Announcing Apache Hudi 1.0 and the Next Generation of Data Lakehouses
Overview
We are thrilled to announce the release of Apache Hudi 1.0, a landmark achievement for our vibrant community that defines what the next generation of data lakehouses should achieve. Hudi pioneered transactional data lakes in 2017, and today, we live in a world where this technology category is mainstream as the “Data Lakehouse”. The Hudi community has made several key, original, and first-of-its-kind contributions to this category, as shown below, compared to when other OSS alternatives emerged. This is an incredibly rare feat for a relatively small OSS community to sustain in a fiercely competitive commercial data ecosystem. On the other hand, it also demonstrates the value of deeply understanding the technology category within a focused open-source community. So, I first want to thank/congratulate the Hudi community and the 60+ contributors for making 1.0 happen.

This release is more than just a version increment—it advances the breadth of Hudi’s feature set and its architecture's robustness while bringing fresh innovation to shape the future. This post reflects on how technology and the surrounding ecosystem have evolved, making a case for a holistic “Data Lakehouse Management System” (DLMS) as the new Northstar. For most of this post, we will deep dive into the latest capabilities of Hudi 1.0 that make this evolution possible.
Evolution of the Data Lakehouse
Technologies must constantly evolve—Web 3.0, cellular tech, programming language generations—based on emerging needs. Data lakehouses are no exception. This section explores the hierarchy of such needs for data lakehouse users. The most basic need is the “table format” functionality, the foundation for data lakehouses. Table format organizes the collection of files/objects into tables with snapshots, schema, and statistics tracking, enabling higher abstraction. Furthermore, table format dictates the organization of files within each snapshot, encoding deletes/updates and metadata about how the table changes over time. Table format also provides protocols for various readers and writers and table management processes to handle concurrent access and provide ACID transactions safely. In the last five years, leading data warehouse and cloud vendors have integrated their proprietary SQL warehouse stack with open table formats. While they mostly default to their closed table formats and the compute engines remain closed, this welcome move provides users an open alternative for their data.
However, the benefits of a format end there, and now a table format is just the tip of the iceberg. Users require an end-to-end open data lakehouse, and modern data lakehouse features need a sophisticated layer of open-source software operating on data stored in open table formats. For example, Optimized writers can balance cost and performance by carefully managing file sizes using the statistics maintained in the table format or catalog syncing service that can make data in Hudi readily available to half a dozen catalogs open and closed out there. Hudi shines by providing a high-performance open table format as well as a comprehensive open-source software stack that can ingest, store, optimize and effectively self-manage a data lakehouse. This distinction between open formats and open software is often lost in translation inside the large vendor ecosystem in which Hudi operates. Still, it has been and remains a key consideration for Hudi’s users to avoid compute-lockin to any given data vendor. The Hudi streamer tool, e.g., powers hundreds of data lakes by ingesting data seamlessly from various sources at the convenience of a single command in a terminal.

Moving forward with 1.0, the community has debated these key points and concluded that we need more open-source “software capabilities” that are directly comparable with DBMSes for two main reasons.
Significantly expand the technical capabilities of a data lakehouse: Many design decisions in Hudi have been inspired by databases (see here for a layer-by-layer mapping) and have delivered significant benefits to the community. For example, Hudi’s indexing mechanisms deliver the fast update performance the project has come to be known for. We want to generalize such features across writers and queries and introduce new capabilities like fast metastores for query planning, support for unstructured/multimodal data and caching mechanisms that can be deeply integrated into (at least) open-source query engines in the ecosystem. We also need concurrency control that works for lakehouse workloads instead of employing techniques applicable to OLTP databases at the surface level.
We also need a database-like experience: We originally designed Hudi as a software library that can be embedded into different query/processing engines for reading/writing/managing tables. This model has been a great success within the existing data ecosystem, which is familiar with scheduling jobs and employing multiple engines for ETL and interactive queries. However, for a new user wanting to explore data lakehouses, there is no piece of software to easily install and explore all functionality packaged coherently. Such data lakehouse functionality packaged and delivered like a typical database system unlocks new use cases. For example, with such a system, we could bring HTAP capabilities to the data lakehouses on faster cloud storage/row-oriented formats, finally making it a low-latency data serving layer.
If combined, we would gain a powerful database built on top of the data lake(house) architecture—a data lakehouse management system (DLMS)—that we believe the industry needs.
