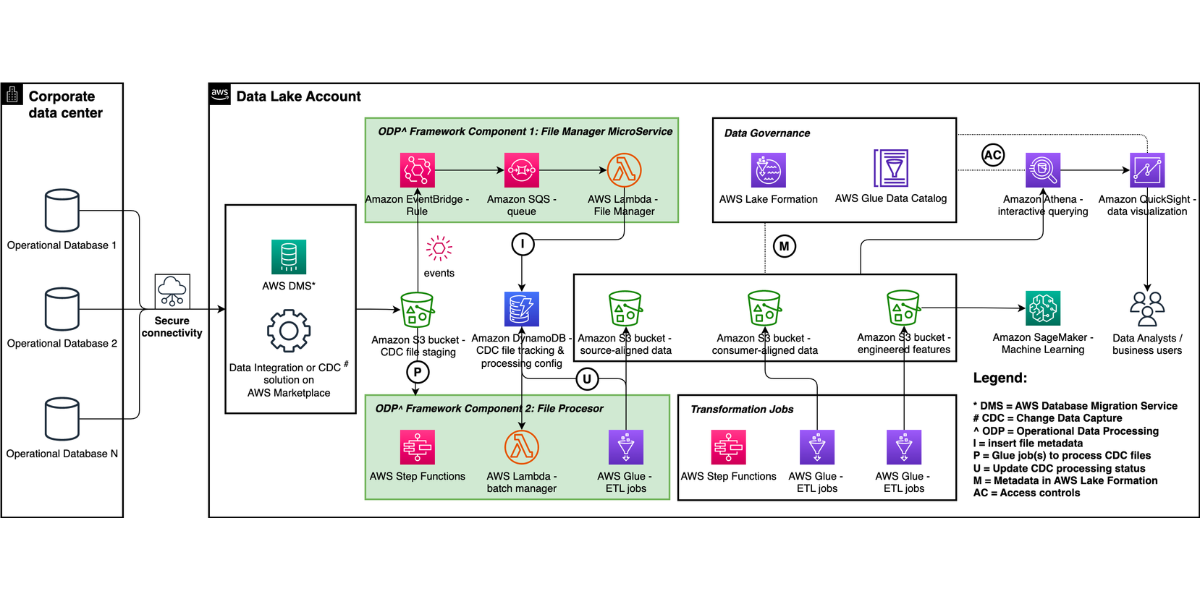
Simplify operational data processing in data lakes using AWS Glue and Apache Hudi

Lakehouse or Warehouse? Part 2 of 2
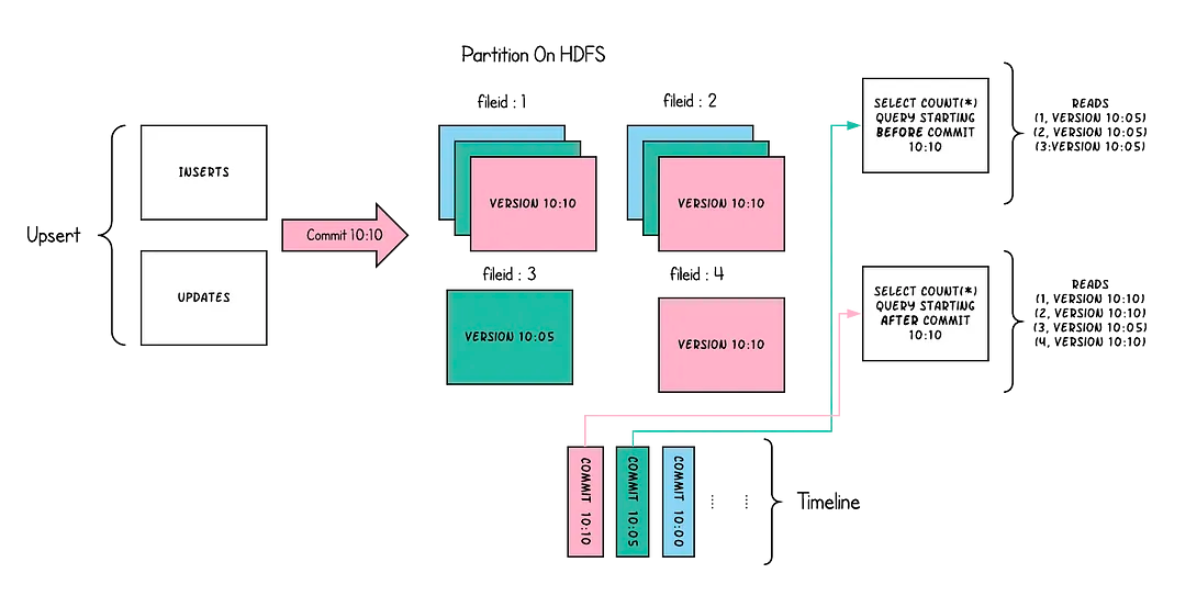
Demystifying Copy-on-Write in Apache Hudi: Understanding Read and Write Operations
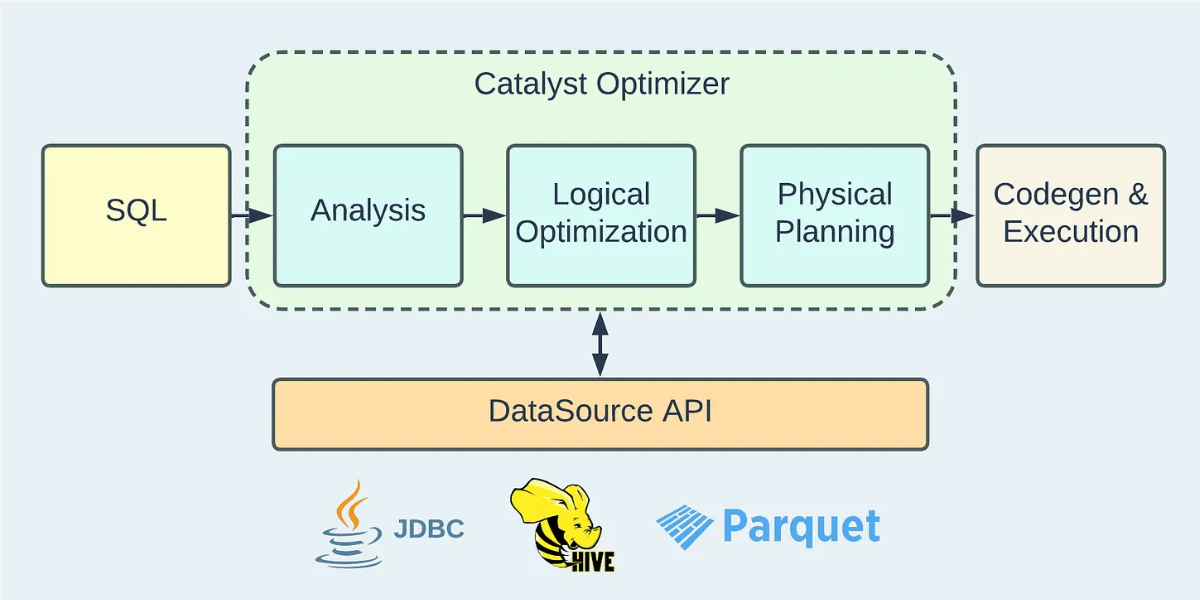
Apache Hudi: From Zero To One (2/10)

