From Concept to Reality: Apache Hudi at the Foundation of Penn Entertainment's Data Platform
This blog post summarizes Penn Entertainment's presentation led by Senior Data Engineer Sydney Horan at the Apache Hudi Community Sync. Watch the recording on YouTube.
Note: The video presentation references DeltaStreamer, which was the legacy name for the tool. It has since been renamed to Hudi Streamer.

Penn Interactive successfully modernized its data platform to meet the high-volume, real-time demands of the online sports betting industry by adopting Apache Hudi at its core.The architecture uses Hudi Streamer to natively consume CDC messages from thousands of Kafka topics, performing efficient upserts into the S3 Parquet lakehouse. Argo Workflows and custom automation manage over a hundred concurrent jobs, ensuring high reliability via auto-resubmission logic and optimized resource utilization. The team achieved operational resilience by implementing a Disaster Recovery workflow to quickly patch data gaps using a JDBC source when Kafka logs were unavailable. A custom web-based system now monitors and visualizes the real-time data freshness of all tables, ensuring timely delivery of business intelligence and reports.
Penn Interactive and The Score merged in 2022 under Penn Entertainment, combining sports betting and sports media for customers across the U.S. and Canada. Known for apps like Barstool Sportsbook and The Score Bet, the company operates at the forefront of the online and retail sports betting industry.
After the merger, the data engineering team faced the challenge of building a new data analytics platform from scratch. At the core of this platform was Apache Hudi, chosen for its flexibility, scalability, and integration capabilities with a modern data ecosystem.
Challenges in Building a Data Platform
The company’s data ecosystem includes a wide range of operational databases, third-party services, and outputs from data science models. The data platform needed to support diverse use cases, including:
- Daily reporting for casino partners and marketing vendors.
- Business intelligence dashboards for finance, marketing, and promotions teams.
- Data science workflows for predictive analytics.
Traditional solutions, which relied on batch or streaming replication of database tables, proved inefficient. They often required batch overrides and failed to fully leverage change data capture (CDC), creating operational bottlenecks and delays in delivering timely insights. The new system required near real-time replication that integrated smoothly with end-user reporting tools, as well as a mechanism to proactively identify pipeline anomalies and ensure data freshness across thousands of tables.
