Introducing Hudi's Non-blocking Concurrency Control for streaming, high-frequency writes

Non-blocking Concurrency Control (NBCC) is a multi-writer concurrency model introduced in Apache Hudi 1.0 that lets multiple streaming writers ingest into the same table simultaneously, without any conflict-resolution overhead at write time - conflicts are instead resolved later by the compaction service and query readers, while preserving event-time ordering semantics. This post explains the storage layout and timeline changes that make NBCC possible, walks through its design, and shows a working Flink SQL demo.
See the concurrency control docs for configuration details, the survey of concurrency control across open table formats for how NBCC fits alongside OCC and MVCC, and Lakehouse Concurrency Control: Are we too optimistic? for the motivation behind moving past OCC.
Introduction
In streaming ingestion scenarios, there are plenty of use cases that require concurrent ingestion from multiple streaming sources. The user can union all the upstream source inputs into one downstream table to collect the records for unified access across federated queries. Another very common scenario is multiple stream sources joined together to supplement dimensions of the records to build a wide-dimension table where each source stream is taking records with partial table schema fields. Common and strong demand for multi-stream concurrent ingestion has always been there. The Hudi community has collected so many feedbacks from users ever since the day Hudi supported streaming ingestion and processing.
Starting from Hudi 1.0.0, we are thrilled to announce a new general-purpose concurrency model for Apache Hudi - the Non-blocking Concurrency Control (NBCC)- aimed at the stream processing or high-contention/frequent writing scenarios. In contrast to Optimistic Concurrency Control, where writers abort the transaction if there is a hint of contention, this innovation allows multiple streaming writes to the same Hudi table without any overhead of conflict resolution, while keeping the semantics of event-time ordering found in streaming systems, along with asynchronous table service such as compaction, archiving and cleaning.
NBCC works seamlessly without any new infrastructure or operational overhead. In the subsequent sections of this blog, we will give a brief introduction to Hudi's internals about the data file layout and TrueTime semantics for time generation, a pre-requisite for discussing NBCC. Following that, we will delve into the design and workflows of NBCC, and then a simple SQL demo to show the NBCC related config options. The blog will conclude with insights into future work for NBCC.
Older Design
It's important to understand the Hudi storage layout and it evolves/manages data versions. In older release before 1.0.0,
Hudi organizes the data files with units as FileGroup. Each file group contains multiple FileSlices. Every compaction on this file group generates a new file slice.
Each file slice may comprise an optional base file(columnar file format like Apache Parquet or ORC) and multiple log files(row file format in Apache Avro or Parquet).
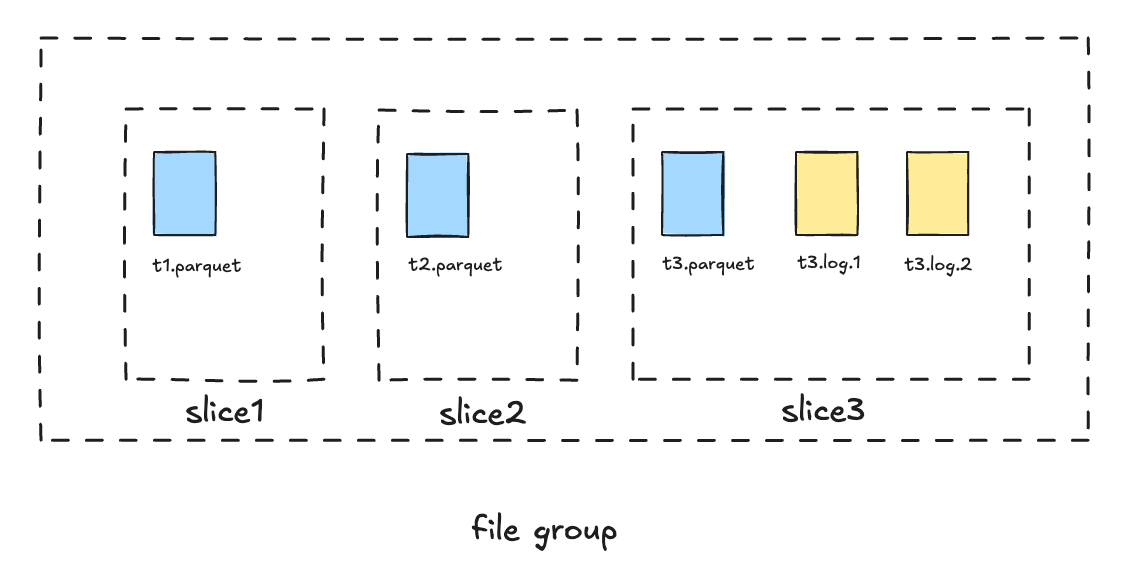
The timestamp in the base file name is the instant time of the compaction that writes it, it is also called as "requested instant time" in Hudi's notion. The timestamp in the log file name is the same timestamp as the current file slice base instant time. Data files with the same instant time belong to one file slice. In effect, a file group represented a linear ordered sequence of base files (checkpoints) followed by logs files (deltas), followed by base files (checkpoints).