Key Features in Hudi 1.0
In Hudi 1.0, we’ve delivered a significant expansion of data lakehouse technical capabilities discussed above inside Hudi’s storage engine layer. Storage engines (a.k.a database engines) are standard database components that sit on top of the storage/file/table format and are wrapped by the DBMS layer above, handling the core read/write/management functionality. In the figure below, we map the Hudi components with the seminal Architecture of a Database System paper (see page 4) to illustrate the standard layering discussed. If the layering is implemented correctly, we can deliver the benefits of the storage engine to even other table formats, which may lack such fully-developed open-source software for table management or achieving high performance, via interop standards defined in projects like Apache XTable (Incubating).

Figure: Apache Hudi Database Architecture
Regarding full-fledged DLMS functionality, the closest experience Hudi 1.0 offers is through Apache Spark. Users can deploy a Spark server (or Spark Connect) with Hudi 1.0 installed, submit SQL/jobs, orchestrate table services via SQL commands, and enjoy new secondary index functionality to speed up queries like a DBMS. Subsequent releases in the 1.x release line and beyond will continuously add new features and improve this experience.
In the following sections, let’s dive into what makes Hudi 1.0 a standout release.
New Time and Timeline
For the familiar user, time is a key concept in Hudi. Hudi’s original notion of time was instantaneous, i.e., actions that modify the table appear to take effect at a given instant. This was limiting when designing features like non-blocking concurrency control across writers, which needs to reason about actions more as an “interval” to detect other conflicting actions. Every action on the Hudi timeline now gets a requested and a completion time; Thus, the timeline layout version has bumped up in the 1.0 release. Furthermore, to ease the understanding and bring consistency around time generation for users and implementors, we have formalized the adoption of TrueTime semantics. The default implementation assures forward-moving clocks even with distributed processes, assuming a maximum tolerable clock skew similar to OLTP/NoSQL stores adopting TrueTime.

Figure: Showing actions in Hudi 1.0 modeled as an interval of two instants: requested and completed
Hudi tables are frequently updated, and users also want to retain a more extended action history associated with the table. Before Hudi 1.0, the older action history in a table was archived for audit access. But, due to the lack of support for cloud storage appends, access might become cumbersome due to tons of small files. In Hudi 1.0, we have redesigned the timeline as an LSM tree, which is widely adopted for cases where good write performance on temporal data is desired.
In the Hudi 1.0 release, the LSM timeline is heavily used in the query planning to map requested and completion times across Apache Spark, Apache Flink and Apache Hive. Future releases plan to leverage this to unify the timeline's active and history components, providing infinite retention of table history. Micro benchmarks show that the LSM timeline can be pretty efficient, even committing every 30 seconds for 10 years with about 10M instants, further cementing Hudi’s table format as the most suited for frequently written tables.
| Number of actions | Instant Batch Size | Read cost (just times) | Read cost (along with action metadata) | Total file size |
|---|---|---|---|---|
| 10000 | 10 | 32ms | 150ms | 8.39MB |
| 20000 | 10 | 51ms | 188ms | 16.8MB |
| 10000000 | 1000 | 3400ms | 162s | 8.4GB |
Secondary Indexing for Faster Lookups
Indexes are core to Hudi’s design, so much so that even the first pre-open-source version of Hudi shipped with indexes to speed up writes. However, these indexes were limited to the writer's side, except for record indexes in 0.14+ above, which were also integrated with Spark SQL queries. Hudi 1.0 generalizes indexes closer to the indexing functionality found in relational databases, supporting indexes on any secondary column across both writer and readers. Hudi 1.0 also supports near-standard SQL syntax for creating/dropping indexes on different columns via Spark SQL, along with an asynchronous indexing table service to build indexes without interrupting the writers.

Figure: the indexing subsystem in Hudi 1.0, showing different types of indexes
With secondary indexes, queries and DMLs scan a much-reduced amount of files from cloud storage, dramatically reducing costs (e.g., on engines like AWS Athena, which price by data scanned) and improving query performance for queries with low to even moderate amount of selectivity. On a benchmark of a query on web_sales table (from 10 TB tpc-ds dataset), with file groups - 286,603, total records - 7,198,162,544 and cardinality of secondary index column in the ~ 1:150 ranges, we see a remarkable ~95% decrease in latency.
| Run 1 | Total Query Latency w/o indexing skipping (secs) | Total Query Latency with secondary index skipping (secs) | % decrease |
|---|---|---|---|
| 1 | 252 | 31 | ~88% |
| 2 | 214 | 10 | ~95% |
| 3 | 204 | 9 | ~95% |
In Hudi 1.0, secondary indexes are only supported for Apache Spark, with planned support for other engines in Hudi 1.1, starting with Flink, Presto and Trino.