The Source and Target Ecosystems
The platform ingests data from dozens of PostgreSQL operational databases across multiple service teams. The tables vary in structure, data types, and throughput - some tables generate a million CDC messages per hour, while others update only a few rows per year. The ingestion pipeline needed to scale effectively with this variable throughput.In addition to internal databases, the platform also integrates data from third-party file transfers, APIs, and outputs from other data teams. The target environment is structured in layers:
- Raw Layer: A mirror of the source data, stored in S3 using the Parquet file format and written efficiently by Hudi Streamer.
- Query Layer: Redshift external tables provide a structured access point over the S3 data for easy querying.
- Curated Layers: The data team further refines this raw data into models and analysis views for BI and data science.
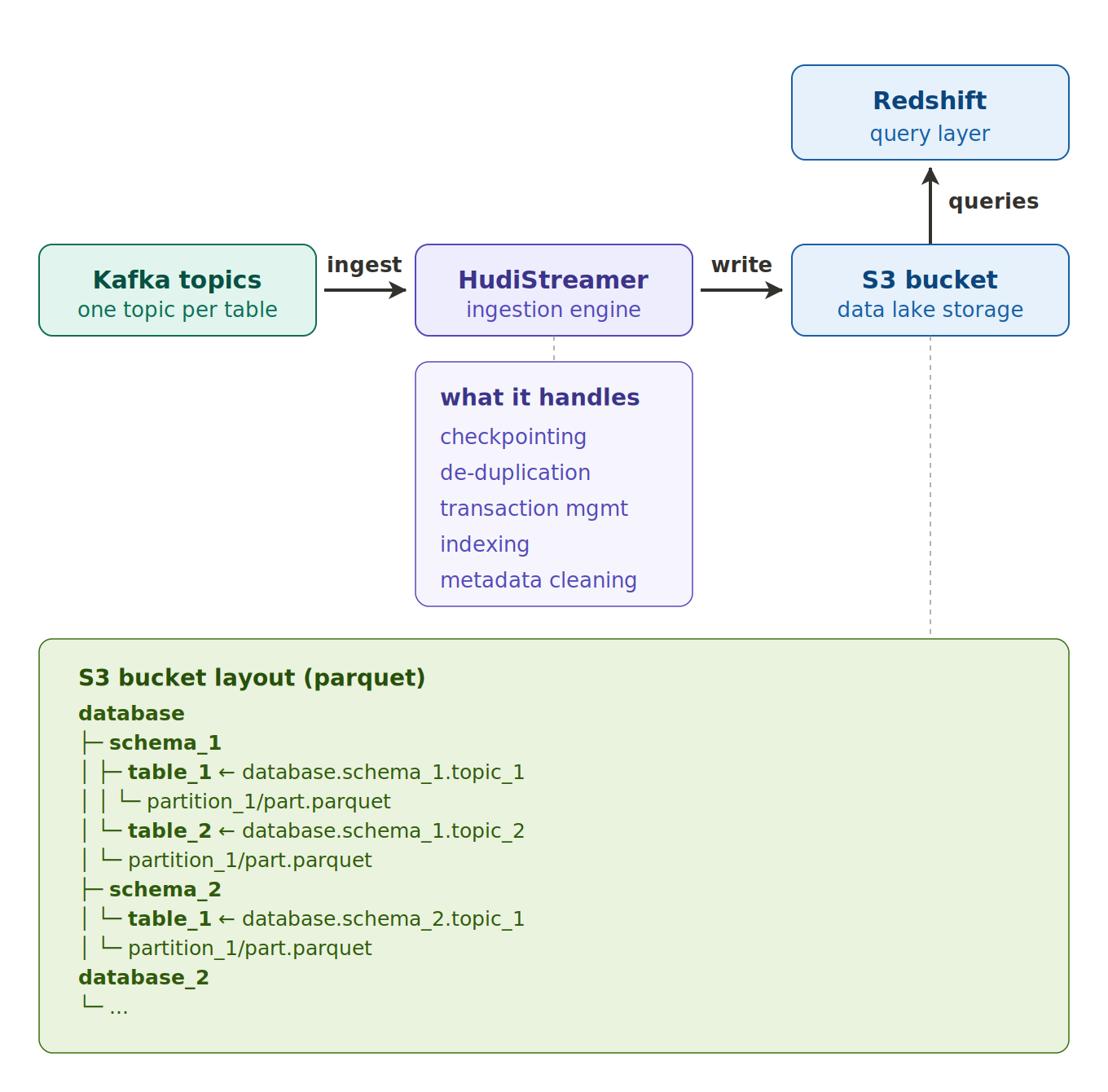
Kafka topics (one per table) are ingested by Hudi Streamer, which handles checkpointing, de-duplication, transactions, indexing, and metadata cleaning, into Parquet on S3 and is queried through Redshift external tables.
The Solution: Apache Hudi and Hudi Streamer
Apache Hudi was selected as the ideal foundation for the data lakehouse architecture for several reasons:
- Handling Updates and Incremental Processing: Hudi efficiently manages data updates, performing upserts instead of just appending, which is critical for CDC data. It allows for incremental processing of large data volumes.
- Diverse Data Ingestion: Hudi gracefully handles both streaming CDC messages and external batch sources.
- Ecosystem Compatibility: Hudi integrates smoothly with the Apache ecosystem and tools like Spark, simplifying operations.
Hudi Streamer became the core database replication tool. It natively processes CDC messages streamed through Kafka topics, applying the exact changes to the Hudi tables to maintain synchronization. The team leveraged its capabilities for:
- Operational Flexibility: Choosing between continuous mode (for high-throughput, near real-time tables) and run-once mode (for smaller, periodic jobs).
- Scalability: Managing over a hundred concurrent Hudi Streamer jobs, consuming from nearly a thousand topics, by optimizing resource use through table grouping.
