Onehouse brings a fully-managed lakehouse to Apache HudiFebruary 3, 2022 by Paul Sawersdata lakehouse
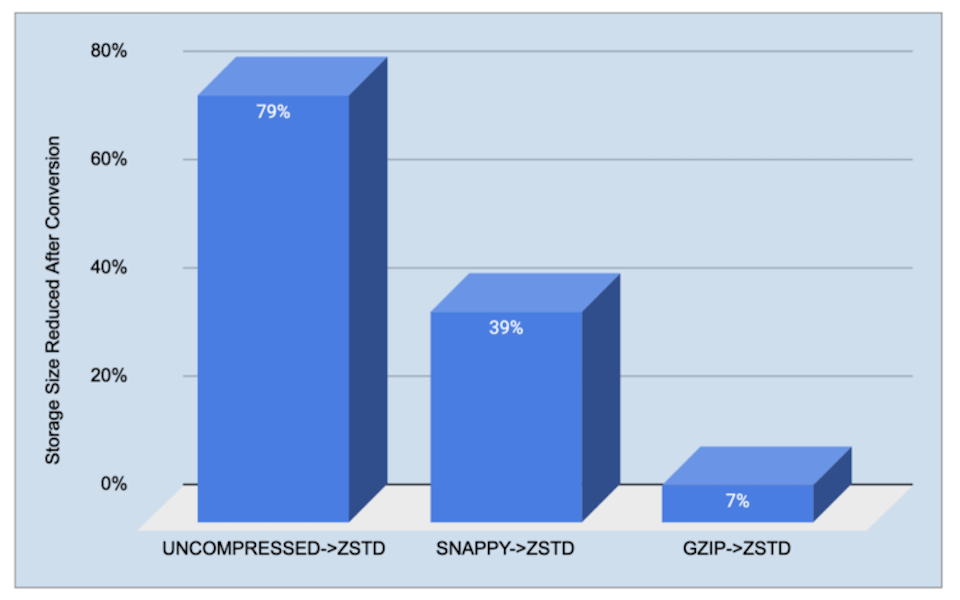
Cost Efficiency @ Scale in Big Data File FormatJanuary 25, 2022 by Xinli Shang, Kai Jiang, Zheng Shao and Mohammad Islamperformancecompressionbiuber
