Streaming Ingestion
DeltaStreamer
The HoodieDeltaStreamer utility (part of hudi-utilities-bundle) provides the way to ingest from different sources such as DFS or Kafka, with the following capabilities.
- Exactly once ingestion of new events from Kafka, incremental imports from Sqoop or output of
HiveIncrementalPulleror files under a DFS folder - Support json, avro or a custom record types for the incoming data
- Manage checkpoints, rollback & recovery
- Leverage Avro schemas from DFS or Confluent schema registry.
- Support for plugging in transformations
Command line options describe capabilities in more detail
[hoodie]$ spark-submit --class org.apache.hudi.utilities.deltastreamer.HoodieDeltaStreamer `ls packaging/hudi-utilities-bundle/target/hudi-utilities-bundle-*.jar` --help
Usage: <main class> [options]
Options:
--checkpoint
Resume Delta Streamer from this checkpoint.
--commit-on-errors
Commit even when some records failed to be written
Default: false
--compact-scheduling-minshare
Minshare for compaction as defined in
https://spark.apache.org/docs/latest/job-scheduling
Default: 0
--compact-scheduling-weight
Scheduling weight for compaction as defined in
https://spark.apache.org/docs/latest/job-scheduling
Default: 1
--continuous
Delta Streamer runs in continuous mode running source-fetch -> Transform
-> Hudi Write in loop
Default: false
--delta-sync-scheduling-minshare
Minshare for delta sync as defined in
https://spark.apache.org/docs/latest/job-scheduling
Default: 0
--delta-sync-scheduling-weight
Scheduling weight for delta sync as defined in
https://spark.apache.org/docs/latest/job-scheduling
Default: 1
--disable-compaction
Compaction is enabled for MoR table by default. This flag disables it
Default: false
--enable-hive-sync
Enable syncing to hive (Deprecated in favor of --enable-sync)
Default: false
--enable-sync
Enable syncing meta
Default: false
--filter-dupes
Should duplicate records from source be dropped/filtered out before
insert/bulk-insert
Default: false
--help, -h
--hoodie-conf
Any configuration that can be set in the properties file (using the CLI
parameter "--propsFilePath") can also be passed command line using this
parameter
Default: []
--max-pending-compactions
Maximum number of outstanding inflight/requested compactions. Delta Sync
will not happen unlessoutstanding compactions is less than this number
Default: 5
--min-sync-interval-seconds
the min sync interval of each sync in continuous mode
Default: 0
--op
Takes one of these values : UPSERT (default), INSERT (use when input is
purely new data/inserts to gain speed)
Default: UPSERT
Possible Values: [UPSERT, INSERT, BULK_INSERT]
--payload-class
subclass of HoodieRecordPayload, that works off a GenericRecord.
Implement your own, if you want to do something other than overwriting
existing value
Default: org.apache.hudi.common.model.OverwriteWithLatestAvroPayload
--props
path to properties file on localfs or dfs, with configurations for
hoodie client, schema provider, key generator and data source. For
hoodie client props, sane defaults are used, but recommend use to
provide basic things like metrics endpoints, hive configs etc. For
sources, referto individual classes, for supported properties.
Default: file:///Users/vinoth/bin/hoodie/src/test/resources/delta-streamer-config/dfs-source.properties
--schemaprovider-class
subclass of org.apache.hudi.utilities.schema.SchemaProvider to attach
schemas to input & target table data, built in options:
org.apache.hudi.utilities.schema.FilebasedSchemaProvider.Source (See
org.apache.hudi.utilities.sources.Source) implementation can implement
their own SchemaProvider. For Sources that return Dataset<Row>, the
schema is obtained implicitly. However, this CLI option allows
overriding the schemaprovider returned by Source.
