163 posts tagged with "blog"
View All Tags
How Doris + Hudi Turned the Impossible Into the Everyday
Why Walmart Chose Apache Hudi for Their Lakehouse
From Swamp to Stream: How Apache Hudi Transforms the Modern Data Lake
Integrating Apache Doris and Hudi for Data Querying and Migration
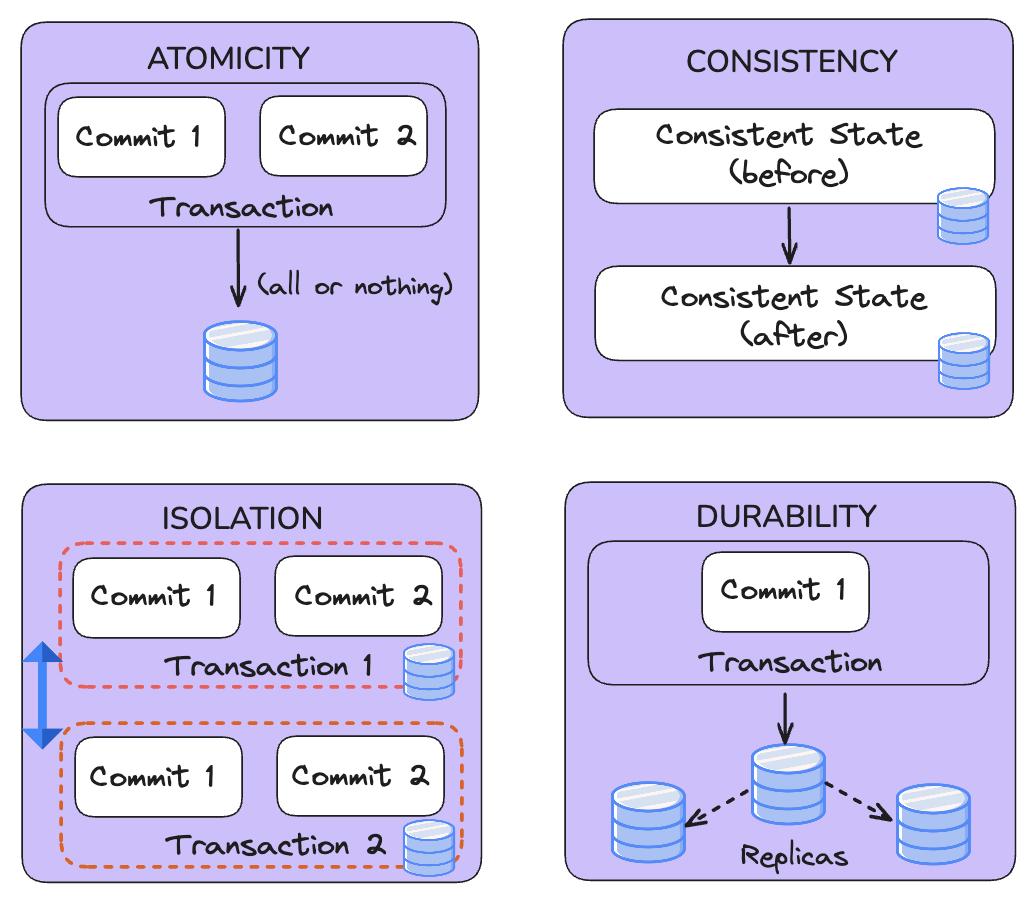
ACID Transactions in an Open Data Lakehouse