The instant time naming convention in log files becomes a hash limitation in concurrency mode. Each log file contains incremental changes from multiple commits. Each writer needs to query the file layout to get the base instant time and figure out the full file name before flushing the records. A more severe problem is the base instant time can be variable with the async compaction pushing forward. In order to make the base instant time deterministic for the log writers, Hudi forces the schedule sequence between a write commit and compaction scheduling: a compaction can be scheduled only if there is no ongoing ingestion into the Hudi table. Without this, a log file can be written with a wrong base instant time which could introduce data loss. This means a compaction scheduling could block all the writers in concurrency mode.
NBCC Design
In order to resolve these pains, since 1.0.0, Hudi introduces a new storage layout based on both requested and completion times of actions, viewing them as an interval. Each commit in 1.x Hudi has two important notions of time: instant time(or requested time) and completion time. All the generated timestamp are globally monotonically increasing. Instead of putting the base instant time in the log file name, Hudi now just uses the requested instant time of the write. During file slicing, Hudi queries the completion time for each log file with the instant time, and we have a new rule for file slicing:
A log file belongs to the file slice with the maximum base requested time smaller than(or equals with) it's completion time.[^1]
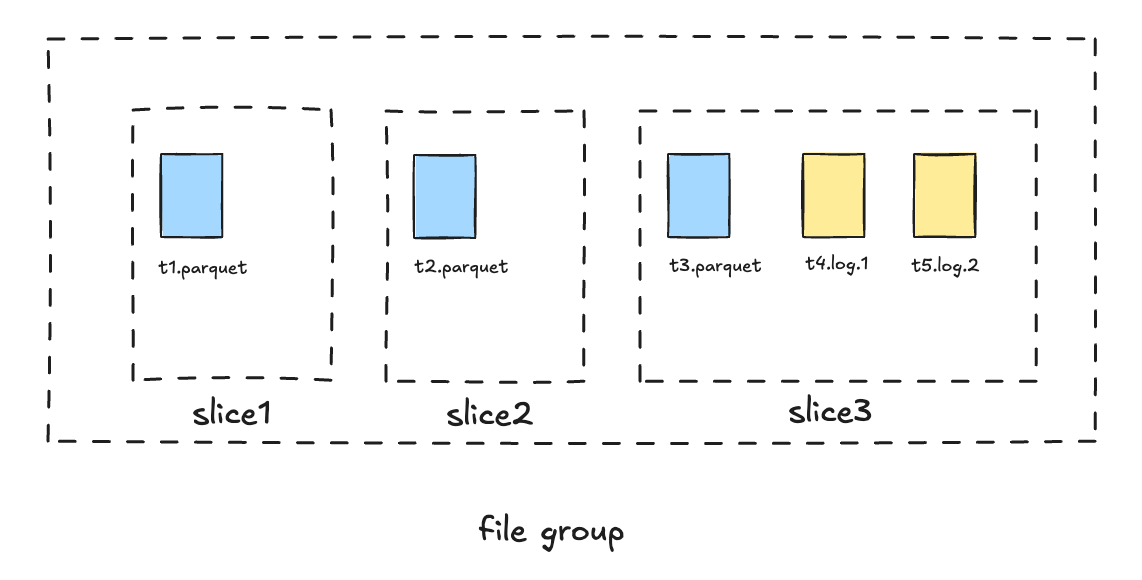
With the flexibility of the new file layout, the overhead of querying base instant time is eliminated for log writers and a compaction can be scheduled anywhere with any instant time. See RFC-66 for more.
