Developer Guide: How to Submit Hudi PySpark(Python) Jobs to EMR Serverless (7.1.0) with AWS Glue Hive MetaStoreSeptember 4, 2024 by Soumil Shahapache sparkpythonaws
Use AWS Data Exchange to seamlessly share Apache Hudi datasetsMay 22, 2024 by Saurabh Bhutyani, Ankith Ede, and Chandra Krishnandata sharingaws
Learn how to read Hudi data with AWS Glue Ray using Daft (No Spark)May 7, 2024 by Soumil Shahawsraydaft
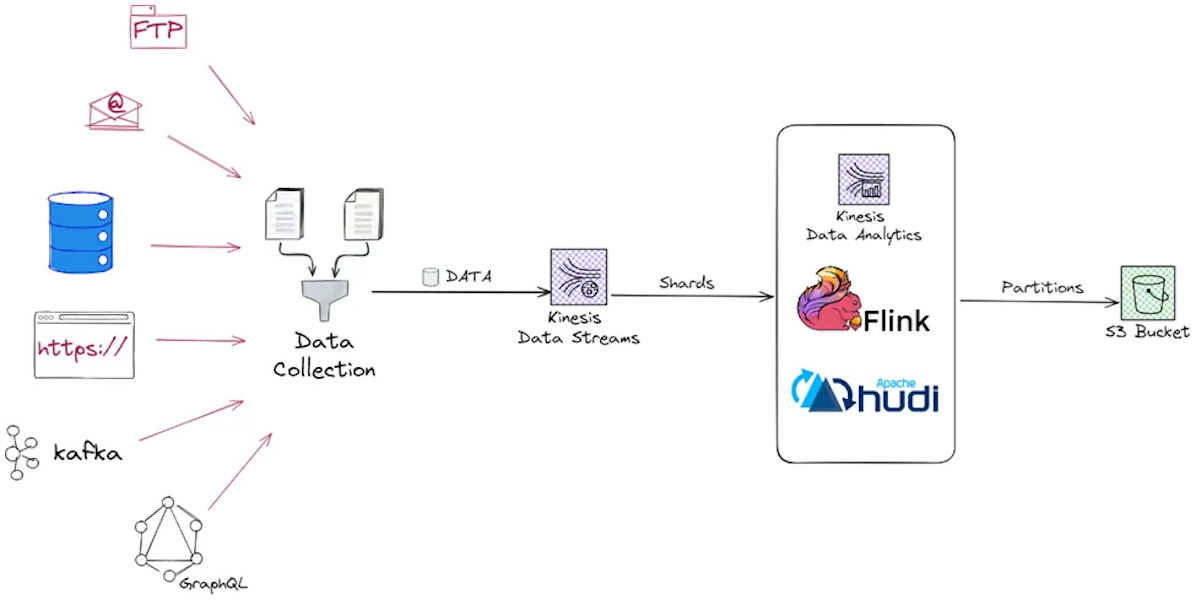
Build Real Time Streaming Pipeline with Kinesis, Apache Flink and Apache Hudi with Hands-onApril 21, 2024 by Md Shahid Afridi Papache flinkawsstreamingdata lakehouseincremental processing
