Mastering Data Lakes: A Deep Dive into MINIO, Hudi, and Delta StreamerNovember 30, 2023 by Soumil Shahminiohudi streamer
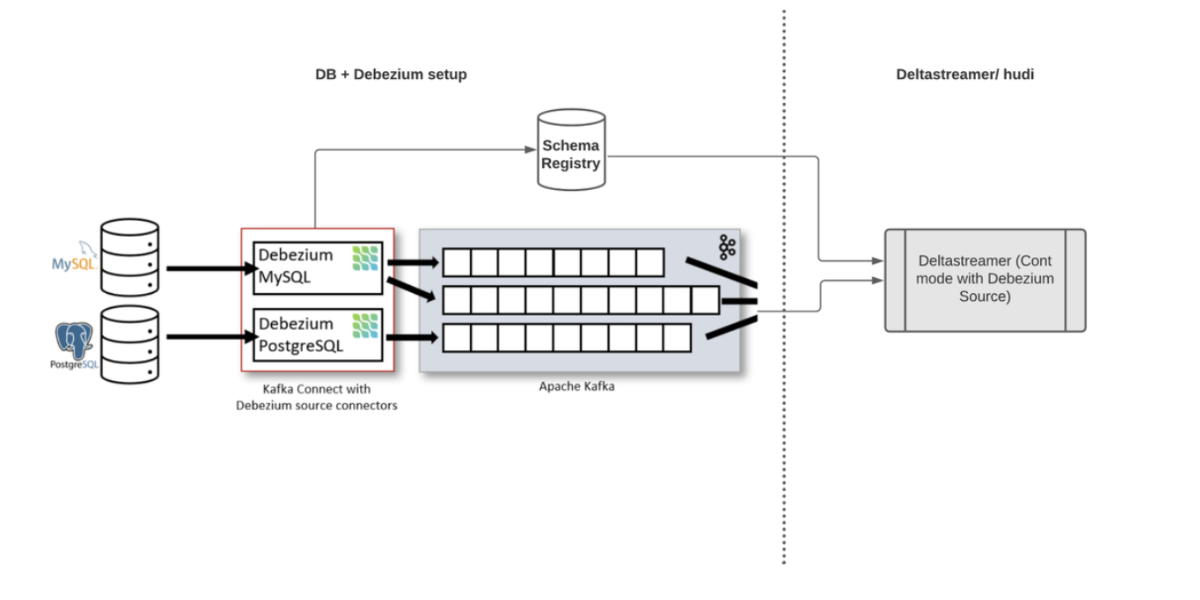
Real-Time Data Processing with Postgres, Debezium, Kafka, Schema Registry, and Delta Streamer Guide for BegineersNovember 26, 2023 by Soumil Shahpostgresdebeziumapache kafkahudi streamer
Introducing Apache Hudi support with AWS Glue crawlersNovember 22, 2023 by Noritaka Sekiyama, Kyle Duong, Sandeep Adwankaraws
Hudi Streamer (Delta Streamer) Hands-On Guide: Local Ingestion from Parquet SourceNovember 19, 2023 by Soumil Shahhudi streamerapache parquet
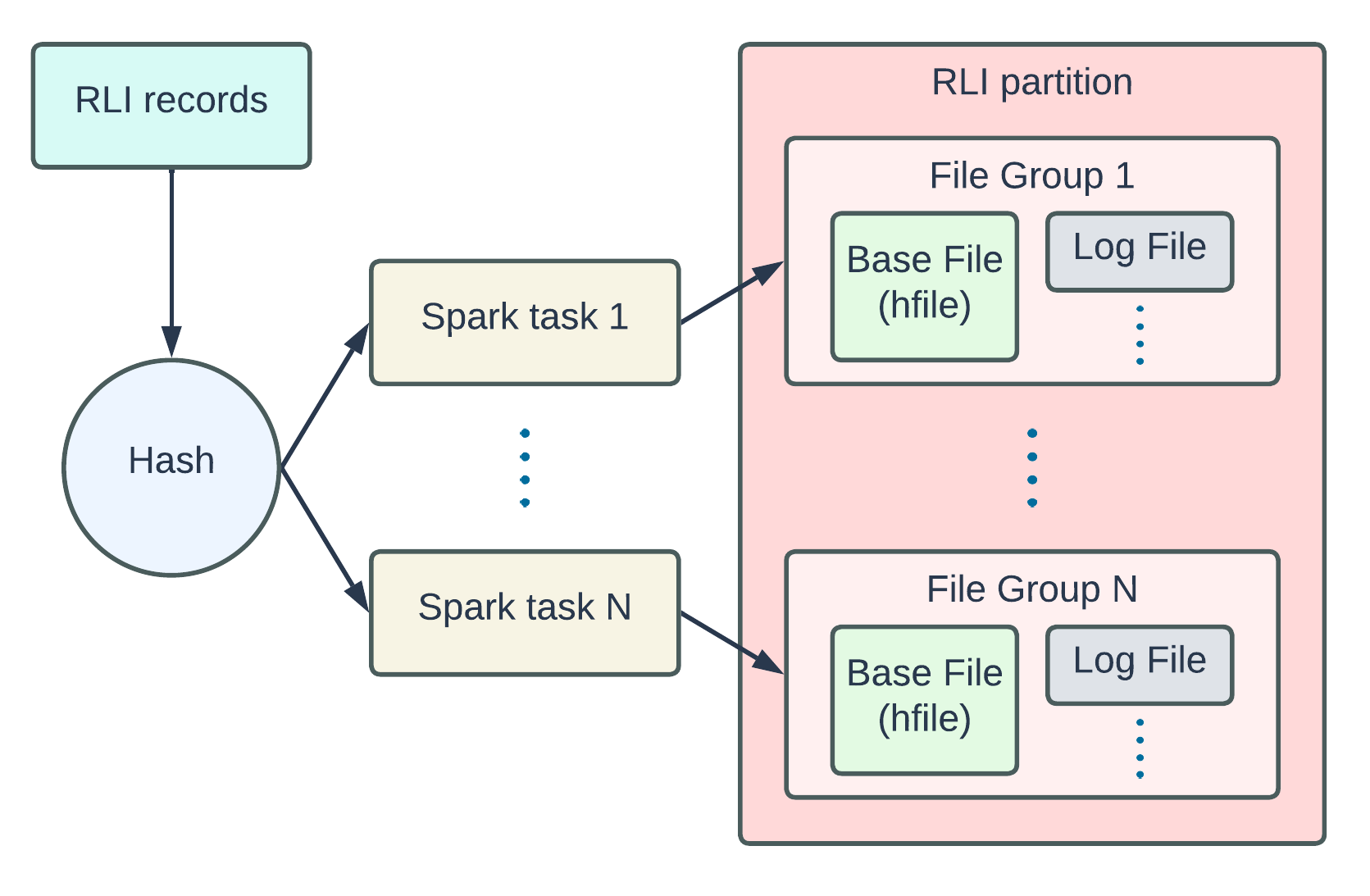
Record Level Index: Hudi's blazing fast indexing for large-scale datasetsNovember 1, 2023 by Shiyan Xu and Sivabalan Narayananindexingmetadata