--source-class
Subclass of org.apache.hudi.utilities.sources to read data. Built-in
options: org.apache.hudi.utilities.sources.{JsonDFSSource (default),
AvroDFSSource, AvroKafkaSource, CsvDFSSource, HiveIncrPullSource,
JdbcSource, JsonKafkaSource, ORCDFSSource, ParquetDFSSource,
S3EventsHoodieIncrSource, S3EventsSource, SqlSource}
Default: org.apache.hudi.utilities.sources.JsonDFSSource
--source-limit
Maximum amount of data to read from source. Default: No limit For e.g:
DFS-Source => max bytes to read, Kafka-Source => max events to read
Default: 9223372036854775807
--source-ordering-field
Field within source record to decide how to break ties between records
with same key in input data. Default: 'ts' holding unix timestamp of
record
Default: ts
--spark-master
spark master to use.
Default: local[2]
* --table-type
Type of table. COPY_ON_WRITE (or) MERGE_ON_READ
* --target-base-path
base path for the target hoodie table. (Will be created if did not exist
first time around. If exists, expected to be a hoodie table)
* --target-table
name of the target table in Hive
--transformer-class
subclass of org.apache.hudi.utilities.transform.Transformer. Allows
transforming raw source Dataset to a target Dataset (conforming to
target schema) before writing. Default : Not set. E:g -
org.apache.hudi.utilities.transform.SqlQueryBasedTransformer (which
allows a SQL query templated to be passed as a transformation function)
The tool takes a hierarchically composed property file and has pluggable interfaces for extracting data, key generation and providing schema. Sample configs for ingesting from kafka and dfs are
provided under hudi-utilities/src/test/resources/delta-streamer-config.
For e.g: once you have Confluent Kafka, Schema registry up & running, produce some test data using (impressions.avro provided by schema-registry repo)
[confluent-5.0.0]$ bin/ksql-datagen schema=../impressions.avro format=avro topic=impressions key=impressionid
and then ingest it as follows.
[hoodie]$ spark-submit --class org.apache.hudi.utilities.deltastreamer.HoodieDeltaStreamer `ls packaging/hudi-utilities-bundle/target/hudi-utilities-bundle-*.jar` \
--props file://${PWD}/hudi-utilities/src/test/resources/delta-streamer-config/kafka-source.properties \
--schemaprovider-class org.apache.hudi.utilities.schema.SchemaRegistryProvider \
--source-class org.apache.hudi.utilities.sources.AvroKafkaSource \
--source-ordering-field impresssiontime \
--target-base-path file:\/\/\/tmp/hudi-deltastreamer-op \
--target-table uber.impressions \
--op BULK_INSERT
In some cases, you may want to migrate your existing table into Hudi beforehand. Please refer to migration guide.
From 0.11.0 release, we start to provide a new hudi-utilities-slim-bundle which aims to exclude dependencies that can
cause conflicts and compatibility issues with different versions of Spark. The hudi-utilities-slim-bundle should be
used along with a Hudi Spark bundle corresponding the Spark version used to make utilities work with Spark, e.g.,
--packages org.apache.hudi:hudi-utilities-slim-bundle_2.12:0.11.0,org.apache.hudi:hudi-spark3.1-bundle_2.12:0.11.0,
if using hudi-utilities-bundle solely to run HoodieDeltaStreamer in Spark encounters compatibility issues.
MultiTableDeltaStreamer
HoodieMultiTableDeltaStreamer, a wrapper on top of HoodieDeltaStreamer, enables one to ingest multiple tables at a single go into hudi datasets. Currently it only supports sequential processing of tables to be ingested and COPY_ON_WRITE storage type. The command line options for HoodieMultiTableDeltaStreamer are pretty much similar to HoodieDeltaStreamer with the only exception that you are required to provide table wise configs in separate files in a dedicated config folder. The following command line options are introduced
* --config-folder
the path to the folder which contains all the table wise config files
--base-path-prefix
this is added to enable users to create all the hudi datasets for related tables under one path in FS. The datasets are then created under the path - <base_path_prefix>/<database>/<table_to_be_ingested>. However you can override the paths for every table by setting the property hoodie.deltastreamer.ingestion.targetBasePath
The following properties are needed to be set properly to ingest data using HoodieMultiTableDeltaStreamer.
