Modernizing Data Infrastructure at Southwest with Apache Hudi
This blog post summarizes Southwest Airlines's presentation led by Tech Lead Data Engineer Koti Darla at the Apache Hudi Community Sync. Watch the recording on YouTube.

Southwest Airlines migrated from an on-premise data warehouse powered by Ab Initio ETL to a modern AWS-based lakehouse architecture using Apache Hudi on Amazon EMR. The team tackled the complex challenge of implementing Slowly Changing Dimensions Type 2 (SCD Type 2) on reservation data flattening deeply nested XML payloads (20–25 levels) into 30+ tables while preserving full historical tracking. Through careful optimization of Spark configurations, partitioning strategies, Hudi indexing, and EMR resource management, they achieved 40–60% faster execution times, reducing job runtime from ~5 hours to ~1.5 hours. This blog details their architecture, implementation patterns, the challenges they faced, and the optimizations that made it work.
As data volumes scale, legacy on-premise data infrastructure often struggles to keep up with the performance, cost efficiency, and flexibility required by modern applications. At Southwest Airlines, the data platform team underwent a major journey to modernize their infrastructure. By migrating from legacy on-premise systems to a high-performance lakehouse architecture powered by Apache Hudi, they tackled massive processing bottlenecks, reduced cloud costs, and successfully implemented complex data patterns like Slowly Changing Dimensions (SCD) Type 2 at scale. Here is an inside look at their architectural transition, key performance challenges, and how they resolved them.
The Legacy Architecture
Southwest's previous data stack was built around a traditional ETL pattern:
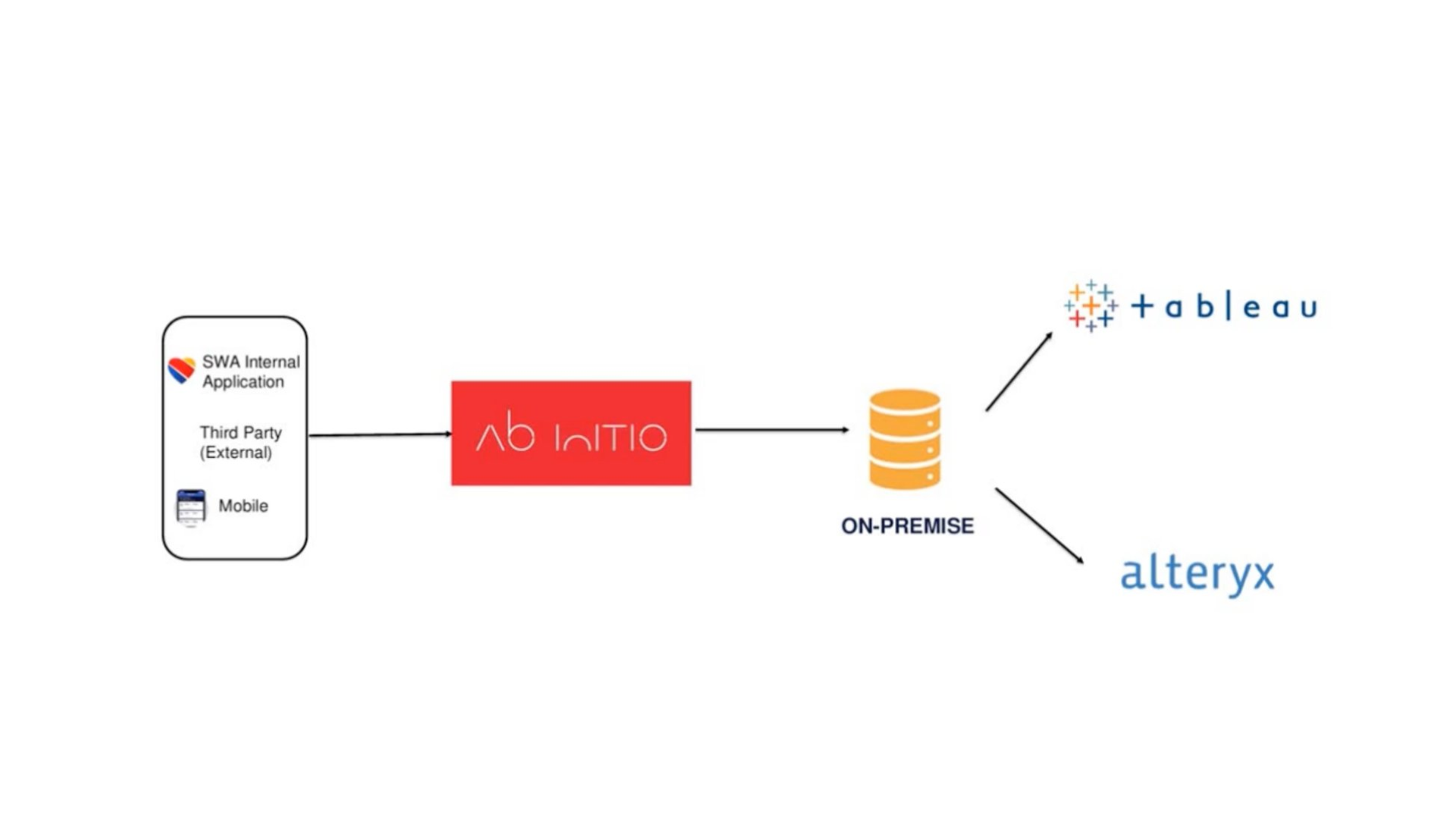
Southwest's old ETL stack — sources processed through Ab Initio into an on-premise database feeding Tableau and Alteryx.