Lakehouse or Warehouse? Part 1 of 2

Incremental Queries with Apache Hudi and Apache Flink
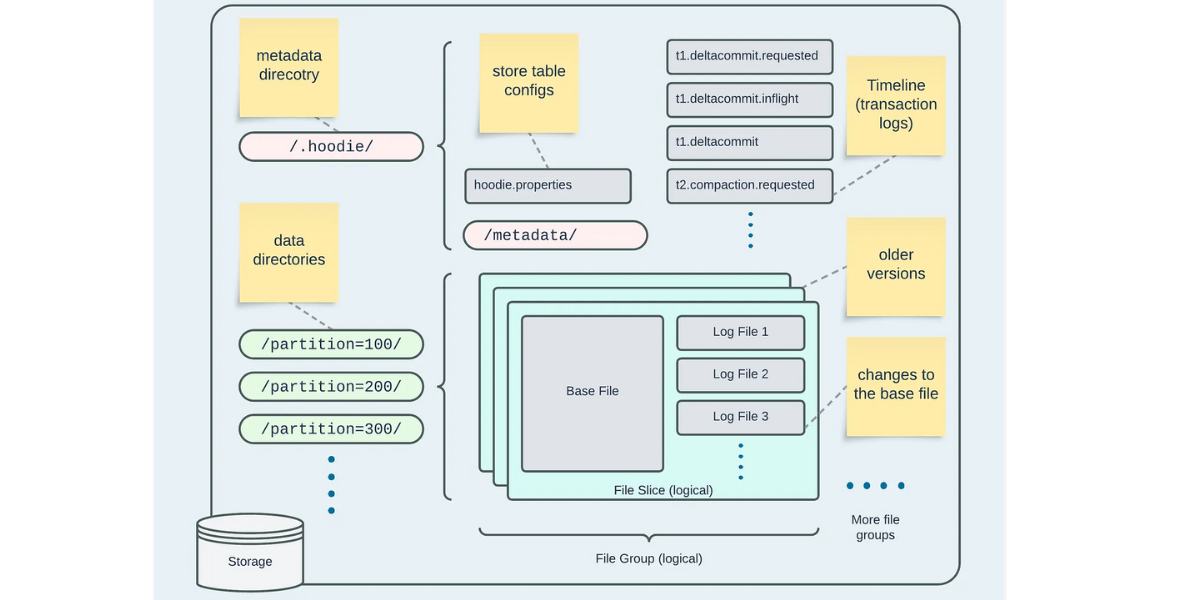
Apache Hudi: From Zero To One (1/10)
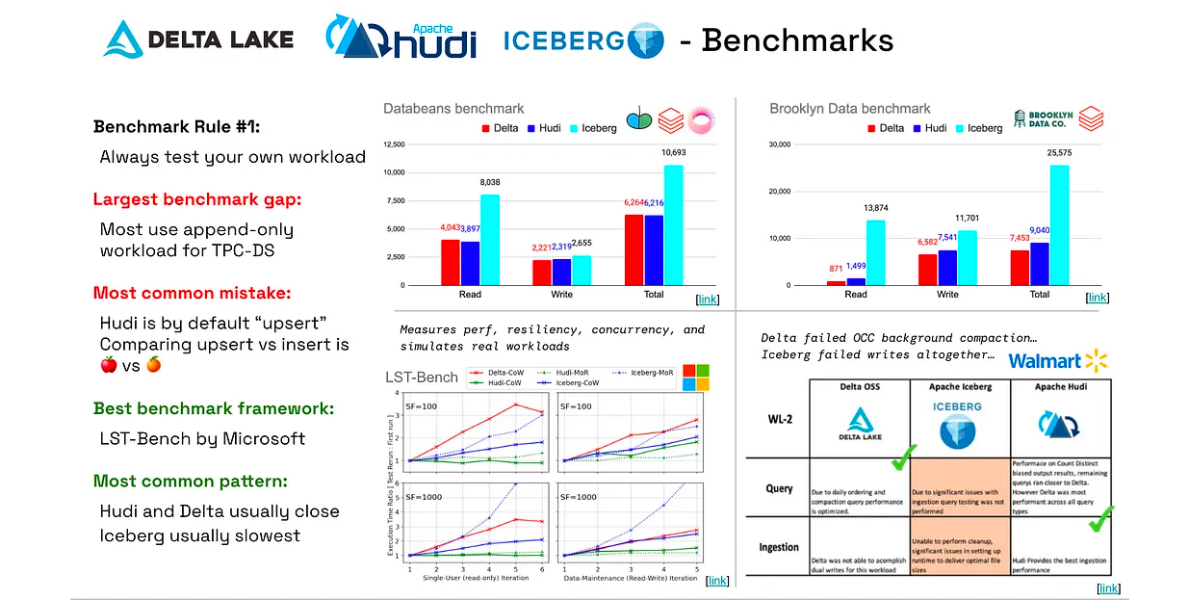
Delta, Hudi, Iceberg — A Benchmark Compilation
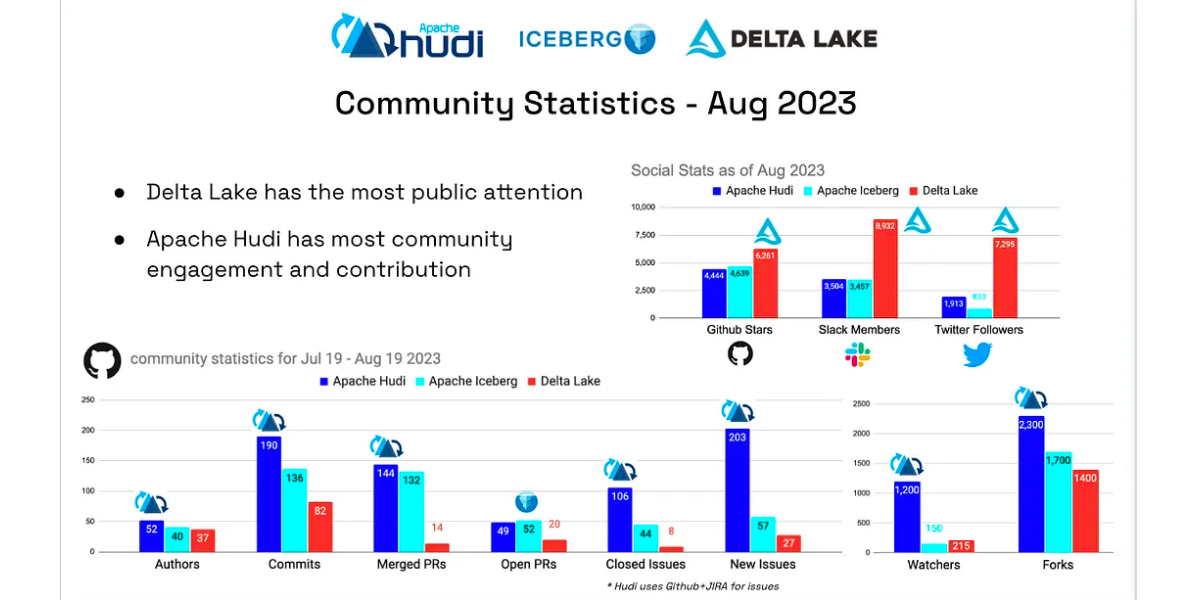
Delta, Hudi, Iceberg — Which is most popular?
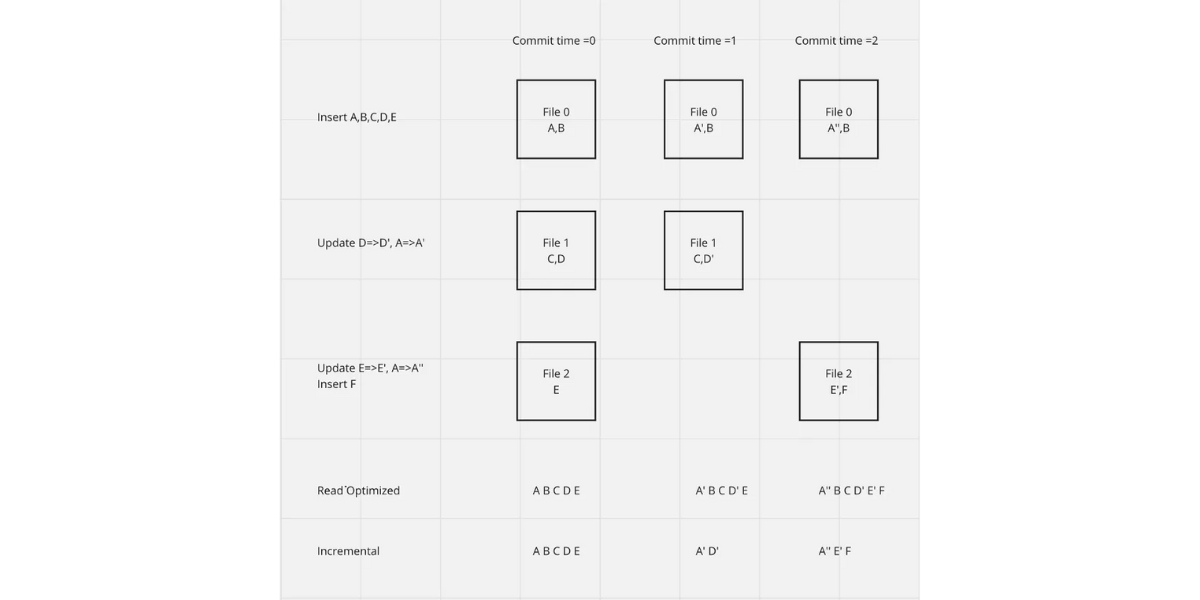
Exploring various storage types in Apache Hudi