hoodie.deltastreamer.ingestion.tablesToBeIngested
comma separated names of tables to be ingested in the format <database>.<table>, for example db1.table1,db1.table2
hoodie.deltastreamer.ingestion.targetBasePath
if you wish to ingest a particular table in a separate path, you can mention that path here
hoodie.deltastreamer.ingestion.<database>.<table>.configFile
path to the config file in dedicated config folder which contains table overridden properties for the particular table to be ingested.
Sample config files for table wise overridden properties can be found under hudi-utilities/src/test/resources/delta-streamer-config. The command to run HoodieMultiTableDeltaStreamer is also similar to how you run HoodieDeltaStreamer.
[hoodie]$ spark-submit --class org.apache.hudi.utilities.deltastreamer.HoodieMultiTableDeltaStreamer `ls packaging/hudi-utilities-bundle/target/hudi-utilities-bundle-*.jar` \
--props file://${PWD}/hudi-utilities/src/test/resources/delta-streamer-config/kafka-source.properties \
--config-folder file://tmp/hudi-ingestion-config \
--schemaprovider-class org.apache.hudi.utilities.schema.SchemaRegistryProvider \
--source-class org.apache.hudi.utilities.sources.AvroKafkaSource \
--source-ordering-field impresssiontime \
--base-path-prefix file:\/\/\/tmp/hudi-deltastreamer-op \
--target-table uber.impressions \
--op BULK_INSERT
For detailed information on how to configure and use HoodieMultiTableDeltaStreamer, please refer blog section.
Concurrency Control
The HoodieDeltaStreamer utility (part of hudi-utilities-bundle) provides ways to ingest from different sources such as DFS or Kafka, with the following capabilities.
Using optimistic_concurrency_control via delta streamer requires adding the above configs to the properties file that can be passed to the job. For example below, adding the configs to kafka-source.properties file and passing them to deltastreamer will enable optimistic concurrency. A deltastreamer job can then be triggered as follows:
[hoodie]$ spark-submit --class org.apache.hudi.utilities.deltastreamer.HoodieDeltaStreamer `ls packaging/hudi-utilities-bundle/target/hudi-utilities-bundle-*.jar` \
--props file://${PWD}/hudi-utilities/src/test/resources/delta-streamer-config/kafka-source.properties \
--schemaprovider-class org.apache.hudi.utilities.schema.SchemaRegistryProvider \
--source-class org.apache.hudi.utilities.sources.AvroKafkaSource \
--source-ordering-field impresssiontime \
--target-base-path file:\/\/\/tmp/hudi-deltastreamer-op \
--target-table uber.impressions \
--op BULK_INSERT
Read more in depth about concurrency control in the concurrency control concepts section
Checkpointing
HoodieDeltaStreamer uses checkpoints to keep track of what data has been read already so it can resume without needing to reprocess all data.
When using a Kafka source, the checkpoint is the Kafka Offset
When using a DFS source, the checkpoint is the 'last modified' timestamp of the latest file read.
Checkpoints are saved in the .hoodie commit file as deltastreamer.checkpoint.key.
If you need to change the checkpoints for reprocessing or replaying data you can use the following options:
--checkpointwill setdeltastreamer.checkpoint.reset_keyin the commit file to overwrite the current checkpoint.--source-limitwill set a maximum amount of data to read from the source. For DFS sources, this is max # of bytes read. For Kafka, this is the max # of events to read.
Schema Providers
By default, Spark will infer the schema of the source and use that inferred schema when writing to a table. If you need to explicitly define the schema you can use one of the following Schema Providers below.