- Source applications: SWA internal applications, third-party applications, and mobile applications fed data into the pipeline.
- ETL layer: Ab-Initio handled transformation, standardization, validation, cleansing, business logic, change data capture, and window functions.
- Storage: Transformed data landed in an on-premise data warehouse.
- Consumption: Tools like Alteryx connected directly to the warehouse to extract business insights and reports.
While functional, this architecture had limits in scalability, cost flexibility, and the ability to support modern data science and streaming workloads.
The New Architecture: AWS + Apache Hudi
The modernized stack is fully cloud-native and built around a multi-zone lakehouse pattern:
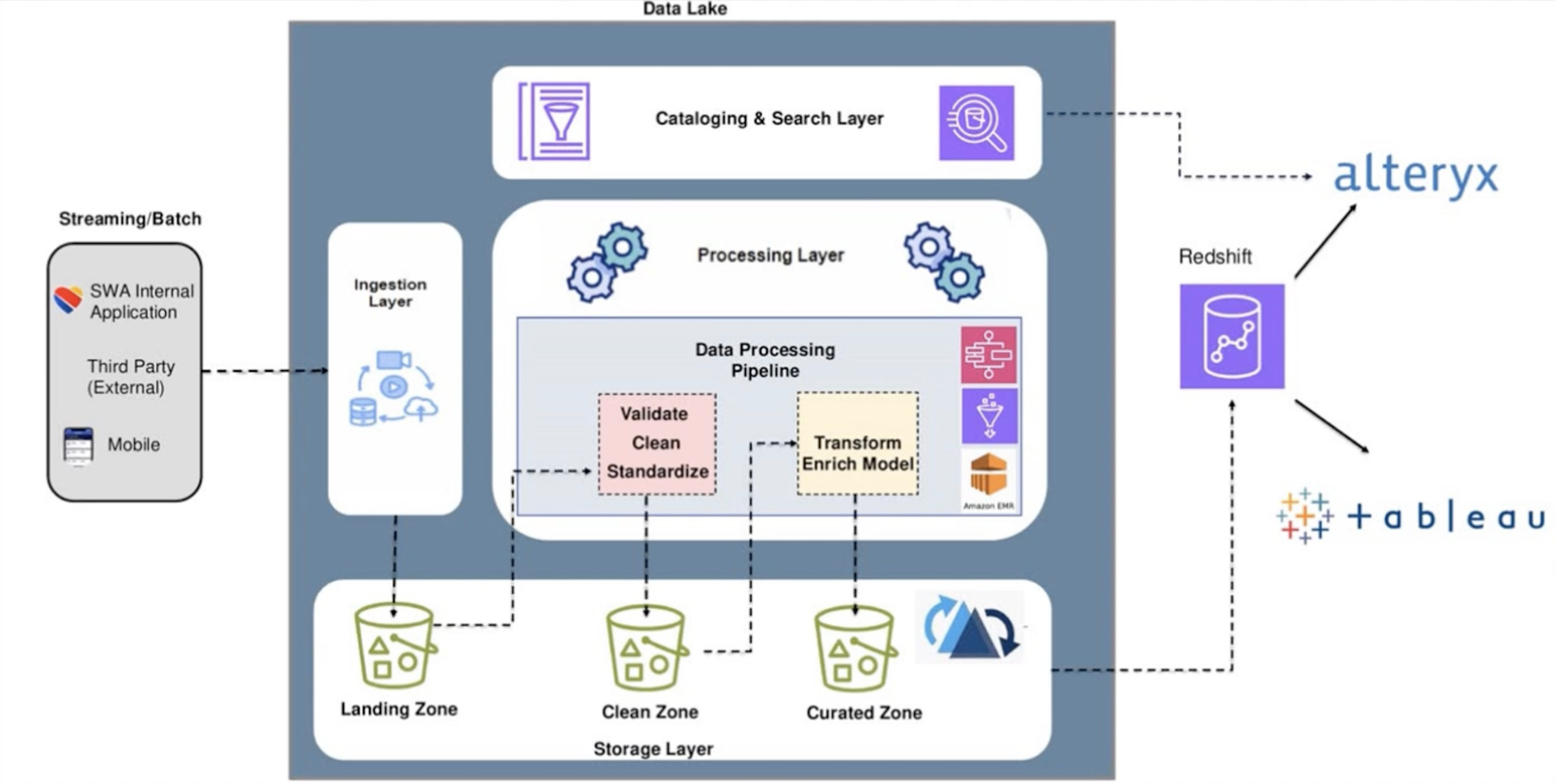
The modernized cloud-native lakehouse. Streaming/batch sources land in Hudi-backed Landing, Clean, and Curated zones, processed on EMR and served to Redshift, Alteryx, and Tableau.
- Ingestion Layer: Data from source applications is captured via SFTP (for files) or Kafka S3 Sync Connectors and placed into an Amazon S3 Landing Zone.
- Processing & Cleaning: Amazon EMR with PySpark and AWS Glue run the data pipelines. Pipelines validate, clean, and standardize data, then write to the Clean Zone on S3.
- Curated Layer & Apache Hudi: Another set of PySpark pipelines transforms and enriches the data, writing to the Curated Zone where Hudi tables live.
- Orchestration & Cataloging: AWS Step Functions orchestrate the workflows. AWS Glue handles the data catalog, and Amazon Athena is used for ad-hoc querying.
- Serving Layer: Data is also loaded into Amazon Redshift for BI consumption via Alteryx and Tableau. Data science teams build and run models directly on the Hudi tables.
The Use Case: Reservation Events and SCD Type 2
When a customer books a flight, Southwest receives a reservation event as an XML payload with 20–25 nested levels. The data modeling team normalized this into a third-normal-form model with 30+ tables, most of which require SCD Type 2 historical tracking. Only a handful are insert-only.