What is Clustering in an Open Data Lakehouse?
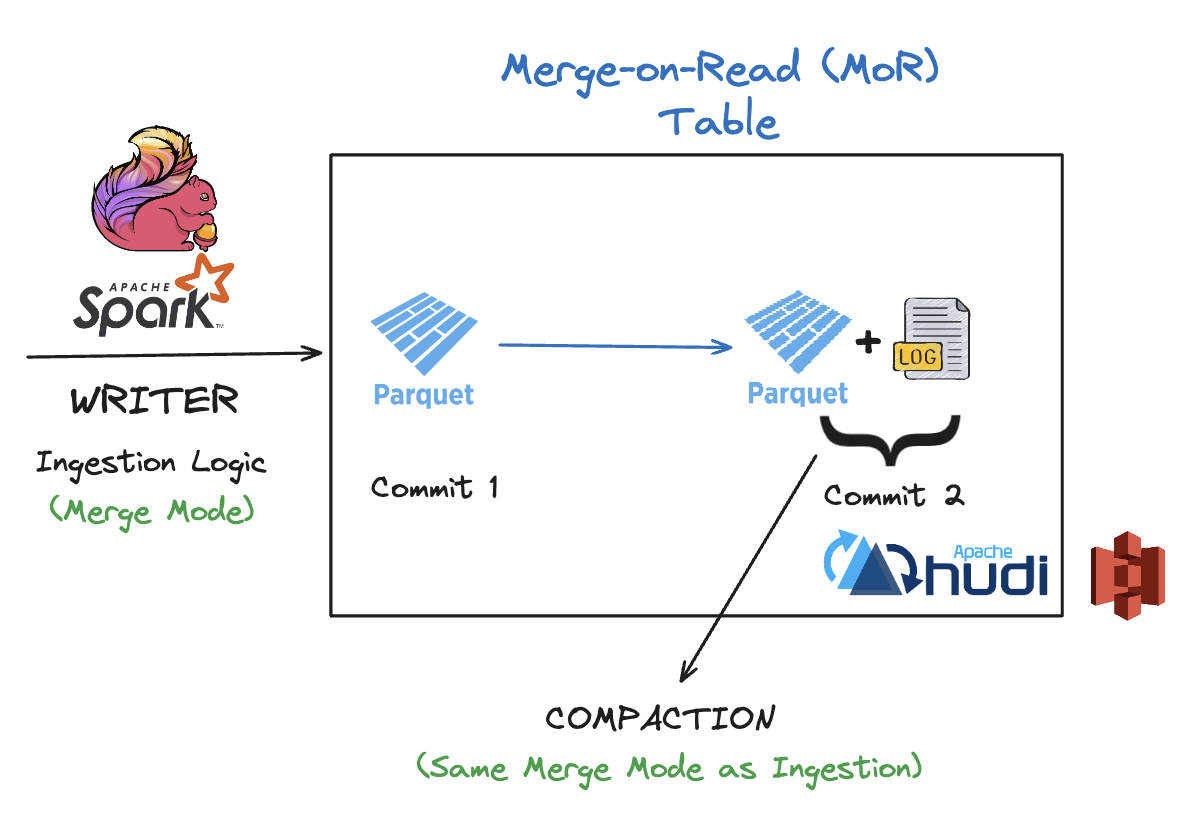
Data Deduplication Strategies in an Open Lakehouse Architecture
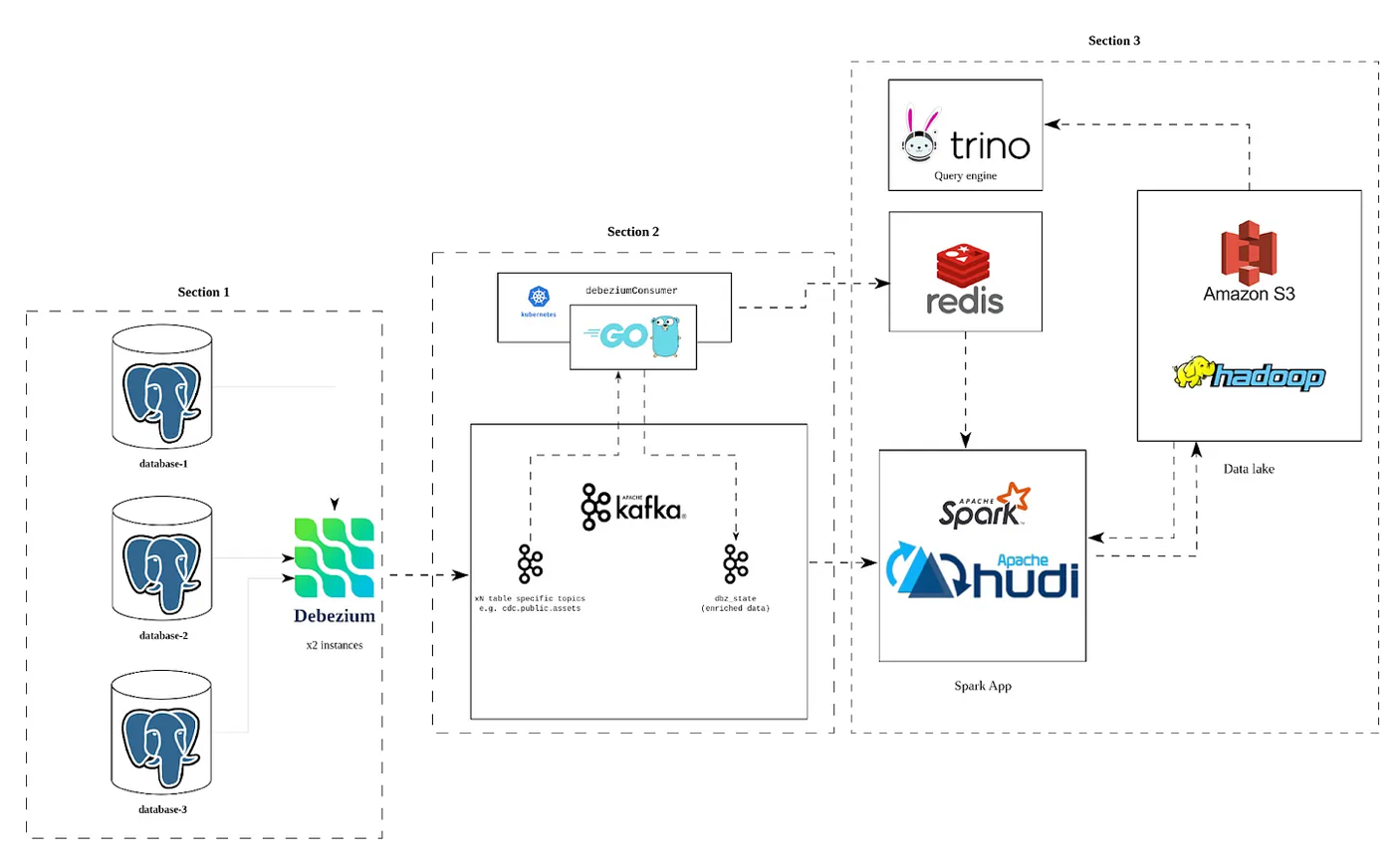
From Transactional Bottlenecks to Lightning-Fast Analytics

Building an Amazon Sales Analytics Pipeline with Apache Hudi on Databricks

From Transactional Bottlenecks to Lightning-Fast Analytics