Schema Registry Provider
You can obtain the latest schema from an online registry. You pass a URL to the registry and if needed, you can also
pass userinfo and credentials in the url like: https://foo:bar@schemaregistry.org The credentials are then extracted
and are set on the request as an Authorization Header.
When fetching schemas from a registry, you can specify both the source schema and the target schema separately.
| Config | Description | Example |
|---|---|---|
| hoodie.deltastreamer.schemaprovider.registry.url | The schema of the source you are reading from | https://foo:bar@schemaregistry.org |
| hoodie.deltastreamer.schemaprovider.registry.targetUrl | The schema of the target you are writing to | https://foo:bar@schemaregistry.org |
The above configs are passed to DeltaStreamer spark-submit command like:
--hoodie-conf hoodie.deltastreamer.schemaprovider.registry.url=https://foo:bar@schemaregistry.org
JDBC Schema Provider
You can obtain the latest schema through a JDBC connection.
| Config | Description | Example |
|---|---|---|
| hoodie.deltastreamer.schemaprovider.source.schema.jdbc.connection.url | The JDBC URL to connect to. You can specify source specific connection properties in the URL | jdbc:postgresql://localhost/test?user=fred&password=secret |
| hoodie.deltastreamer.schemaprovider.source.schema.jdbc.driver.type | The class name of the JDBC driver to use to connect to this URL | org.h2.Driver |
| hoodie.deltastreamer.schemaprovider.source.schema.jdbc.username | username for the connection | fred |
| hoodie.deltastreamer.schemaprovider.source.schema.jdbc.password | password for the connection | secret |
| hoodie.deltastreamer.schemaprovider.source.schema.jdbc.dbtable | The table with the schema to reference | test_database.test1_table or test1_table |
| hoodie.deltastreamer.schemaprovider.source.schema.jdbc.timeout | The number of seconds the driver will wait for a Statement object to execute to the given number of seconds. Zero means there is no limit. In the write path, this option depends on how JDBC drivers implement the API setQueryTimeout, e.g., the h2 JDBC driver checks the timeout of each query instead of an entire JDBC batch. It defaults to 0. | 0 |
| hoodie.deltastreamer.schemaprovider.source.schema.jdbc.nullable | If true, all columns are nullable | true |
The above configs are passed to DeltaStreamer spark-submit command like:
--hoodie-conf hoodie.deltastreamer.jdbcbasedschemaprovider.connection.url=jdbc:postgresql://localhost/test?user=fred&password=secret
File Based Schema Provider
You can use a .avsc file to define your schema. You can then point to this file on DFS as a schema provider.
| Config | Description | Example |
|---|---|---|
| hoodie.deltastreamer.schemaprovider.source.schema.file | The schema of the source you are reading from | example schema file |
| hoodie.deltastreamer.schemaprovider.target.schema.file | The schema of the target you are writing to | example schema file |
Hive Schema Provider
You can use hive tables to fetch source and target schema.
| Config | Description |
|---|---|
| hoodie.deltastreamer.schemaprovider.source.schema.hive.database | Hive database from where source schema can be fetched |
| hoodie.deltastreamer.schemaprovider.source.schema.hive.table | Hive table from where source schema can be fetched |
| hoodie.deltastreamer.schemaprovider.target.schema.hive.database | Hive database from where target schema can be fetched |
| hoodie.deltastreamer.schemaprovider.target.schema.hive.table | Hive table from where target schema can be fetched |
Schema Provider with Post Processor
The SchemaProviderWithPostProcessor, will extract the schema from one of the previously mentioned Schema Providers and then will apply a post processor to change the schema before it is used. You can write your own post processor by extending this class: https://github.com/apache/hudi/blob/master/hudi-utilities/src/main/java/org/apache/hudi/utilities/schema/SchemaPostProcessor.java
Sources
Hoodie DeltaStreamer can read data from a wide variety of sources. The following are a list of supported sources:
Distributed File System (DFS)
See the storage configurations page to see some examples of DFS applications Hudi can read from. The following are the supported file formats Hudi can read/write with on DFS Sources. (Note: you can still use Spark/Flink readers to read from other formats and then write data as Hudi format.)