Bloom Filter indexes
Bloom filter indexes have existed on the Hudi writers for a long time. It is one of the most performant and versatile indexes users prefer for “needle-in-a-haystack” deletes/updates or de-duplication. The index works by storing special footers in base files around min/max key ranges and a dynamic bloom filter that adapts to the file size and can automatically handle partitioning/skew on the writer's path. Hudi 1.0 introduces a newer kind of bloom filter index for Spark SQL while retaining the writer-side index as-is. The new index stores bloom filters in the Hudi metadata table and other secondary/record indexes for scalable access, even for huge tables, since the index is stored in fewer files compared to being stored alongside data files. It can be created using standard SQL syntax, as shown below. Subsequent queries on the indexed columns will use the bloom filters to speed up queries.
-- Create a bloom filter index on the driver column of the table `hudi_table`
CREATE INDEX idx_bloom_driver ON hudi_indexed_table USING bloom_filters(driver)
-- Create a bloom filter index on the column derived from expression `lower(rider)` of the table `hudi_table`
CREATE INDEX idx_bloom_rider ON hudi_indexed_table USING bloom_filters(rider) OPTIONS(expr='lower');
In future releases of Hudi, we aim to fully integrate the benefits of the older writer-side index into the new bloom index. Nonetheless, this demonstrates the adaptability of Hudi’s indexing system to handle different types of indexes on the table.
Partitioning replaced by Expression Indexes
An astute reader may have noticed above that the indexing is supported on a function/expression on a column. Hudi 1.0 introduces expression indexes similar to Postgres to generalize a two-decade-old relic in the data lake ecosystem - partitioning! At a high level, partitioning on the data lake divides the table into folders based on a column or a mapping function (partitioning function). When queries or operations are performed against the table, they can efficiently skip entire partitions (folders), reducing the amount of metadata and data involved. This is very effective since data lake tables span 100s of thousands of files. But, as simple as it sounds, this is one of the most common pitfalls around performance on the data lake, where new users use it like an index by partitioning based on a high cardinality column, resulting in lots of storage partitions/tiny files and abysmal write/query performance for no good reason. Further, tying storage organization to partitioning makes it inflexible to changes.

Figure: Shows index on a date expression when a different column physically partitions data
Hudi 1.0 treats partitions as a coarse-grained index on a column value or an expression of a column, as they should have been. To support the efficiency of skipping entire storage paths/folders, Hudi 1.0 introduces partition stats indexes that aggregate these statistics on the storage partition path level, in addition to doing so at the file level. Now, users can create different types of indexes on columns to achieve the effects of partitioning in a streamlined fashion using fewer concepts to achieve the same results. Along with support for other 1.x features, partition stats and expression indexes support will be extended to other engines like Presto, Trino, Apache Doris, and Starrocks with the 1.1 release.
Efficient Partial Updates
Managing large-scale datasets often involves making fine-grained changes to records. Hudi has long supported partial updates to records via the record payload interface. However, this usually comes at the cost of sacrificing engine-native performance by moving away from specific objects used by engines to represent rows. As users have embraced Hudi for incremental SQL pipelines on top of dbt/Spark or Flink Dynamic Tables, there was a rise in interest in making this much more straightforward and mainstream. Hudi 1.0 introduces first-class support for partial updates at the log format level, enabling MERGE INTO SQL statements to modify only the changed fields of a record instead of rewriting/reprocessing the entire row.
Partial updates improve query and write performance simultaneously by reducing write amplification for writes and the amount of data read by Merge-on-Read snapshot queries. It also achieves much better storage utilization due to fewer bytes stored and improved compute efficiency over existing partial update support by retaining vectorized engine-native processing. Using the 1TB Brooklyn benchmark for write performance, we observe about 2.6x improvement in Merge-on-Read query performance due to an 85% reduction in write amplification. For random write workloads, the gains can be much more pronounced. Below shows a second benchmark for partial updates, 1TB MOR table, 1000 partitions, 80% random updates. 3/100 columns randomly updated.
| Full Record Update | Partial Update | Gains | |
|---|---|---|---|
| Update latency (s) | 2072 | 1429 | 1.4x |
| Bytes written (GB) | 891.7 | 12.7 | 70.2x |
| Query latency (s) | 164 | 29 | 5.7x |
This also lays the foundation for managing unstructured and multimodal data inside a Hudi table and supporting wide tables efficiently for machine learning use cases.