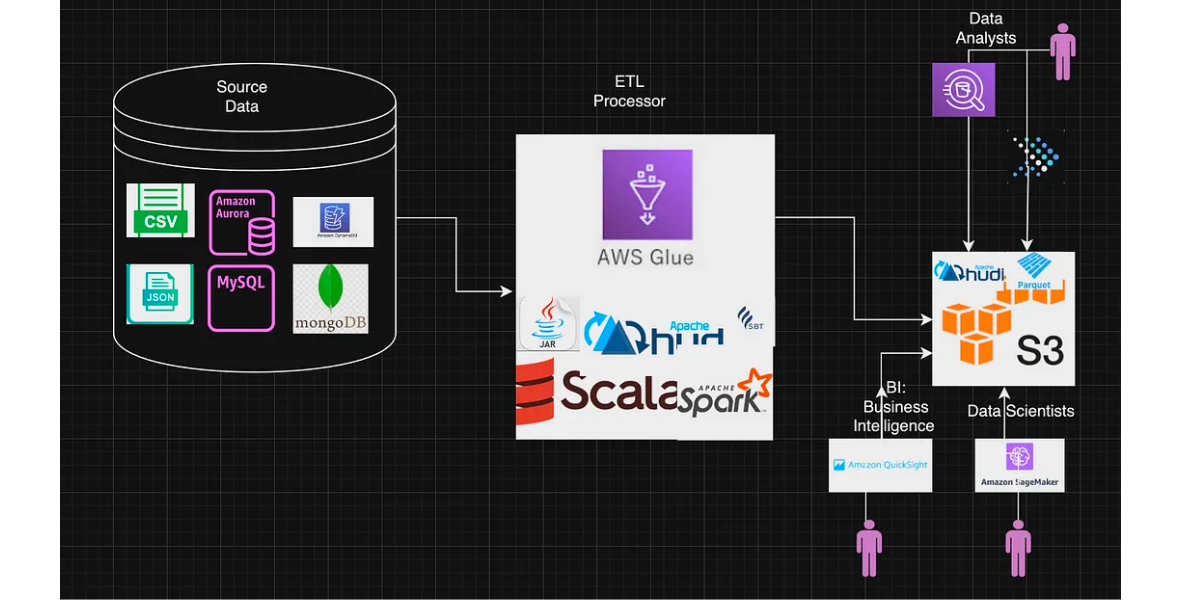
Data Lakehouse Architecture for Big Data with Apache Hudi
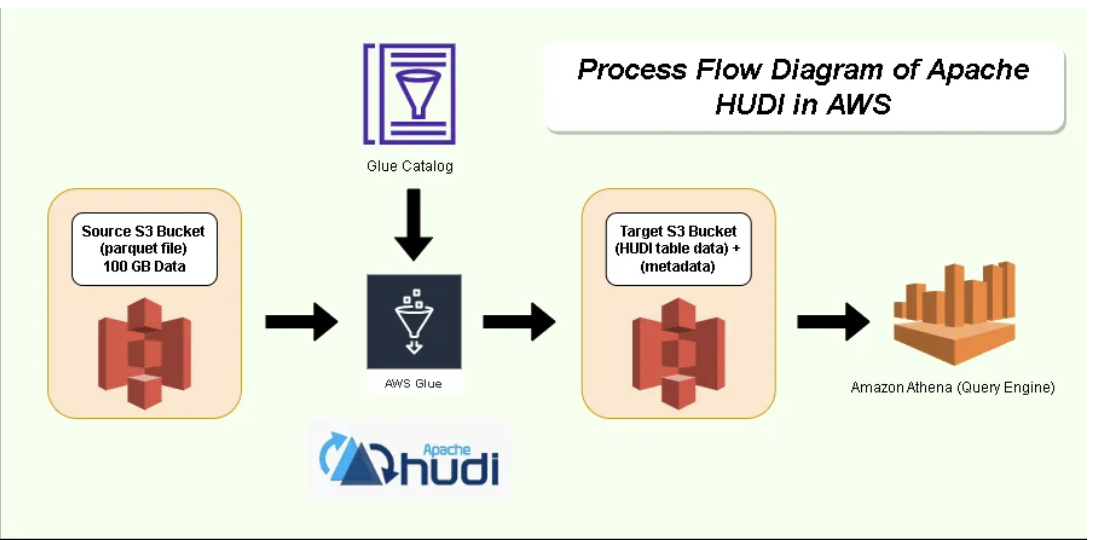
Apache Hudi on AWS Glue: A Step-by-Step Guide

Skip rocks and files: Turbocharge Trino queries with Hudi’s multi-modal indexing subsystem
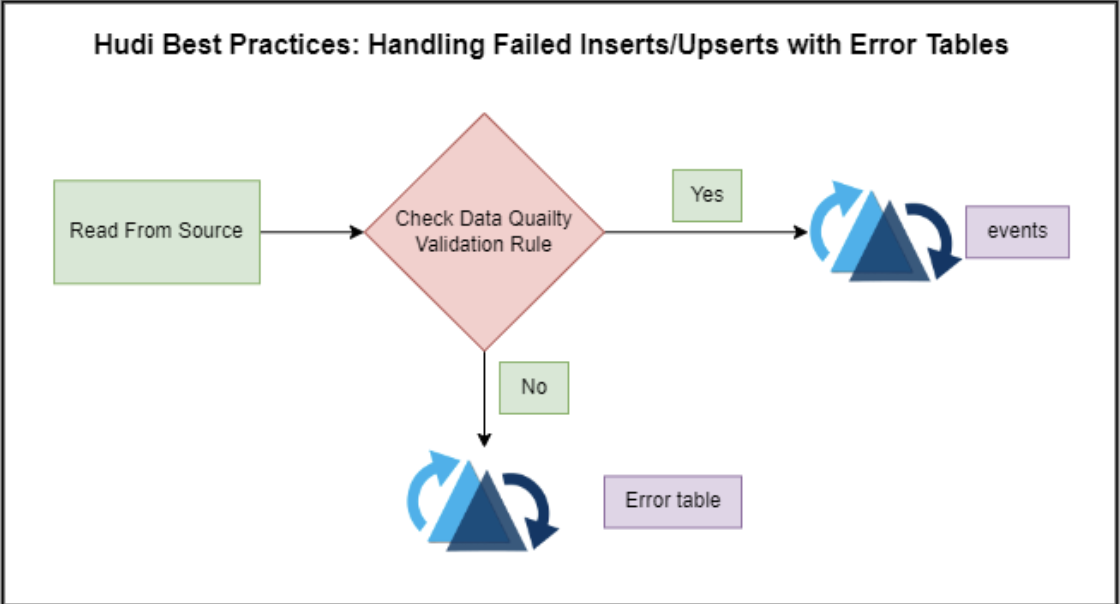
Hudi Best Practices: Handling Failed Inserts/Upserts with Error Tables

What about Apache Hudi, Apache Iceberg, and Delta Lake?

An Introduction to the Hudi and Flink Integration

Delta, Hudi, and Iceberg: The Data Lakehouse Trifecta
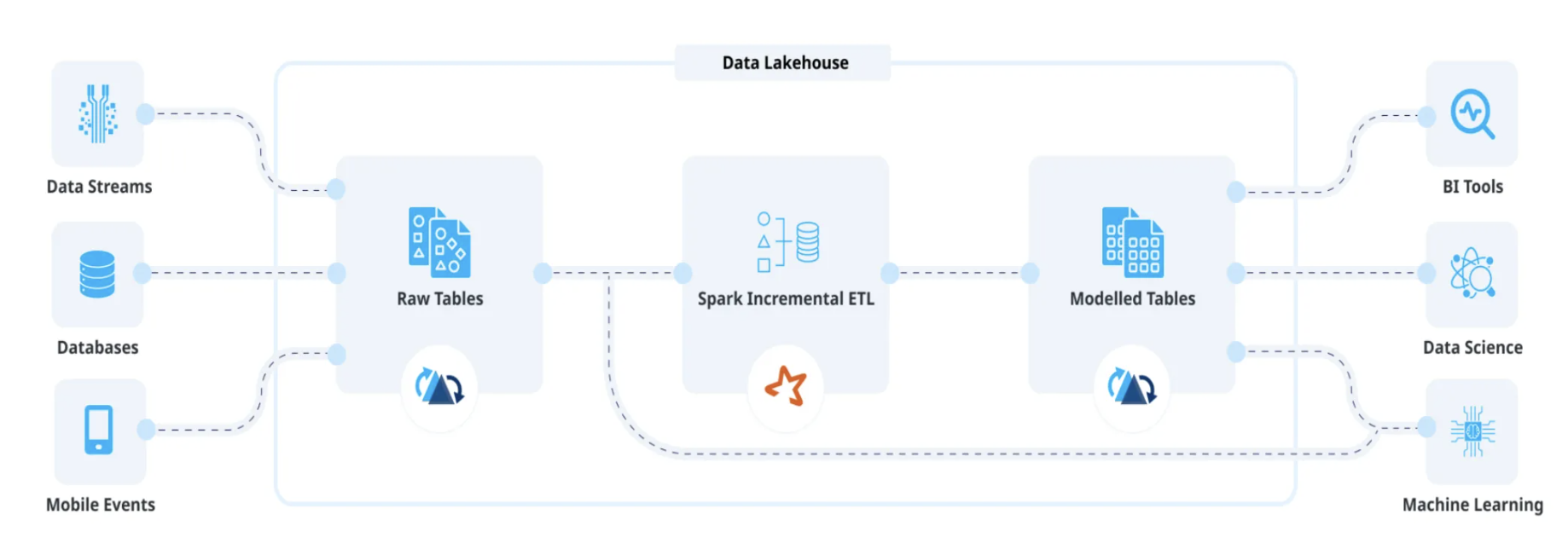
Setting Uber’s Transactional Data Lake in Motion with Incremental ETL Using Apache Hudi