- CSV
- AVRO
- JSON
- PARQUET
- ORC
- HUDI
For DFS sources the following behaviors are expected:
- For JSON DFS source, you always need to set a schema. If the target Hudi table follows the same schema as from the source file, you just need to set the source schema. If not, you need to set schemas for both source and target.
HoodieDeltaStreamerreads the files under the source base path (hoodie.deltastreamer.source.dfs.root) directly, and it won't use the partition paths under this base path as fields of the dataset. Detailed examples can be found here.
Kafka
Hudi can read directly from Kafka clusters. See more details on HoodieDeltaStreamer to learn how to setup streaming ingestion with exactly once semantics, checkpointing, and plugin transformations. The following formats are supported when reading data from Kafka:
- AVRO
- JSON
S3 Events
AWS S3 storage provides an event notification service which will post notifications when certain events happen in your S3 bucket: https://docs.aws.amazon.com/AmazonS3/latest/userguide/NotificationHowTo.html AWS will put these events in a Simple Queue Service (SQS). Apache Hudi provides an S3EventsSource that can read from SQS to trigger/processing of new or changed data as soon as it is available on S3.
Setup
- Enable S3 Event Notifications https://docs.aws.amazon.com/AmazonS3/latest/userguide/NotificationHowTo.html
- Download the aws-java-sdk-sqs jar.
- Find the queue URL and Region to set these configurations:
- hoodie.deltastreamer.s3.source.queue.url=https://sqs.us-west-2.amazonaws.com/queue/url
- hoodie.deltastreamer.s3.source.queue.region=us-west-2
- start the S3EventsSource and S3EventsHoodieIncrSource using the HoodieDeltaStreamer utility as shown in sample commands below:
Insert code sample from this blog: https://hudi.apache.org/blog/2021/08/23/s3-events-source/#configuration-and-setup
JDBC Source
Hudi can read from a JDBC source with a full fetch of a table, or Hudi can even read incrementally with checkpointing from a JDBC source.
| Config | Description | Example |
|---|---|---|
| hoodie.deltastreamer.jdbc.url | URL of the JDBC connection | jdbc:postgresql://localhost/test |
| hoodie.deltastreamer.jdbc.user | User to use for authentication of the JDBC connection | fred |
| hoodie.deltastreamer.jdbc.password | Password to use for authentication of the JDBC connection | secret |
| hoodie.deltastreamer.jdbc.password.file | If you prefer to use a password file for the connection | |
| hoodie.deltastreamer.jdbc.driver.class | Driver class to use for the JDBC connection | |
| hoodie.deltastreamer.jdbc.table.name | my_table | |
| hoodie.deltastreamer.jdbc.table.incr.column.name | If run in incremental mode, this field will be used to pull new data incrementally | |
| hoodie.deltastreamer.jdbc.incr.pull | Will the JDBC connection perform an incremental pull? | |
| hoodie.deltastreamer.jdbc.extra.options. | How you pass extra configurations that would normally by specified as spark.read.option() | hoodie.deltastreamer.jdbc.extra.options.fetchSize=100 hoodie.deltastreamer.jdbc.extra.options.upperBound=1 hoodie.deltastreamer.jdbc.extra.options.lowerBound=100 |
| hoodie.deltastreamer.jdbc.storage.level | Used to control the persistence level | Default = MEMORY_AND_DISK_SER |
| hoodie.deltastreamer.jdbc.incr.fallback.to.full.fetch | Boolean which if set true makes an incremental fetch fallback to a full fetch if there is any error in the incremental read | FALSE |
SQL Source
SQL Source that reads from any table, used mainly for backfill jobs which will process specific partition dates.