Starting Point: An AWS Blog
The team discovered an AWS blog titled "Build Slowly Changing Dimensions Type 2 (SCD2) with Apache Spark and Apache Hudi on Amazon EMR" which became their foundation.
Key takeaways they adopted:
- Use Hudi upsert capabilities for seamless insert/update handling.
- Use EMR for autoscaling, cost efficiency, and high availability.
- Leverage pre-combine logic for change detection and de-duplication.
- Maintain old records with effective start/end dates; use the latest effective end date to identify current records.
Why Copy-on-Write (CoW)?
After evaluating both Hudi table types, the team chose Copy-on-Write as the better fit for their needs. Their workload is primarily batch processing, and SCD Type 2 requires reading previous records to end-date them. CoW provides faster, consistent queries for current data without the extra log-file overhead that Merge-on-Read introduces. CoW also ensures atomic updates by overwriting base files, which simplifies version tracking and aligns naturally with SCD Type 2's need to maintain full record versions and handle reprocessing of out-of-order data.
Orchestration: Step Functions + DynamoDB
With 30+ tables loaded every two hours and strict referential integrity requirements, the team needed robust orchestration with restart-from-failure capability. At the time, Step Functions didn't yet offer "redrive from failure," so they built a custom tracking layer using DynamoDB.
The team built a custom tracking layer in DynamoDB. Two tables:
- The job-stream tracking table records each batch file and its status per target table. So if batch 02 is in flight and tables A, B, and C completed but D and E failed, only D and E get reprocessed on retry. The completed ones get skipped.
- The Hudi-to-Redshift tracking table stores the last Hudi commit timestamp loaded into Redshift. Subsequent loads only pick up the delta. No full reloads, no double-counting.