The Journey of Implementation and Scale
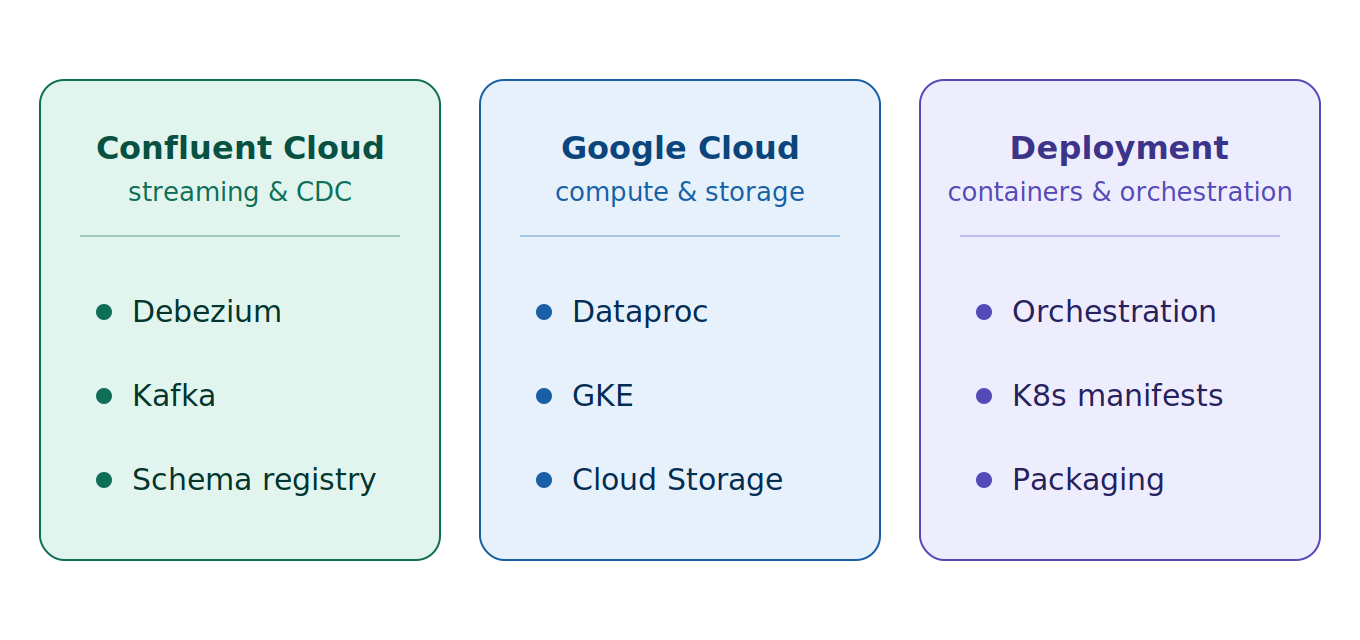
The technology stack: Confluent Cloud (Debezium, Kafka, Schema Registry) for change capture, Google Cloud (Dataproc, GKE, Storage) for compute and storage, and Python/Kubernetes/Docker for orchestration and packaging.
The implementation process involved several key phases, moving from initial concept to large-scale automation:
1. Proof of Concept
Early experiments with homegrown solutions and traditional streaming methods highlighted major pain points such as manual checkpointing, batch sizing, and scalability concerns. The combination of Debezium, Kafka, and Hudi Streamer was ultimately chosen, as Hudi Streamer provided built-in solutions for these complex operational challenges.
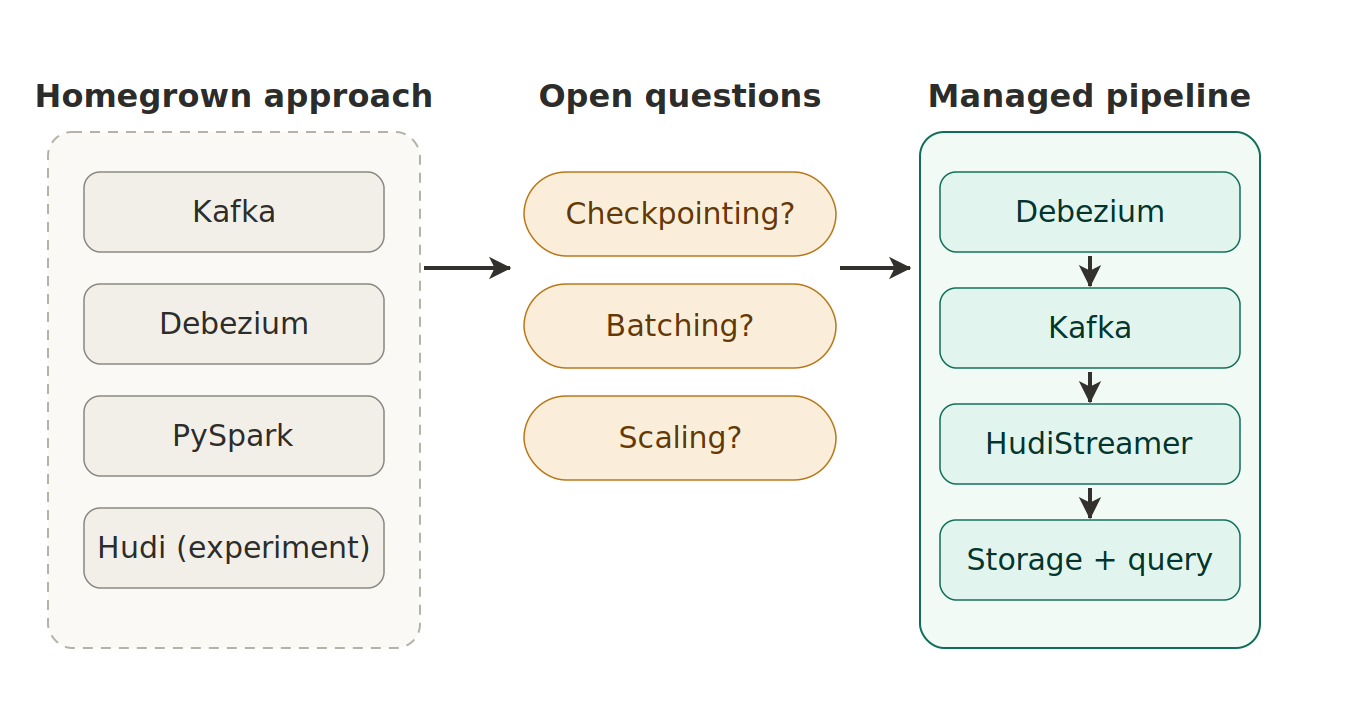
A homegrown solution vs. Kafka, Debezium, and PySpark/Hudi experimentation and weighing checkpointing, batching, and scaling before committing to a Hudi-based pipeline.