Apache Hudi 2022 - A year in Review

Build Your First Hudi Lakehouse with AWS S3 and AWS Glue

Run Apache Hudi at scale on AWS
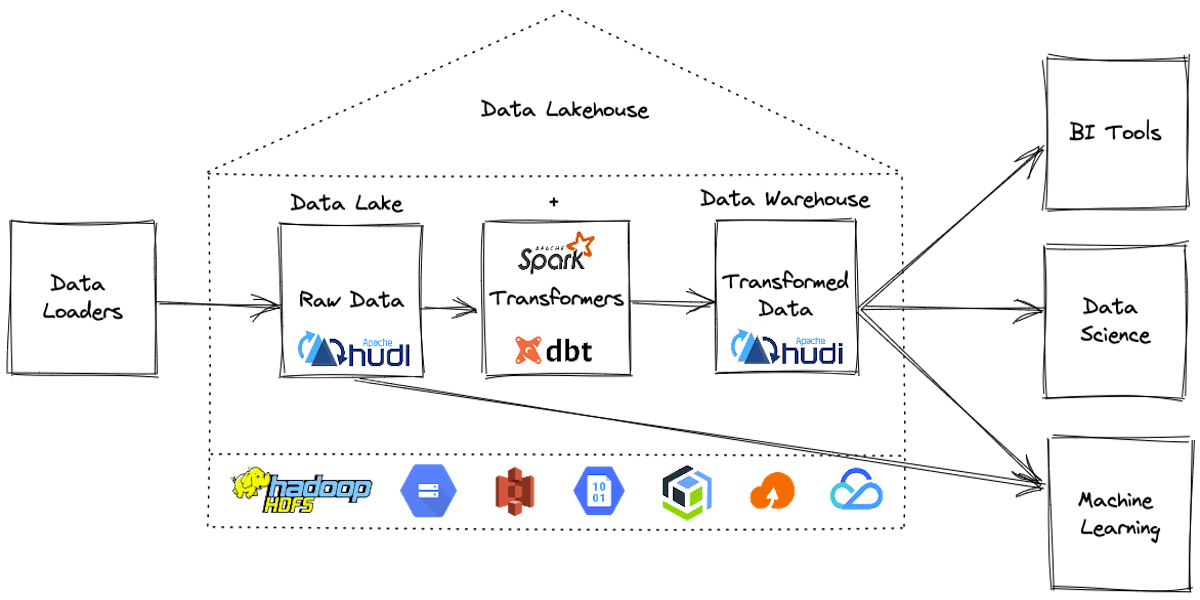
Build Open Lakehouse using Apache Hudi & dbt
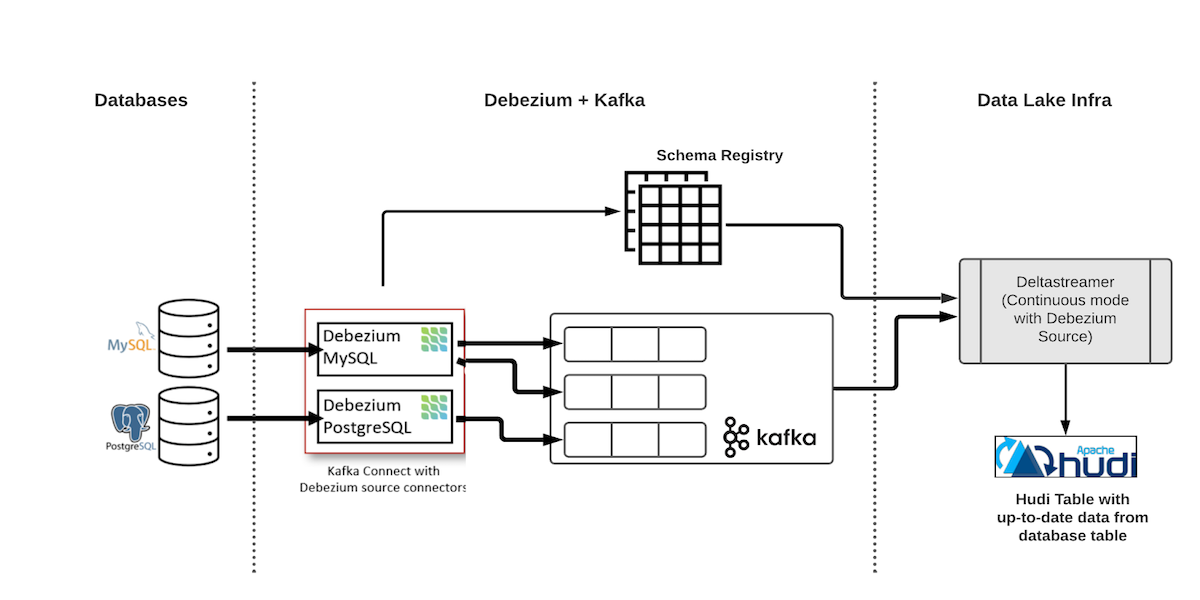
Change Data Capture with Debezium and Apache Hudi