This design gave them restart safety, referential integrity, and a clean foundation for monitoring dashboards.
Handling Out-of-Order Data
Reservation versions don't always arrive in the right sequence and that created a real challenge. Imagine a PNR with three versions such as v1 ($100), v2 ($200), v3 ($300). If v1 and v3 arrive first, then v2 arrives later, naive sequential processing would produce incorrect historical tracking.
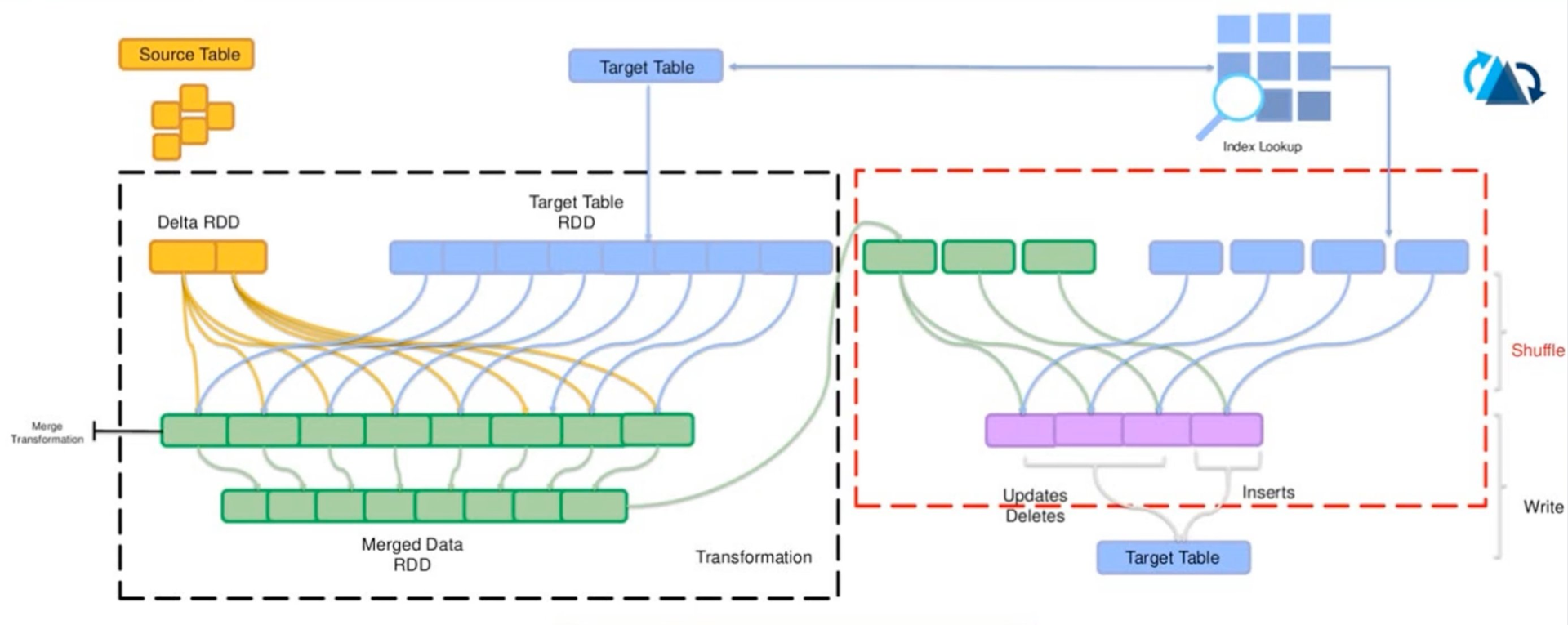
When PNR versions arrive out of order, Hudi merges the delta against existing records via an index lookup before writing — keeping history correct.
To solve this, the team built a custom merge flow that begins by collecting all keys in the incoming delta batch and then going back to the target Hudi table to pull all related historical records for those keys. New versions are run through the full transformation logic, while already-transformed records are reused as-is to avoid redundant computation. With the complete picture in hand, the pipeline recalculates all effective start and end dates across the merged set, then uses Bloom Index with Hudi upsert to insert and update records accordingly. If the recalculation reveals orphan records — i.e., rows that should no longer exist because a later-arriving version invalidated them — the pipeline issues explicit deletes to keep the history clean. Notably, this logic is fully custom; the team did not use Hudi's built-in record mergers (event-time or commit-time ordering) because their workflow required expiring previous records and applying complex business gap-filling logic across multiple related tables.