True Time API
In order to ensure the monotonicity of timestamp generation, Hudi introduces the "TrueTime API" since 1.x release. Basically there are two ways to make the time generation monotonically increasing, inline with TrueTime semantics:
- A global lock to guard the time generation with mutex, along with a wait for an estimated max allowed clock skew on distributed hosts;
- Globally synchronized time generation service, e.g. Google Spanner Time Service, the service itself can ensure the monotonicity.
Hudi now implements the "TrueTime" semantics with the first solution, a configurable max waiting time is supported.
LSM timeline
The new file layout requires efficient queries from instant time to get the completion time. Hudi re-implements the archived timeline since 1.x, the new archived timeline data files are organized as an LSM tree to support fast time range filtering queries with instant time data-skipping on it.
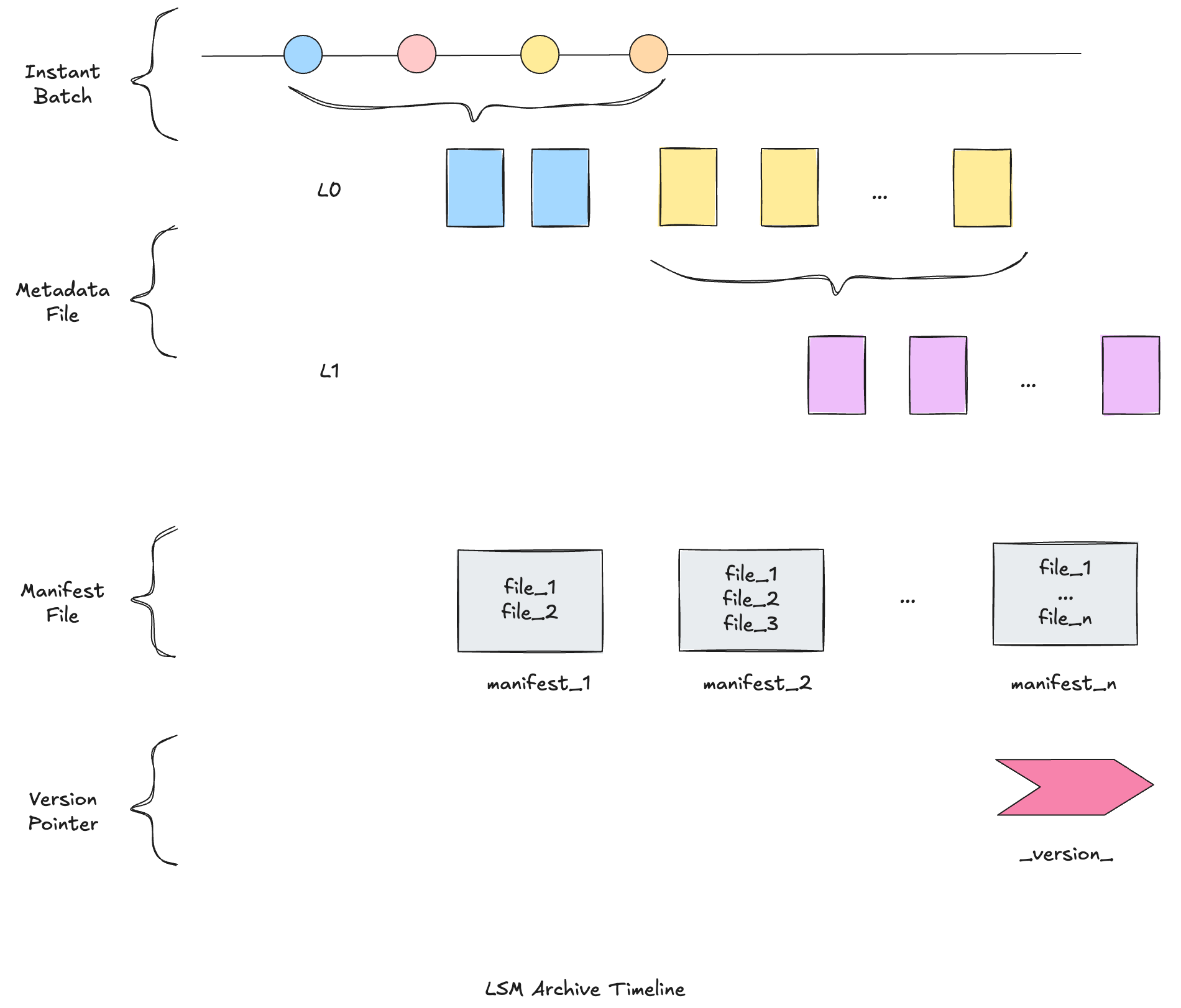
With the powerful new file layout, it is quite straight-forward to implement non-blocking concurrency control. The function is implemented with the simple bucket index on MOR table for Flink. The bucket index ensures fixed record key to file group mappings for multiple workloads. The log writer writes the records into avro logs and the compaction table service would take care of the conflict resolution. Because each log file name contains the instant time and each record contains the event time ordering field, Hudi reader can merge the records either with natural order(processing time sequence) or event time order.