Apache Hudi - 2021 a Year in Review
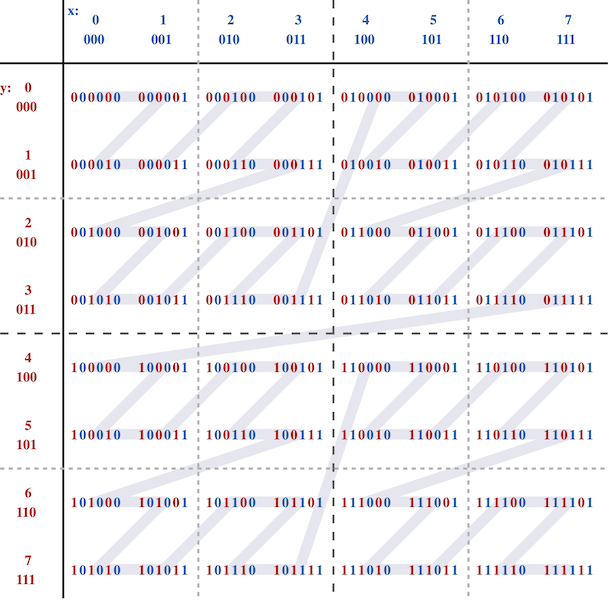
Hudi Z-Order and Hilbert Space Filling Curves
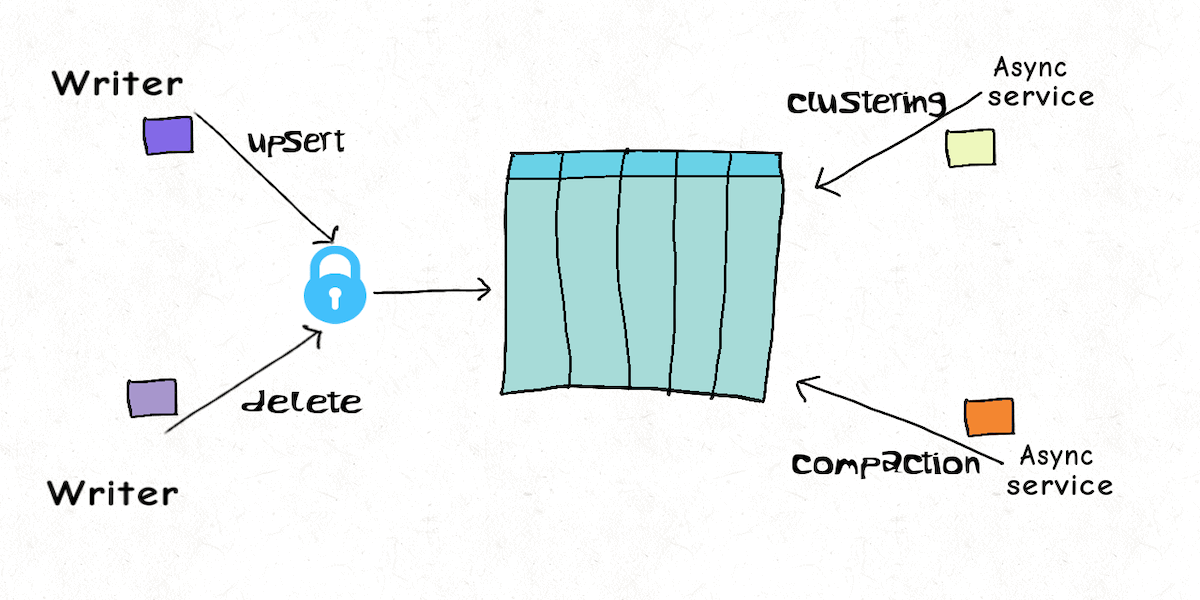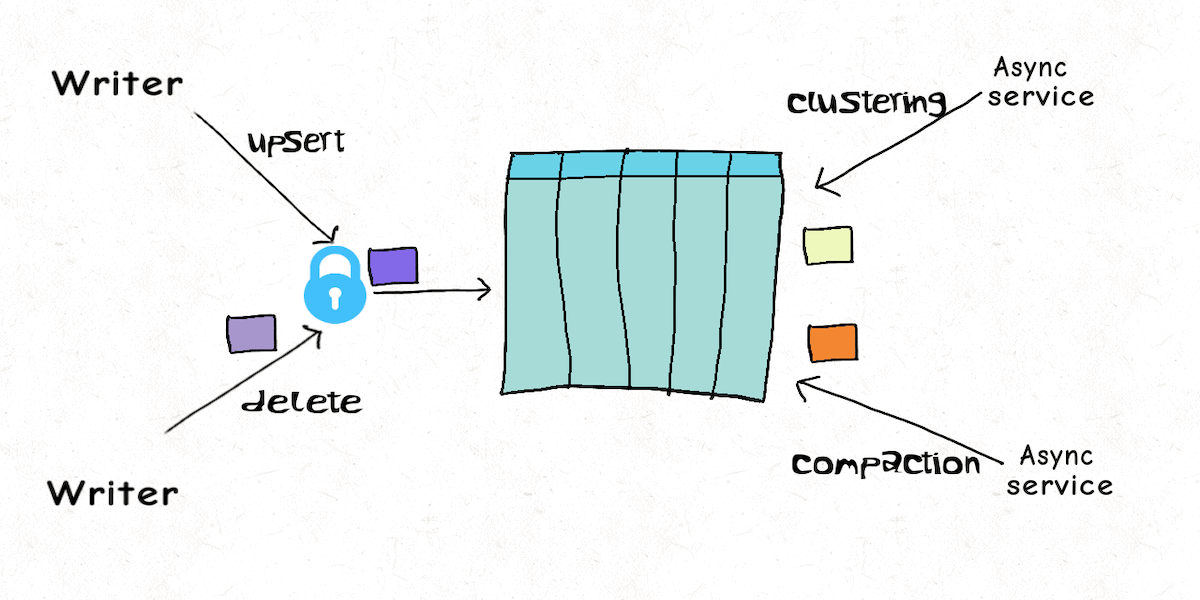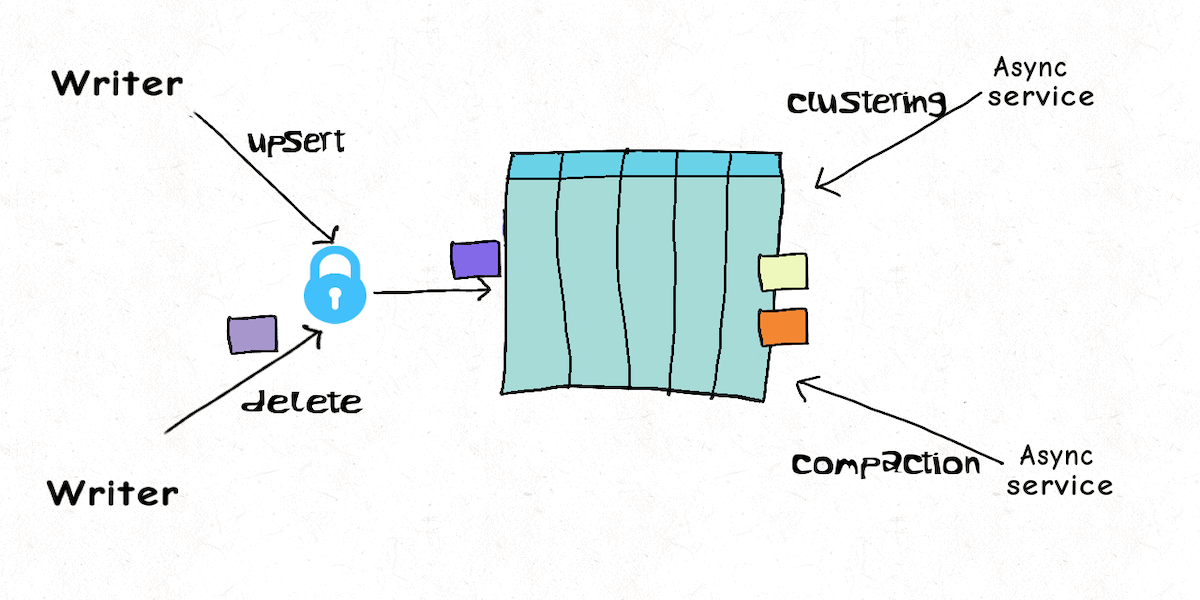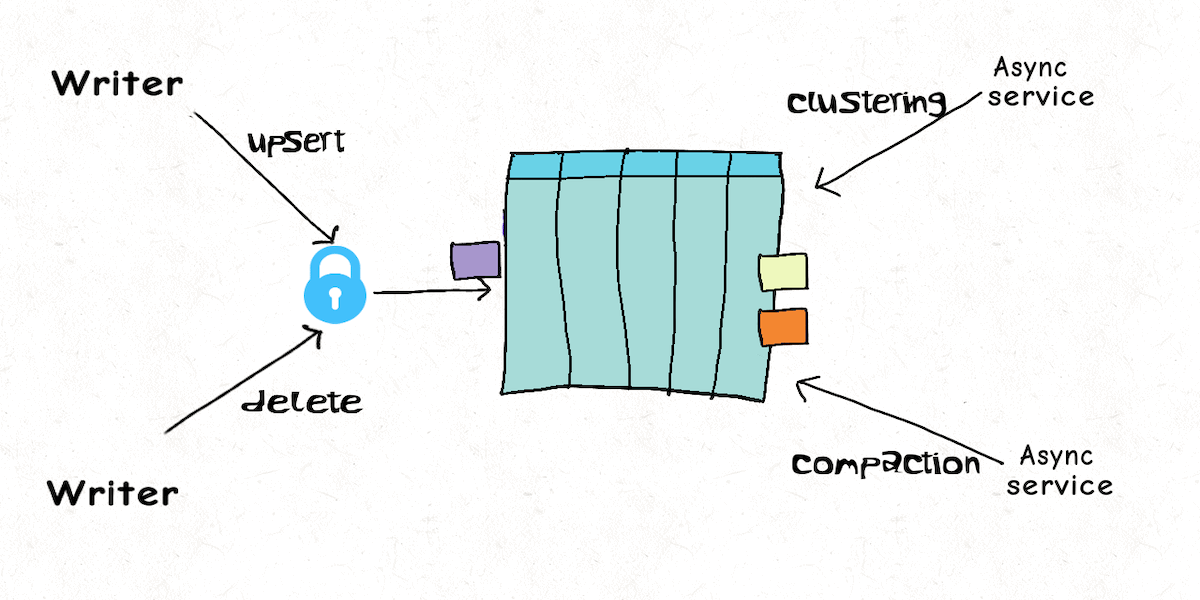
Lakehouse Concurrency Control: Are we too optimistic?