Key Performance Challenges & Solutions
The team encountered four major categories of performance challenges.
1. XML Flattening Bottlenecks
Exploding deeply nested XML generated billions of rows, causing massive shuffle overhead (observed: ~11 billion records, 2.2 TB shuffle reads, 5.1 TB writes), severe data skew, executor failures from memory pressure, and lost executors from heavy shuffle I/O.
Optimizations applied: They balanced partitions using explicit repartition() and coalesce() steps, tuned maxPartitionBytes to break data into smaller, manageable shuffle blocks, and implemented salting techniques on heavily skewed keys. They also utilized Adaptive Query Execution (AQE) to dynamically auto-adjust shuffle partitions.
Result: 40–60% faster execution, reduced shuffle overhead, and improved memory efficiency.
2. Complex Transformations and Massive DAGs
Long lineage chains from window functions, multi-table joins, and business logic created huge DAGs. Executors ran out of memory, cached stages got lost, and re-execution further slowed things down.
Optimizations applied: They systematically broke the Spark DAGs by implementing intermediate local file reads and writes (checkpointing to disk). This completely cleared memory caching pressures. Additionally, they dropped unused columns early in the pipeline and used broadcast joins for smaller reference tables. Used repartition before explodes, joins, and aggregations. Continuous fine-tuning by reading Spark UI and Ganglia charts.
Result: Smaller, more manageable DAGs and the same 40–60% efficiency gains.
3. Historical Backfill and Partitioning
The team initially attempted to backfill 10 years of historical booking data directly into Hudi using Day-level partitioning. However, creating millions of fine-grained S3 prefixes and processing indexing lookups over a decade of data stalled the cluster.
Optimizations applied: Worked with business stakeholders to redefine the historical requirement to a rolling 3-year window, which captures nearly all practical booking lifecycle updates. Tuned the Hudi recordKey by prefixing it with a datetime string to significantly accelerate Bloom Index lookups.
Result: Significantly shorter job execution, reduced cluster cost, and faster incremental processing.
4. Spiking EMR Cluster Costs
Fluctuating workloads combined with standard EC2 instance pricing and inefficient auto-scaling behaviors initially led to high operational costs on Amazon EMR.
Optimizations applied: Switched cluster node architecture to ARM-based AWS Graviton instances, providing a direct 20% cost reduction. Disabled standard Auto Scaling in favor of EMR Managed Scaling to prevent premature instance termination and re-initialization loops. Added memory overhead settings at cluster creation to resolve resource contention when multiple Spark jobs ran on the same cluster. Partitioning by PNR date so that grouping all bookings for a given date together makes out-of-order processing and version updates dramatically more efficient.
Result: Lower EMR cost, optimized resource utilization, improved job performance, and met SLAs.
What's Next
The team is actively exploring several Hudi capabilities to push further:
- While Copy-on-Write perfectly fits batch processing needs today, they are testing MOR tables to see if they can achieve lower write latency and even faster upsert times during high-frequency incremental updates.
- Revisiting Record Level Index for update efficiency.
- Add Secondary Indexes — speeds up queries that filter on non-key columns, accelerating selective queries that would otherwise scan every partition.
- Upgrading to Hudi 1.0+ to unlock latest improvements in indexing, compaction, and performance optimizations.
Conclusion
Southwest Airlines moved its reservation data pipeline from an on-premise, Ab-Initio based warehouse onto an AWS lakehouse built on Apache Hudi and Amazon EMR. Using Copy-on-Write tables, a custom orchestration layer built on AWS Step Functions and DynamoDB, and custom logic for SCD Type 2 and out-of-order events, the team flattened deeply nested reservation XML into more than 30 well-structured (third-normal-form) tables without losing any history. Getting there meant solving real problems: flattening the XML, taming large Spark jobs, backfilling and partitioning historical data, and keeping EMR costs in check. The modernization yielded significant improvements: Job runtime dropped from about five hours to roughly an hour and a half (a 40–60% improvement), EMR costs came down, and the team kept hitting its SLAs. The team is continuing to evaluate further Hudi capabilities, including Merge-on-Read, record-level and secondary indexing, and an upgrade to Hudi 1.0+.
For the full walkthrough — including the architecture, the SCD Type 2 and out-of-order handling, and the Spark and EMR optimizations — watch the recording on YouTube.