This won't update the deltastreamer.checkpoint.key to the processed commit, instead it will fetch the latest successful
checkpoint key and set that value as this backfill commits checkpoint so that it won't interrupt the regular incremental
processing. To fetch and use the latest incremental checkpoint, you need to also set this hoodie_conf for deltastremer
jobs: hoodie.write.meta.key.prefixes = 'deltastreamer.checkpoint.key'
Spark SQL should be configured using this hoodie config: hoodie.deltastreamer.source.sql.sql.query = 'select * from source_table'
Flink Ingestion
CDC Ingestion
CDC(change data capture) keep track of the data changes evolving in a source system so a downstream process or system can action that change. We recommend two ways for syncing CDC data into Hudi:
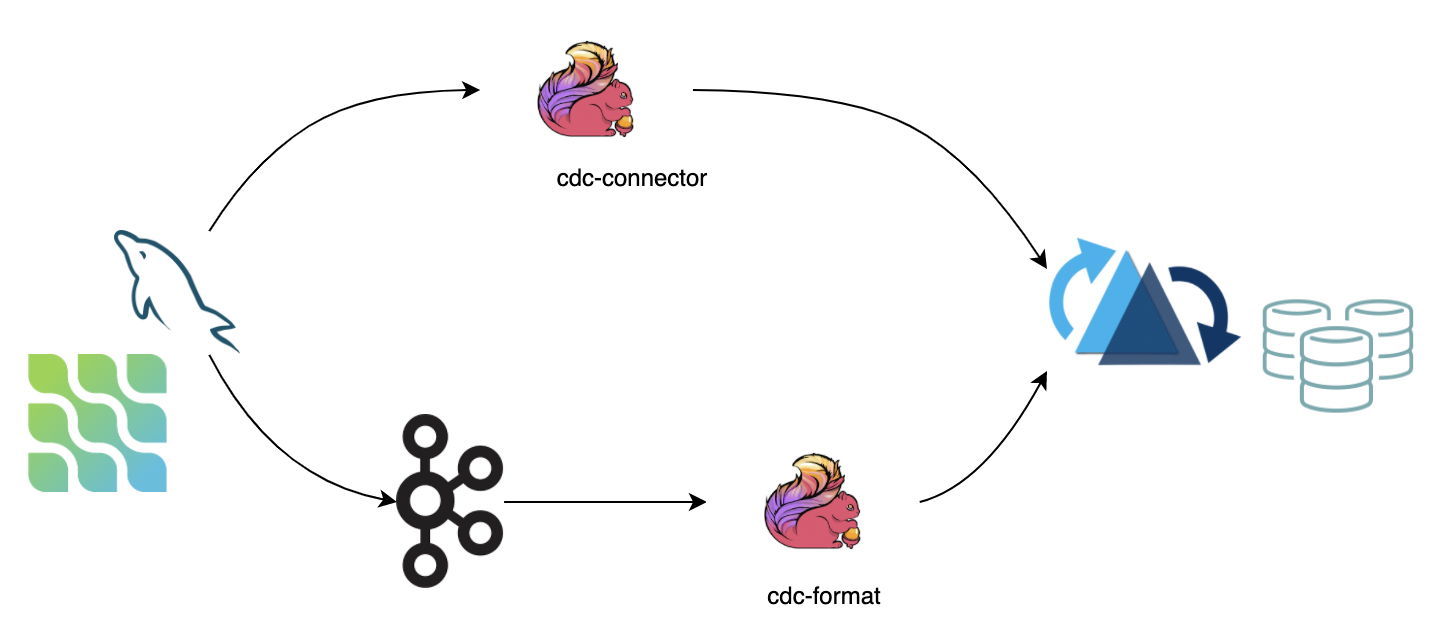
- Using the Ververica flink-cdc-connectors directly connect to DB Server to sync the binlog data into Hudi. The advantage is that it does not rely on message queues, but the disadvantage is that it puts pressure on the db server;
- Consume data from a message queue (for e.g, the Kafka) using the flink cdc format, the advantage is that it is highly scalable, but the disadvantage is that it relies on message queues.