Building an ExaByte-level Data Lake Using Apache Hudi at ByteDance
Asynchronous Clustering using Hudi
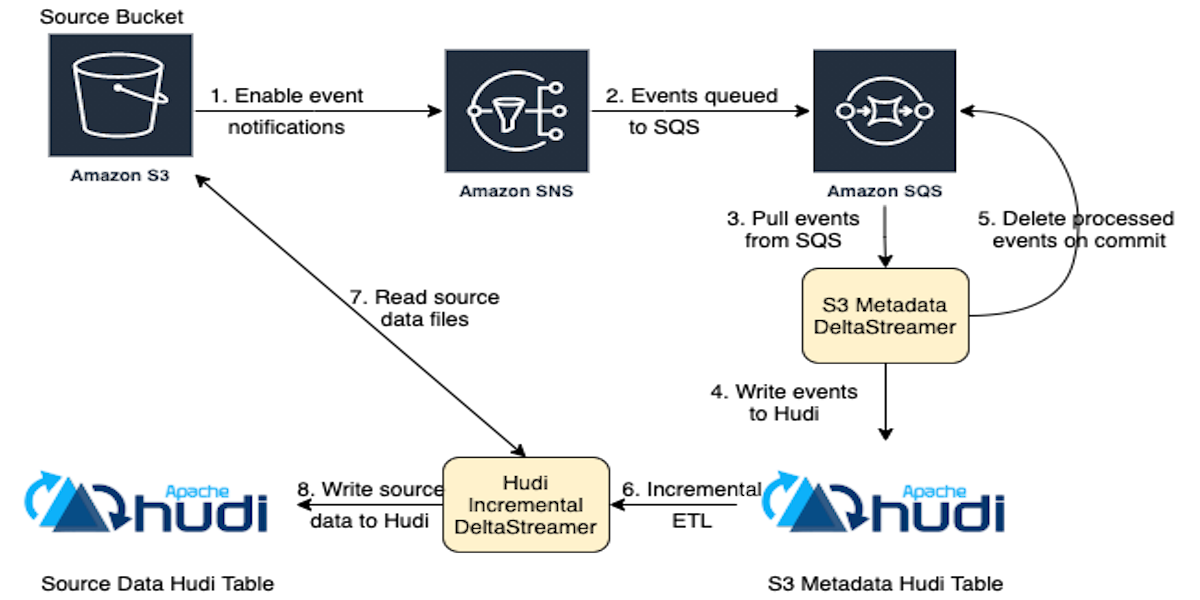
Reliable ingestion from AWS S3 using Hudi
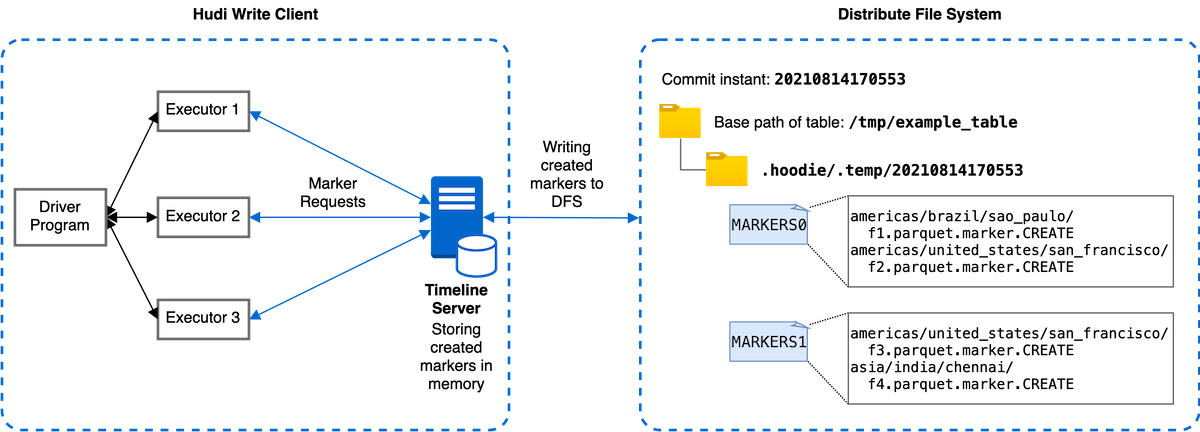
Improving Marker Mechanism in Apache Hudi
Adding support for Virtual Keys in Hudi
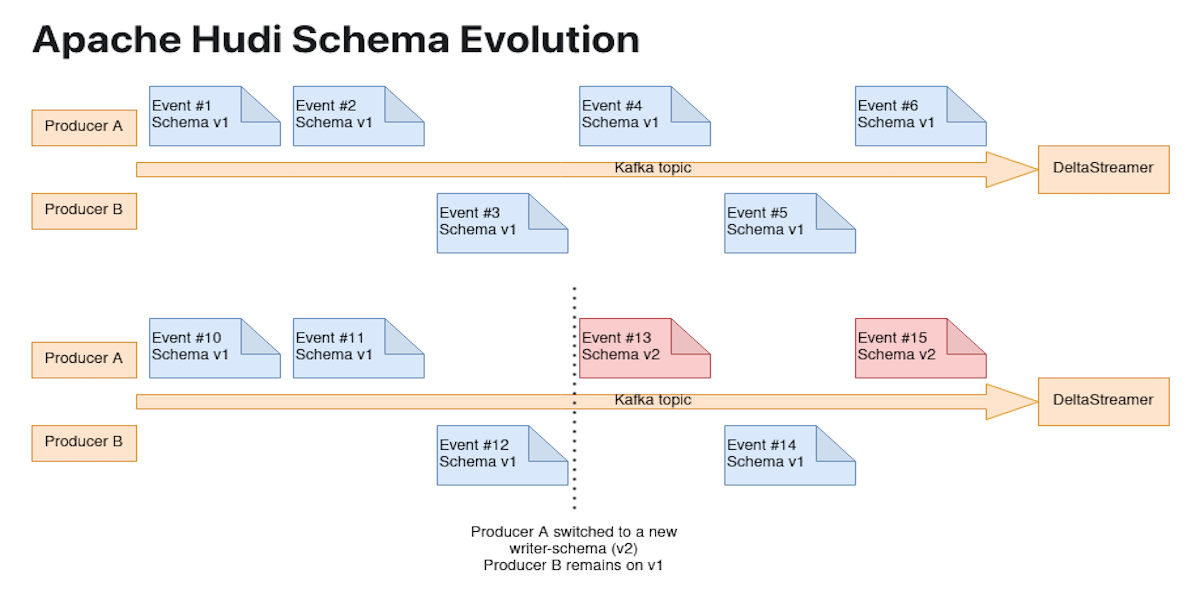
Schema evolution with DeltaStreamer using KafkaSource