Hudi powering data lake efforts at Walmart and Disney+ HotstarJanuary 20, 2022 by Sean Michael Kernerwalmart
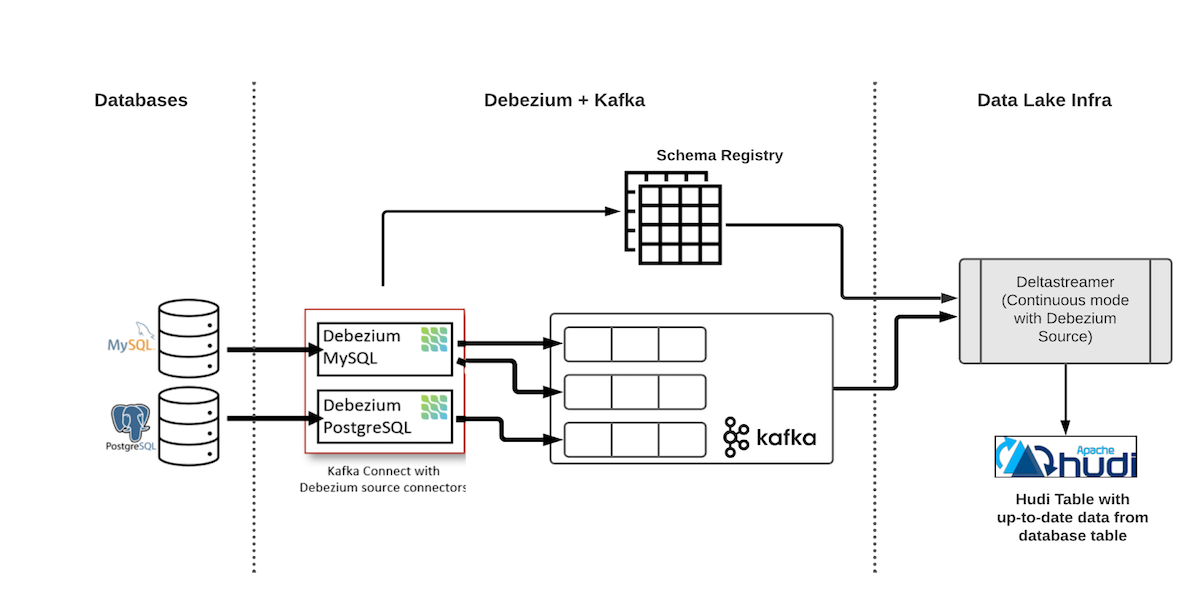
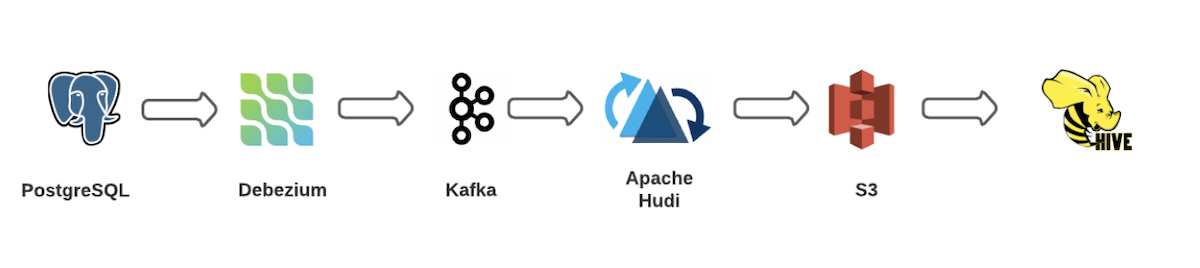
The Art of Building Open Data Lakes with Apache Hudi, Kafka, Hive, and DebeziumDecember 31, 2021 by Gary Stafforddata lakehouse