- If the upstream data cannot guarantee the order, you need to specify option
write.precombine.fieldexplicitly;
Bulk Insert
For the demand of snapshot data import. If the snapshot data comes from other data sources, use the bulk_insert mode to quickly
import the snapshot data into Hudi.
bulk_insert eliminates the serialization and data merging. The data deduplication is skipped, so the user need to guarantee the uniqueness of the data.
bulk_insert is more efficient in the batch execution mode. By default, the batch execution mode sorts the input records
by the partition path and writes these records to Hudi, which can avoid write performance degradation caused by
frequent file handle switching.
The parallelism of bulk_insert is specified by write.tasks. The parallelism will affect the number of small files.
In theory, the parallelism of bulk_insert is the number of buckets (In particular, when each bucket writes to maximum file size, it
will rollover to the new file handle. Finally, the number of files >= write.bucket_assign.tasks.
Options
| Option Name | Required | Default | Remarks |
|---|---|---|---|
write.operation | true | upsert | Setting as bulk_insert to open this function |
write.tasks | false | 4 | The parallelism of bulk_insert, the number of files >= write.bucket_assign.tasks |
write.bulk_insert.shuffle_input | false | true | Whether to shuffle data according to the input field before writing. Enabling this option will reduce the number of small files, but there may be a risk of data skew |
write.bulk_insert.sort_input | false | true | Whether to sort data according to the input field before writing. Enabling this option will reduce the number of small files when a write task writes multiple partitions |
write.sort.memory | false | 128 | Available managed memory of sort operator. default 128 MB |
Index Bootstrap
For the demand of snapshot data + incremental data import. If the snapshot data already insert into Hudi by bulk insert.
User can insert incremental data in real time and ensure the data is not repeated by using the index bootstrap function.
If you think this process is very time-consuming, you can add resources to write in streaming mode while writing snapshot data,
and then reduce the resources to write incremental data (or open the rate limit function).
Options
| Option Name | Required | Default | Remarks |
|---|---|---|---|
index.bootstrap.enabled | true | false | When index bootstrap is enabled, the remain records in Hudi table will be loaded into the Flink state at one time |
index.partition.regex | false | * | Optimize option. Setting regular expressions to filter partitions. By default, all partitions are loaded into flink state |
How To Use
CREATE TABLEcreates a statement corresponding to the Hudi table. Note that thetable.typemust be correct.- Setting
index.bootstrap.enabled=trueto enable the index bootstrap function. - Setting Flink checkpoint failure tolerance in
flink-conf.yaml:execution.checkpointing.tolerable-failed-checkpoints = n(depending on Flink checkpoint scheduling times). - Waiting until the first checkpoint succeeds, indicating that the index bootstrap completed.
- After the index bootstrap completed, user can exit and save the savepoint (or directly use the externalized checkpoint).
- Restart the job, setting
index.bootstrap.enableasfalse.
- Index bootstrap is blocking, so checkpoint cannot be completed during index bootstrap.
- Index bootstrap triggers by the input data. User need to ensure that there is at least one record in each partition.
- Index bootstrap executes concurrently. User can search in log by
finish loading the index under partitionandLoad record form fileto observe the progress of index bootstrap. - The first successful checkpoint indicates that the index bootstrap completed. There is no need to load the index again when recovering from the checkpoint.
Changelog Mode
Hudi can keep all the intermediate changes (I / -U / U / D) of messages, then consumes through stateful computing of flink to have a near-real-time data warehouse ETL pipeline (Incremental computing). Hudi MOR table stores messages in the forms of rows, which supports the retention of all change logs (Integration at the format level). All changelog records can be consumed with Flink streaming reader.