Apache Hudi - The Data Lake Platform
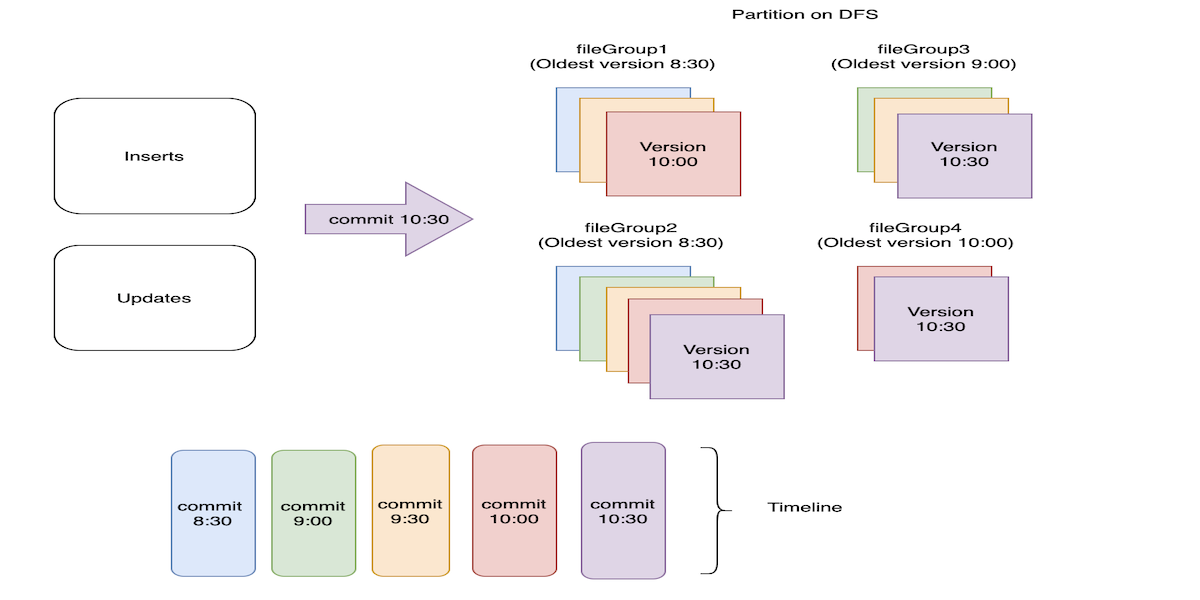
Employing correct configurations for Hudi's cleaner table service
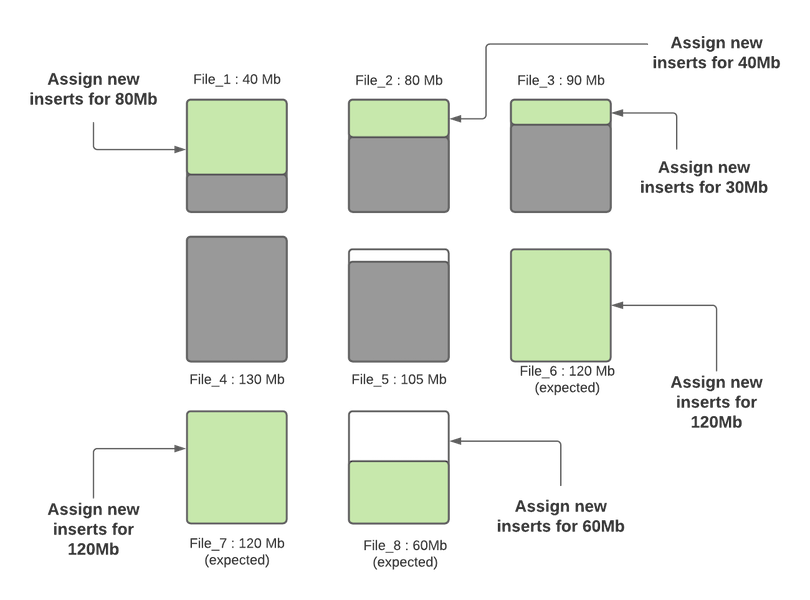
Streaming Responsibly - How Apache Hudi maintains optimum sized files
Apache Hudi Key Generators
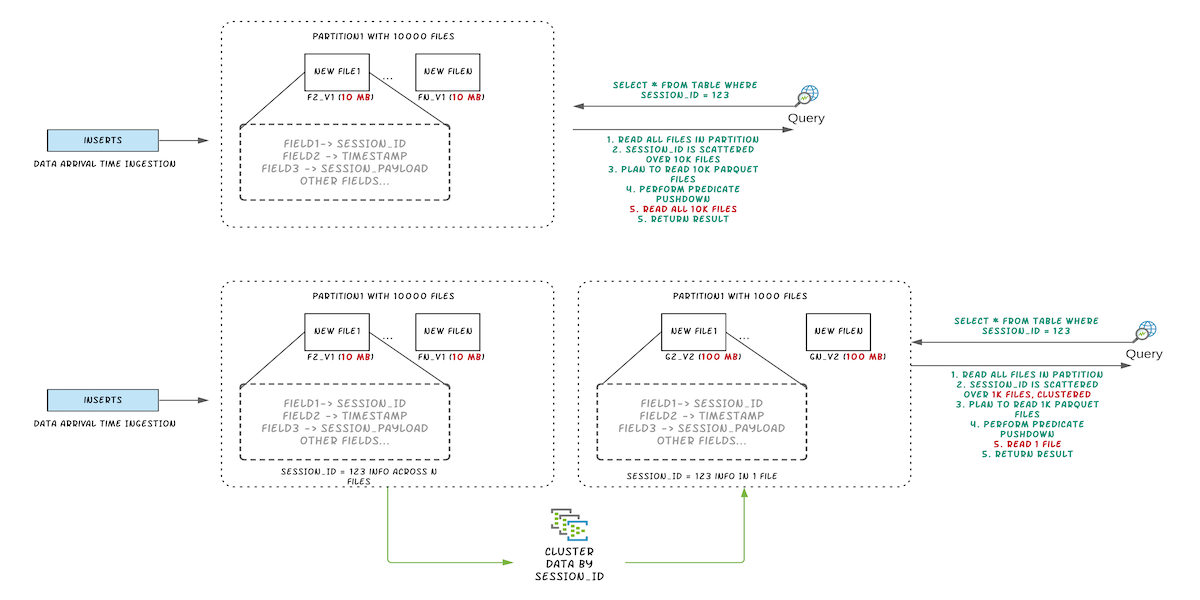
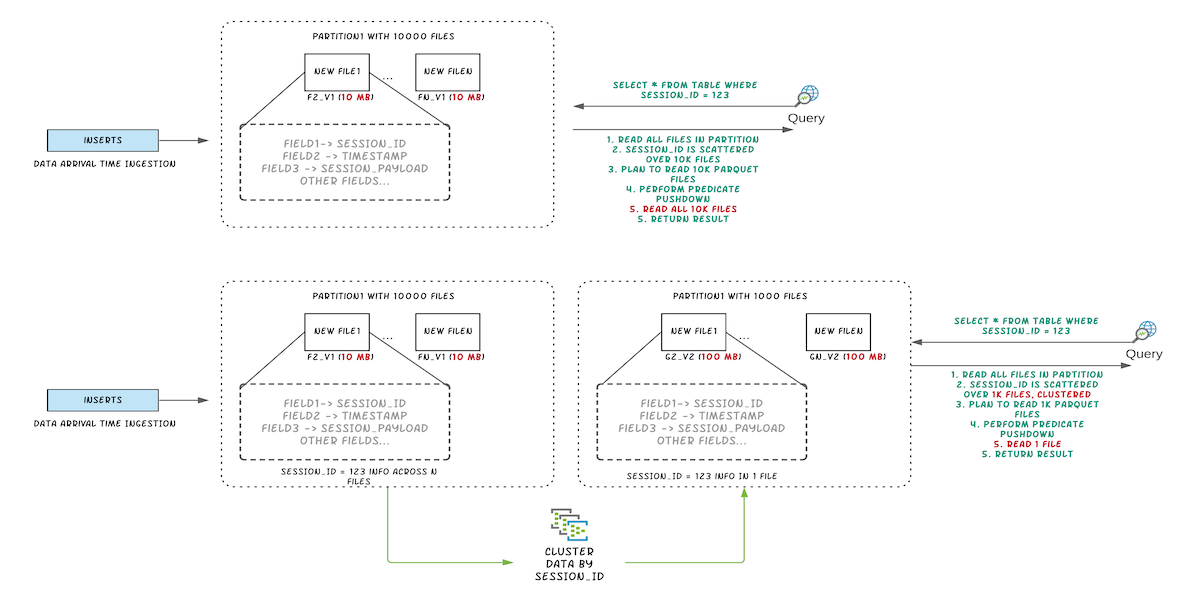
Optimize Data lake layout using Clustering in Apache Hudi
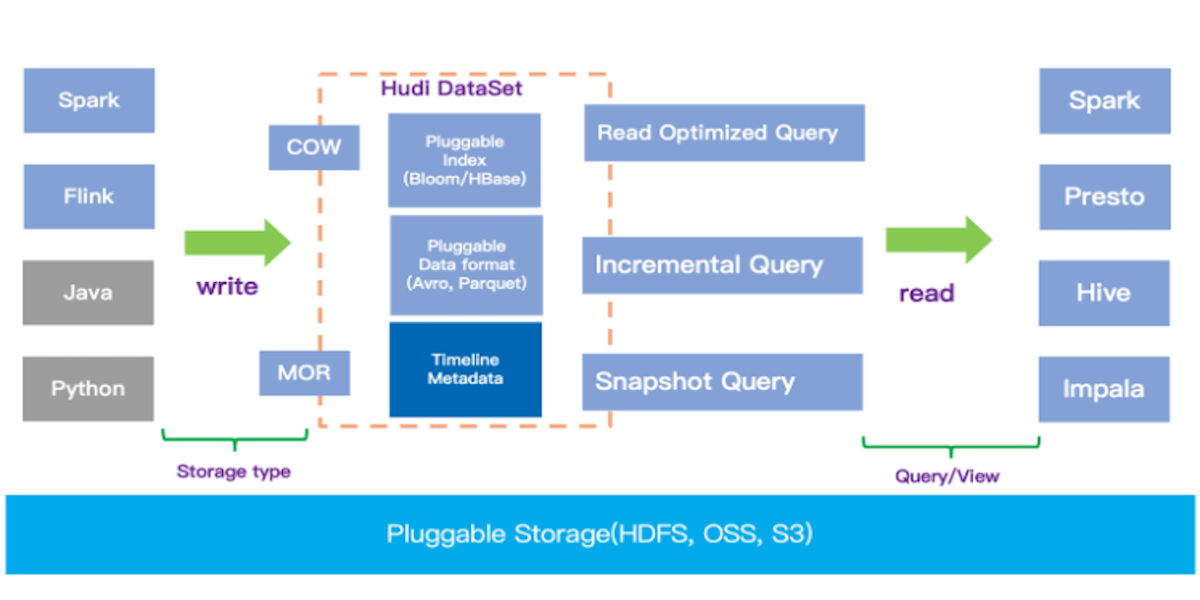
Building High-Performance Data Lake Using Apache Hudi and Alluxio at T3Go
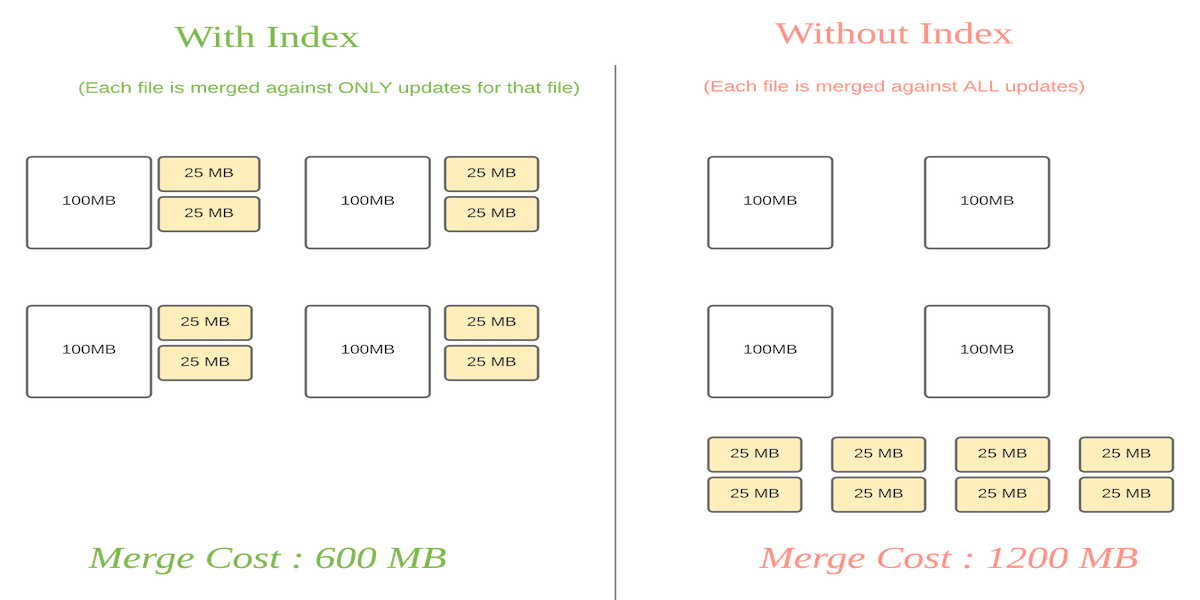
Employing the right indexes for fast updates, deletes in Apache Hudi
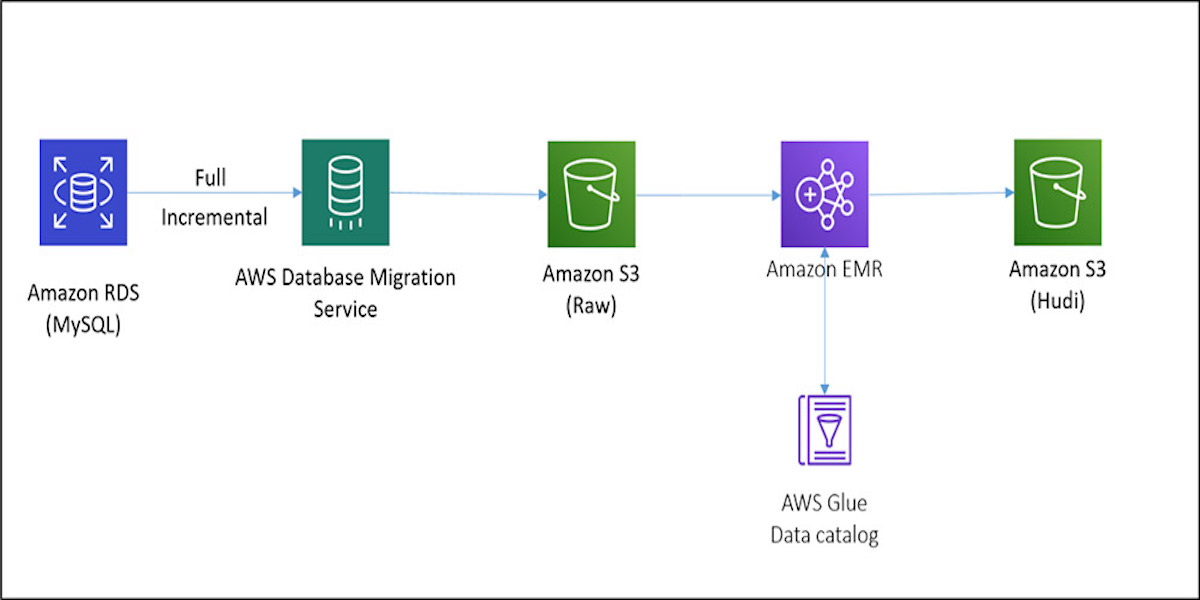
Apply record level changes from relational databases to Amazon S3 data lake using Apache Hudi on Amazon EMR and AWS Database Migration Service