The data platform's CDC pipeline relies on Debezium connectors to capture changes from PostgreSQL databases, streaming them into Kafka topics hosted on Confluent Cloud. Hudi Streamer consumes these messages, applies the updates to Hudi tables in S3, and integrates them into the Redshift query layer. The system also handles non-CDC data sources, such as:
- Third-party vendor files via SFTP or cloud storage.
- Data from vendor APIs.
- Retail data from on-premise Casino systems.
These workflows ingest and upsert data into Hudi tables, ensuring consistency and availability for downstream analytics.
2. Infrastructure and Knowledge
The platform runs on Google Cloud Platform, using Dataproc for Spark execution and Google Kubernetes Engine for container orchestration. They integrated Confluent Cloud for Kafka and the schema registry, ensuring the environment was ready to ingest data from the source Postgres databases into the S3 target.
3. Community Collaboration and Custom Enhancements
During development, the engineering team actively collaborated with Hudi developers. Through Slack channels, GitHub issues, and weekly calls, the team resolved technical challenges and incorporated improvements. They created a custom fork to address specific needs, such as:
- Timestamp Format: Incorporating epoch microseconds for Debezium timestamps.
- Job Reliability: Resolving an occasional bug where multi-table jobs would hang by implementing a forceful shutdown mechanism for background processes.
- Tombstone Messages: Implementing a filter to handle and remove null values caused by Kafka Tombstone messages, which previously triggered null pointer exceptions.
4. Automation and Orchestration
To ingest data from thousands of tables without manual shell scripts, the team built a custom Python wrapper script running as a Kubernetes pod.
- Configuration Control: Job parameters are centralized in a config file that the wrapper script reads to dynamically build Spark arguments. This allows the team to easily define tables, key columns, and required Spark resources (categorized as small, medium, large) without modifying code.
- Orchestration: Argo Workflows act as the central orchestrator, running the wrapper script on a scheduled basis.
5. Scaling and Reliability
The Argo workflow includes a crucial pulse check and resubmission mechanism. It constantly monitors continuous mode jobs and quickly resubmits any that fail due to network timeouts or platform glitches, ensuring high reliability for 24/7 ingestion.
The team established a workflow for Disaster Recovery for scenarios where Kafka logs have expired. They developed a process to temporarily pause the streaming job and kick off a dedicated Hudi Streamer job with a JDBC source. This job directly upserts missing data from the source, quickly patching the data gap before the streaming job is resumed.

A data-corruption bug in the streaming job (around Apr '23) is repaired by a Hudi Streamer batch job that uses JdbcSource to overwrite the corrupted dates with source data.
6. Monitoring Data Freshness
A final piece of the puzzle was ensuring data freshness. Given the extreme variance in Kafka offsets, a custom, more insightful monitoring solution was required. Custom scripts and Datadog dashboards were used initially, but as the system scaled, a web-based monitoring interface was developed. This API continuously crawls each Hudi table, retrieving its maximum timestamp and comparing it against established freshness thresholds.
This solution provides a user-friendly web interface that gives the entire team a single, clear view of all tables, easily highlighting any that are lagging. This capability is being integrated into a comprehensive alerting system to minimize the need for manual intervention during data latency incidents.