The concurrency mode should be configured as NON_BLOCKING_CONCURRENCY_CONTROL, you can enable the table services on one job and disable it for the others.
Flink SQL demo
Here is a demo to show 2 pipelines that ingest into the same downstream table, the two sink table views share the same table path.
-- NB-CC demo
-- The source table
CREATE TABLE sourceT (
uuid varchar(20),
name varchar(10),
age int,
ts timestamp(3),
`partition` as 'par1'
) WITH (
'connector' = 'datagen',
'rows-per-second' = '200'
);
-- table view for writer1
create table t1(
uuid varchar(20),
name varchar(10),
age int,
ts timestamp(3),
`partition` varchar(20)
)
with (
'connector' = 'hudi',
'path' = '/Users/chenyuzhao/workspace/hudi-demo/t1',
'table.type' = 'MERGE_ON_READ',
'index.type' = 'BUCKET',
'hoodie.write.concurrency.mode' = 'NON_BLOCKING_CONCURRENCY_CONTROL',
'write.tasks' = '2'
);
insert into t1/*+options('metadata.enabled'='true')*/ select * from sourceT;
-- table view for writer2
-- compaction and cleaning are disabled because writer1 has taken care of it.
create table t1_2(
uuid varchar(20),
name varchar(10),
age int,
ts timestamp(3),
`partition` varchar(20)
)
with (
'connector' = 'hudi',
'path' = '/Users/chenyuzhao/workspace/hudi-demo/t1',
'table.type' = 'MERGE_ON_READ',
'index.type' = 'BUCKET',
'hoodie.write.concurrency.mode' = 'NON_BLOCKING_CONCURRENCY_CONTROL',
'write.tasks' = '2',
'compaction.schedule.enabled' = 'false',
'compaction.async.enabled' = 'false',
'clean.async.enabled' = 'false'
);
-- executes the ingestion workloads
insert into t1 select * from sourceT;
insert into t1_2 select * from sourceT;
Future Roadmap
While non-blocking concurrency control is a very powerful feature for streaming users, it is a general solution for multiple writer conflict resolution, here are some plans that improve the Hudi core features:
- NBCC support for metadata table
- NBCC for clustering
- NBCC for other index type
[^1] RFC-66 well-explained the completion time based file slicing with a pseudocode.
FAQ
What is non-blocking concurrency control (NBCC) in Apache Hudi?
NBCC is a general-purpose concurrency model, introduced in Hudi 1.0.0, aimed at stream processing and high-contention or frequent-writing scenarios. It allows multiple streaming writers to write to the same Hudi table without any conflict-resolution overhead, while keeping event-time ordering semantics and supporting asynchronous table services like compaction, archiving, and cleaning.
How is NBCC different from optimistic concurrency control (OCC)?
Under OCC, writers abort the transaction if there is a hint of contention. Under NBCC, concurrent writers all proceed: the log writers append records without coordinating, and the compaction table service takes care of conflict resolution. Readers can merge records in either natural (processing time) order or event-time order.
What storage changes in Hudi 1.0 made NBCC possible?
Hudi 1.0 introduced a new file layout based on both requested and completion times of actions, treating them as an interval. Log file names now carry the write's own requested instant time instead of the base instant time, so writers no longer query the file layout before flushing, and compaction can be scheduled at any time without blocking writers. An LSM-tree-based archived timeline supports the fast instant-to-completion-time lookups this requires.
How do I enable NBCC?
Set hoodie.write.concurrency.mode to NON_BLOCKING_CONCURRENCY_CONTROL. The initial implementation works with the simple bucket index on a merge-on-read table for Flink. When running multiple jobs against the same table, enable table services such as compaction and cleaning on one job and disable them on the others.
What are the current limitations and future plans for NBCC?
NBCC currently relies on the bucket index on MOR tables. The roadmap includes NBCC support for the metadata table, for clustering, and for other index types.