Apache Hudi meets Apache Flink
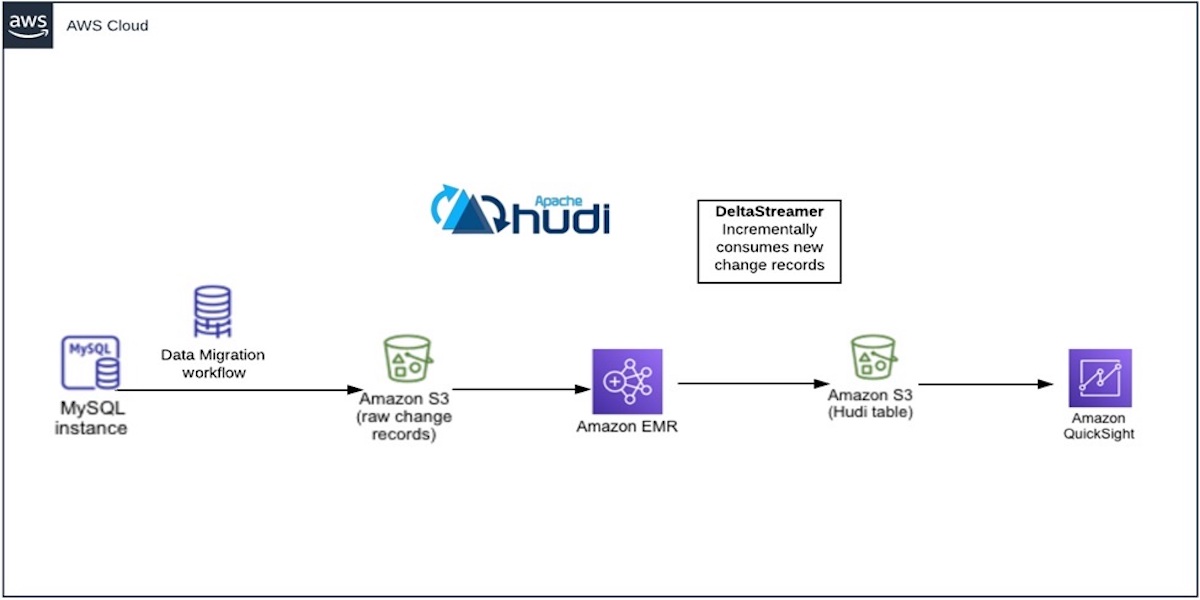
How nClouds Helps Accelerate Data Delivery with Apache Hudi on Amazon EMR
Ingest multiple tables using Hudi
Async Compaction Deployment Models
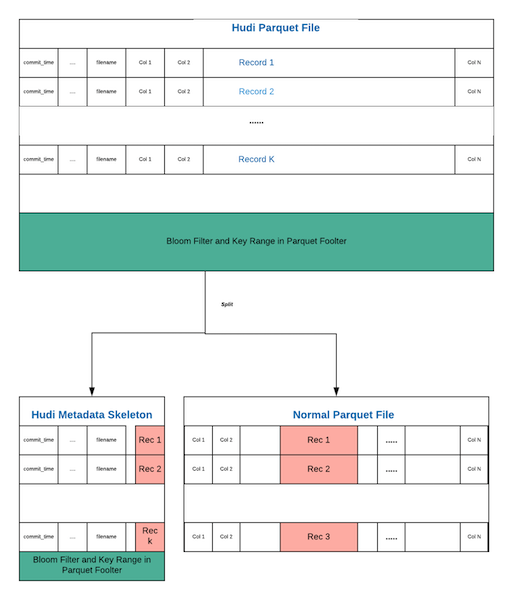
Efficient Migration of Large Parquet Tables to Apache Hudi
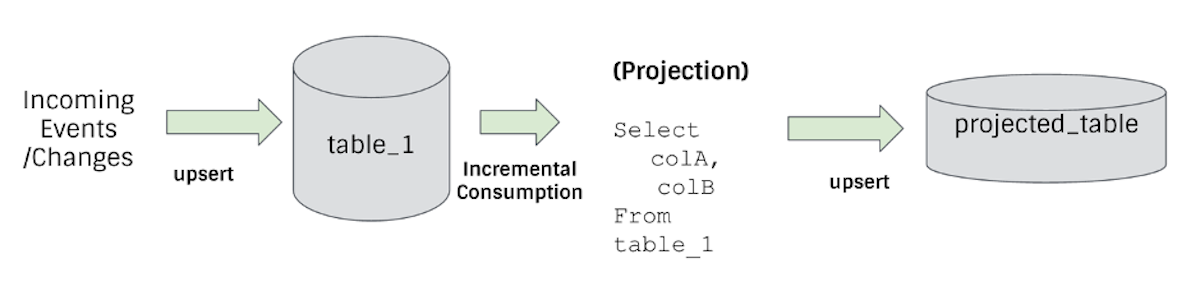
Incremental Processing on the Data Lake
Monitor Hudi metrics with Datadog
Apache Hudi Support on Apache Zeppelin
Export Hudi datasets as a copy or as different formats