Cost Optimization Strategies for scalable Data LakehouseMarch 22, 2024 by Suresh Hasundiawsapache sparkdata lakehouseperformancehalodoc
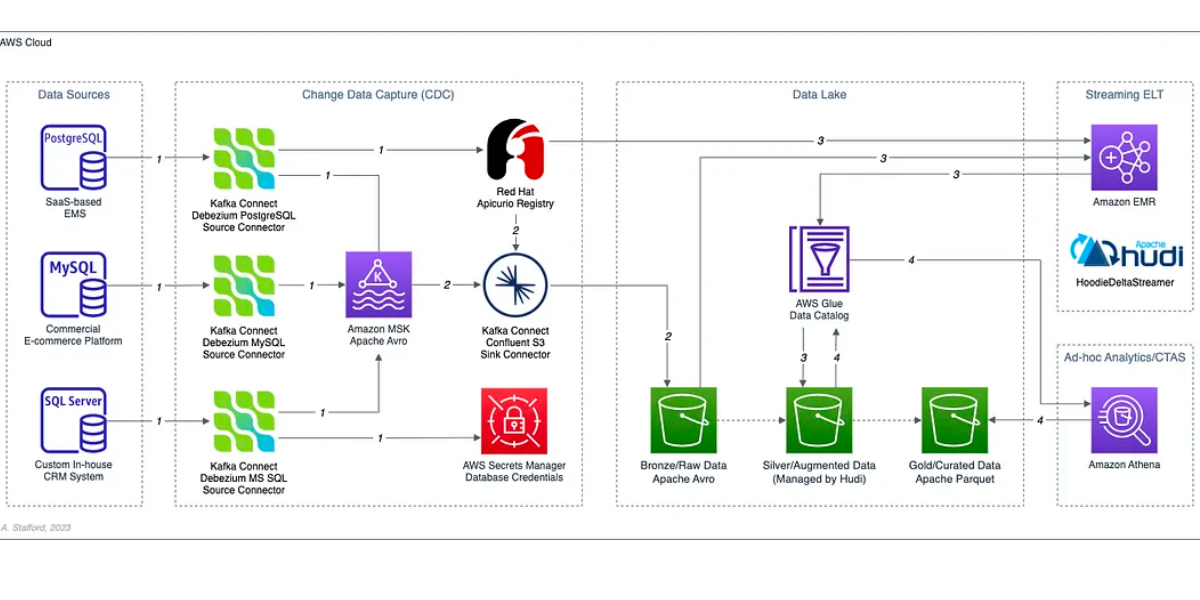
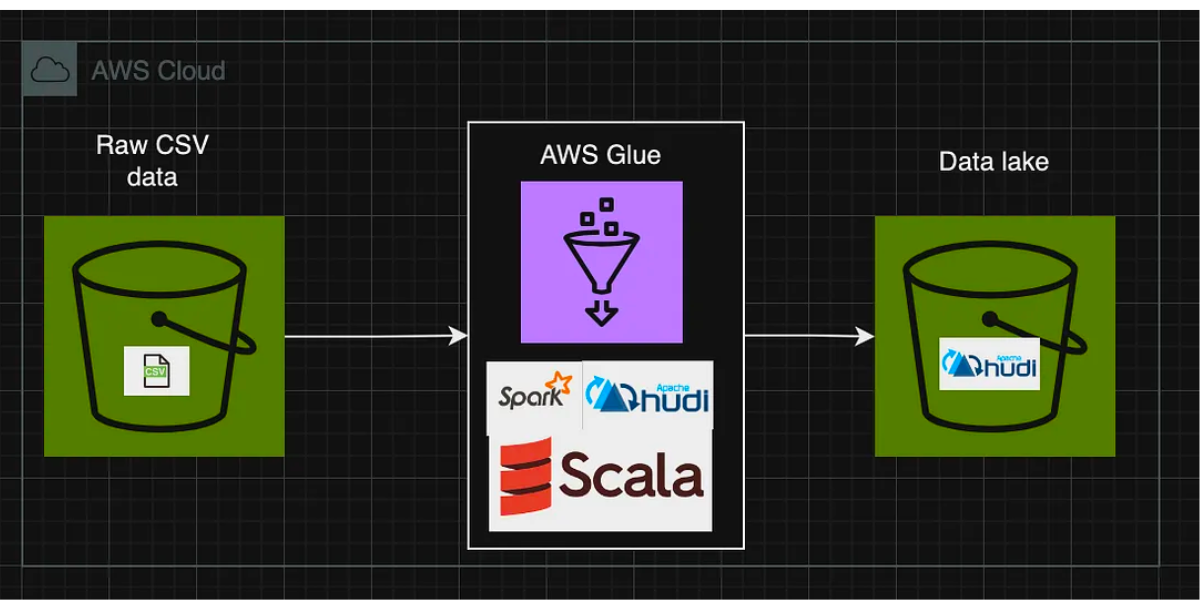
Building Data Lakes on AWS with Kafka Connect, Debezium, Apicurio Registry, and Apache HudiFebruary 27, 2024 by Gary A. Staffordbeginnerapache kafkadebeziumapicurio registryawsapache sparkhudi streamer
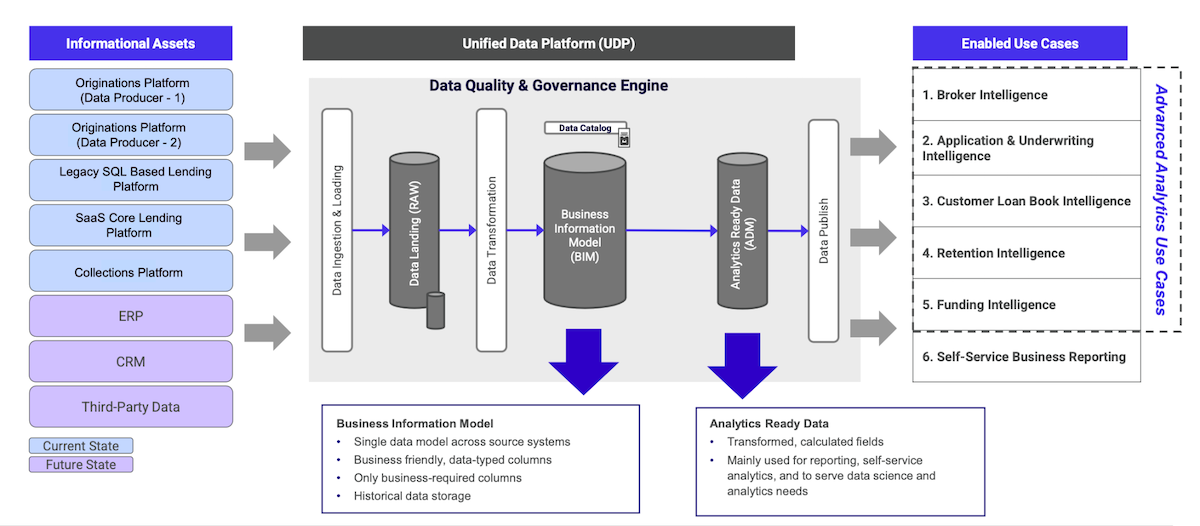