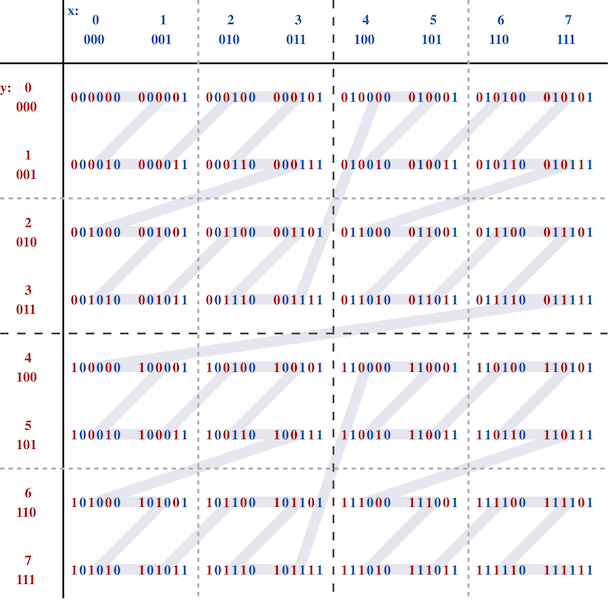
Hudi Z-Order and Hilbert Space Filling CurvesDecember 29, 2021 by Alexey Kudinkin and Tao Mengclusteringdata skipping
New features from Apache Hudi 0.7.0 and 0.8.0 available on Amazon EMRDecember 20, 2021 by Udit Mehrotra and Gagan Brahmiaws