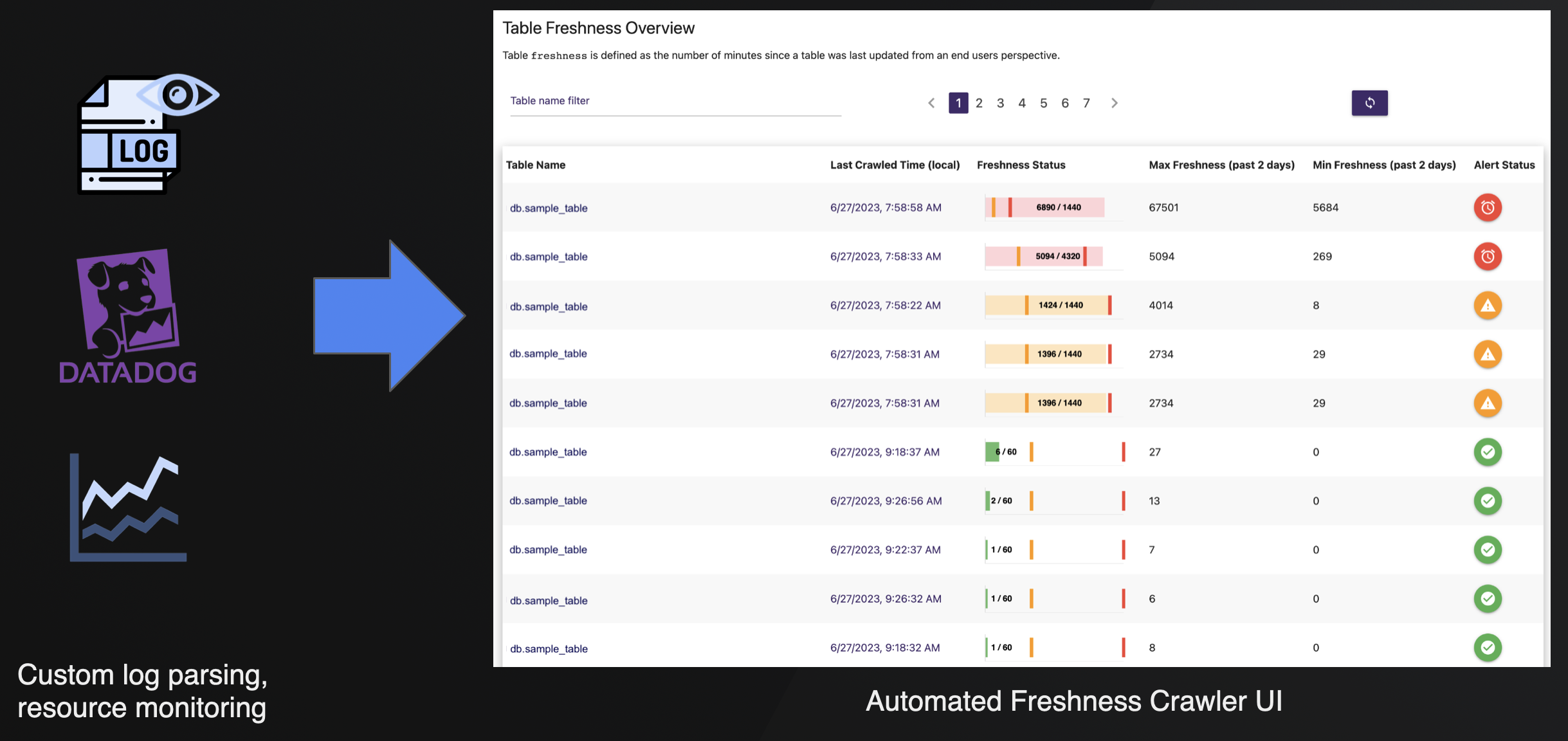
The automated freshness crawler UI fed by custom log parsing and Datadog monitoring
Conclusion
The implementation of Apache Hudi has been transformative for Penn Interactive and The Score's data platform. By choosing Apache Hudi, the organization successfully consolidated data from diverse sources with high flexibility and scalability. The custom automation, robust monitoring, and disaster recovery processes built around Hudi Streamer ensure the platform provides accurate and timely insights to stakeholders across business intelligence, marketing, and data science.
With Apache Hudi at its core, the data platform is well-positioned to scale alongside the growing demands of the online sports betting and media industry.
This blog is based on Penn Entertainment's presentation at the Apache Hudi Community Sync. If you are interested in watching the recorded version of the video, you can find it here.