Empowering data-driven excellence: How the Bluestone Data Platform embraced data mesh for successFebruary 27, 2024 by Toney Thomas, Ben Vengerovsky and Rada Stanicdata meshaws
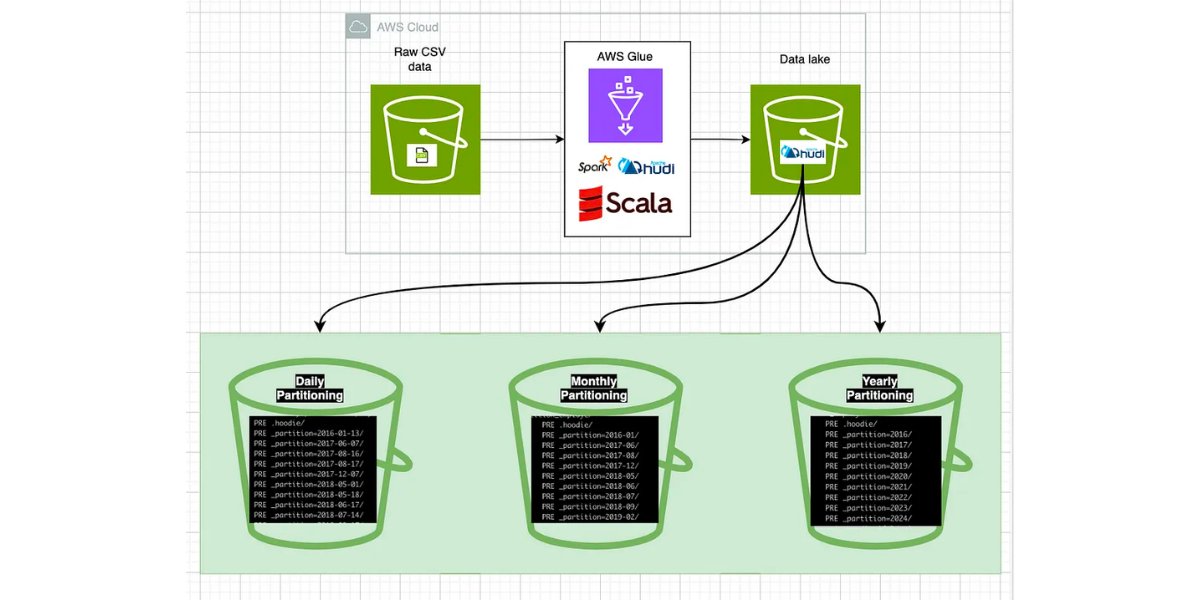
Apache Hudi: Managing Partition on a petabyte-scale tableFebruary 4, 2024 by Krishna Prasadawsapache spark
Leverage Partition Paths of your data lake tables to Optimize Data Retrieval Costs on the cloudJanuary 30, 2024 by Krishna Prasadawsperformanceapache spark
Use Amazon Athena with Spark SQL for your open-source transactional table formatsJanuary 24, 2024 by Pathik Shah, Raj Devnathbeginnerqueryingclusteringcompactionapache icebergawsdelta lake