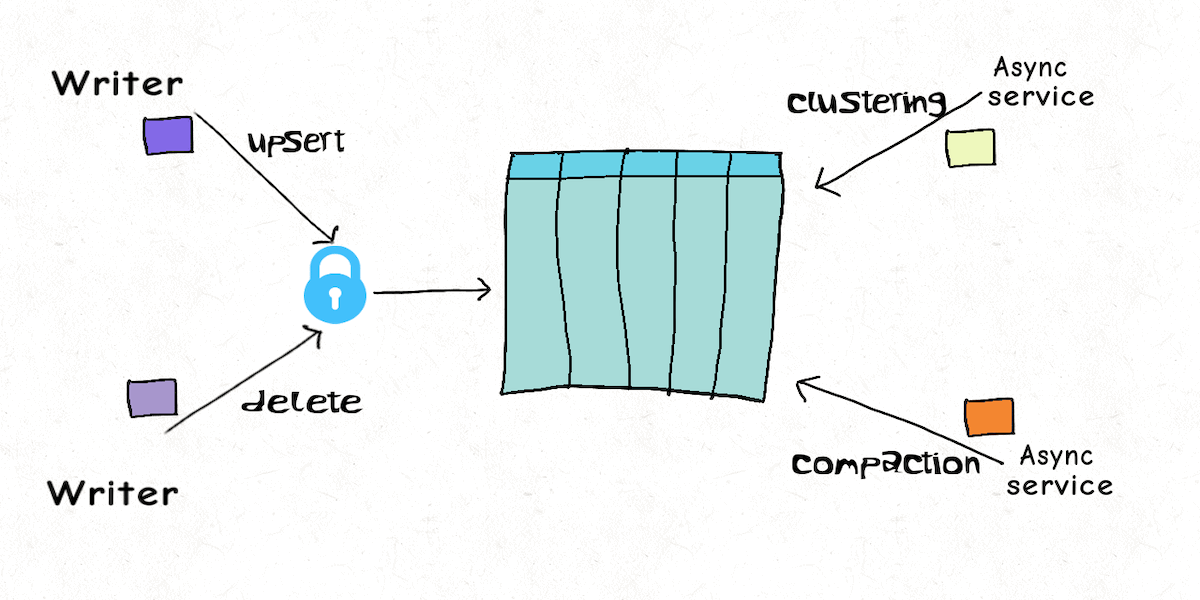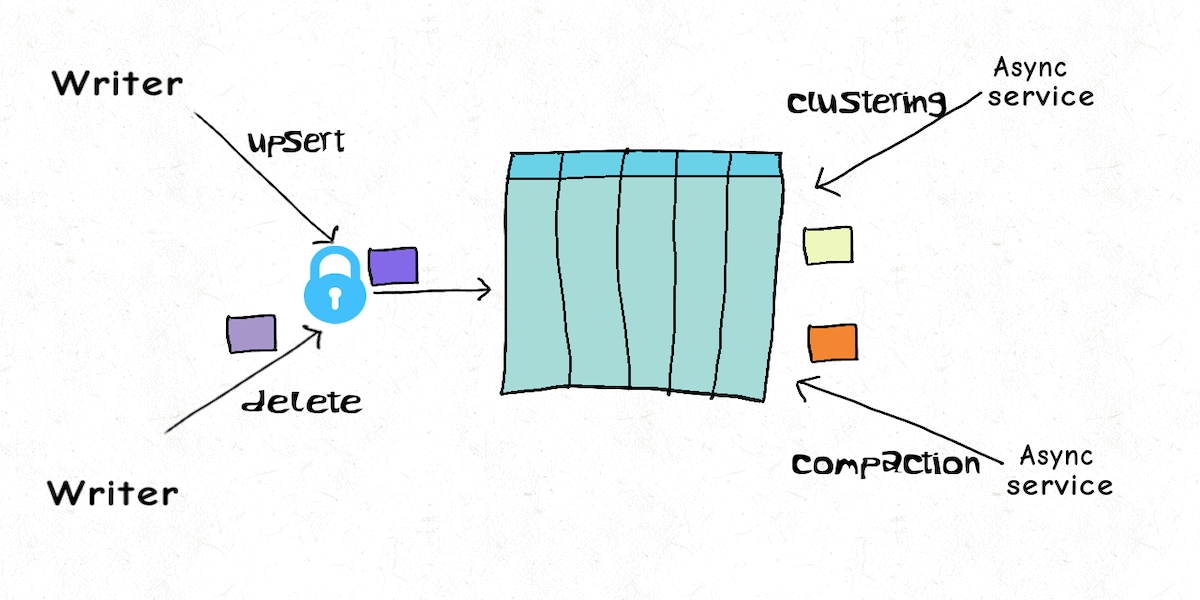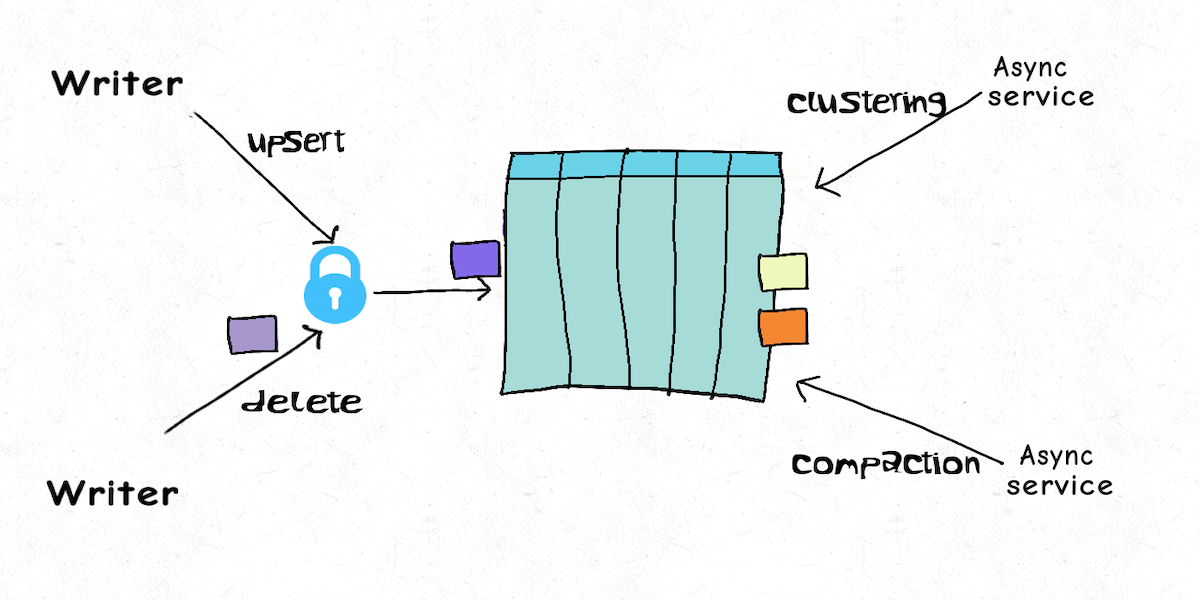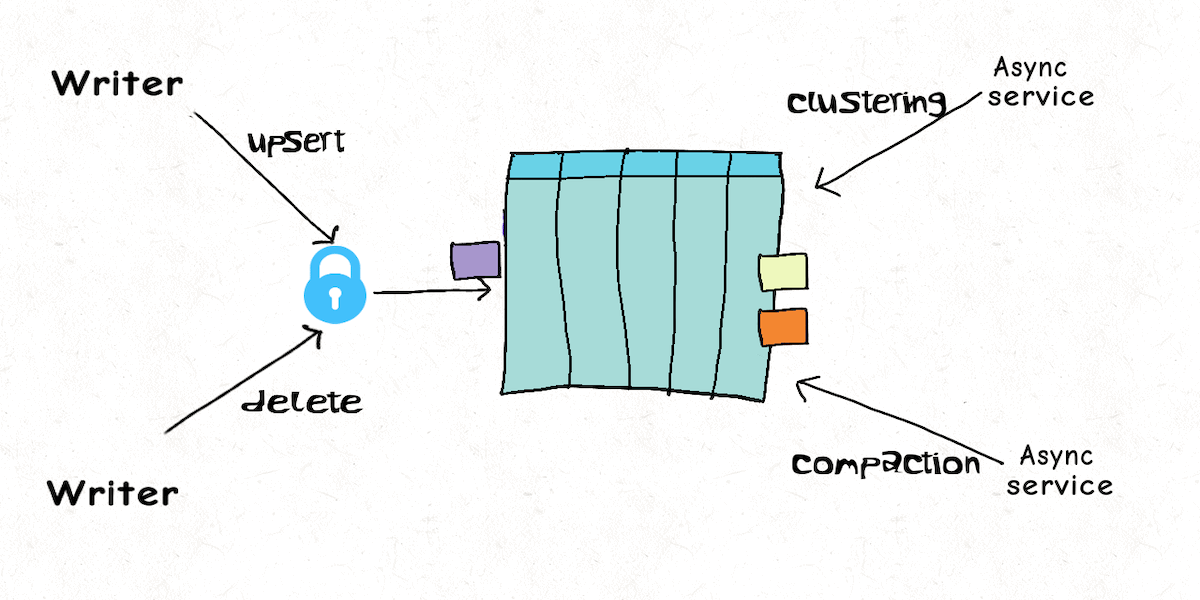
Lakehouse Concurrency Control: Are we too optimistic?December 16, 2021 by Vinoth Chandarconcurrency control