Options
| Option Name | Required | Default | Remarks |
|---|---|---|---|
changelog.enabled | false | false | It is turned off by default, to have the upsert semantics, only the merged messages are ensured to be kept, intermediate changes may be merged. Setting to true to support consumption of all changes |
Batch (Snapshot) read still merge all the intermediate changes, regardless of whether the format has stored the intermediate changelog messages.
After setting changelog.enable as true, the retention of changelog records are only best effort: the asynchronous compaction task will merge the changelog records into one record, so if the
stream source does not consume timely, only the merged record for each key can be read after compaction. The solution is to reserve some buffer time for the reader by adjusting the compaction strategy, such as
the compaction options: compaction.delta_commits and compaction.delta_seconds.
Append Mode
If INSERT operation is used for ingestion, for COW table, there is no merging of small files by default; for MOR table, the small file strategy is applied always: MOR appends delta records to log files.
The small file strategy lead to performance degradation. If you want to apply the behavior of file merge for COW table, turns on option write.insert.cluster, there is no record key combining by the way.
Options
| Option Name | Required | Default | Remarks |
|---|---|---|---|
write.insert.cluster | false | false | Whether to merge small files while ingesting, for COW table, open the option to enable the small file merging strategy(no deduplication for keys but the throughput will be affected) |
Rate Limit
There are many use cases that user put the full history data set onto the message queue together with the realtime incremental data. Then they consume the data from the queue into the hudi from the earliest offset using flink. Consuming history data set has these characteristics: 1). The instant throughput is huge 2). It has serious disorder (with random writing partitions). It will lead to degradation of writing performance and throughput glitches. For this case, the speed limit parameter can be turned on to ensure smooth writing of the flow.
Options
| Option Name | Required | Default | Remarks |
|---|---|---|---|
write.rate.limit | false | 0 | Default disable the rate limit |
Streaming Query
By default, the hoodie table is read as batch, that is to read the latest snapshot data set and returns. Turns on the streaming read
mode by setting option read.streaming.enabled as true. Sets up option read.start-commit to specify the read start offset, specifies the
value as earliest if you want to consume all the history data set.
Options
| Option Name | Required | Default | Remarks |
|---|---|---|---|
read.streaming.enabled | false | false | Specify true to read as streaming |
read.start-commit | false | the latest commit | Start commit time in format 'yyyyMMddHHmmss', use earliest to consume from the start commit |
read.streaming.skip_compaction | false | false | Whether to skip compaction commits while reading, generally for two purposes: 1) Avoid consuming duplications from the compaction instants 2) When change log mode is enabled, to only consume change logs for right semantics. |
clean.retain_commits | false | 10 | The max number of commits to retain before cleaning, when change log mode is enabled, tweaks this option to adjust the change log live time. For example, the default strategy keeps 50 minutes of change logs if the checkpoint interval is set up as 5 minutes. |
When option read.streaming.skip_compaction turns on and the streaming reader lags behind by commits of number
clean.retain_commits, the data loss may occur. The compaction keeps the original instant time as the per-record metadata,
the streaming reader would read and skip the whole base files if the log has been consumed. For efficiency, option read.streaming.skip_compaction
is till suggested being true.
Incremental Query
There are 3 use cases for incremental query:
- Streaming query: specify the start commit with option
read.start-commit; - Batch query: specify the start commit with option
read.start-commitand end commit with optionread.end-commit, the interval is a closed one: both start commit and end commit are inclusive; - TimeTravel: consume as batch for an instant time, specify the
read.end-commitis enough because the start commit is latest by default.
Options
| Option Name | Required | Default | Remarks |
|---|---|---|---|
read.start-commit | false | the latest commit | Specify earliest to consume from the start commit |
read.end-commit | false | the latest commit | -- |
Kafka Connect Sink
If you want to perform streaming ingestion into Hudi format similar to HoodieDeltaStreamer, but you don't want to depend on Spark, try out the new experimental release of Hudi Kafka Connect Sink. Read the ReadMe for full documentation.