Merge Modes and Custom Mergers
One of the most unique capabilities Hudi provides is how it helps process streaming data. Specifically, Hudi has, since the very beginning, supported merging records pre-write (to reduce write amplification), during write (against an existing record in storage with the same record key) and reads (for MoR snapshot queries), using a precombine or ordering field. This helps implement event time processing semantics, widely supported by stream processing systems, on data lakehouse storage. This helps integrate late-arriving data into Hudi tables without causing weird movement of record state back in time. For example, if an older database CDC record arrives late and gets committed as the new value, the state of the record would be incorrect even though the writes to the table themselves were serialized in some order.
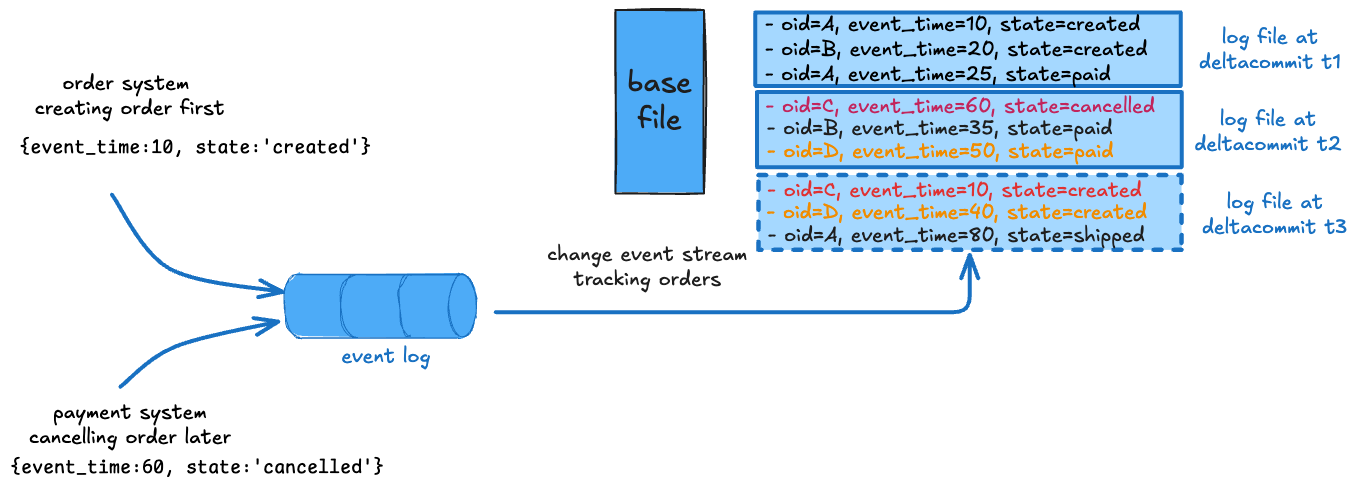
Figure: Shows EVENT_TIME_ORDERING where merging reconciles state based on the highest event_time
Prior Hudi versions supported this functionality through the record payload interface with built-in support for a pre-combine field on the default payloads. Hudi 1.0 makes these two styles of processing and merging changes first class by introducing merge modes within Hudi.
| Merge Mode | What does it do? |
|---|---|
| COMMIT_TIME_ORDERING | Picks record with highest completion time/instant as final merge result i.e., standard relational semantics or arrival time processing |
| EVENT_TIME_ORDERING | Default (for now, to ease migration). Picks record with the highest value for a user-specified ordering/precombine field as the final merge result. |
| CUSTOM | Uses a user-provided RecordMerger implementation to produce final merge result (similar to stream processing processor APIs) |
Like partial update support, the new RecordMerger API provides a more efficient engine-native alternative to the older RecordPayload interface through native objects and vectorized processing on EVENT_TIME_ORDERING merge modes. In future versions, we intend to change the default to COMMIT_TIME_ORDERING to provide simple, out-of-the-box relational table semantics.
Non-Blocking Concurrency Control for Streaming Writes
We have expressed dissatisfaction with the optimistic concurrency control approaches employed on the data lakehouse since they appear to paint the problem with a broad brush without paying attention to the nuances of the lakehouse workloads. Specifically, contention is much more common in data lakehouses, even for Hudi, the only data lakehouse storage project capable of asynchronously compacting delta updates without failing or causing retries on the writer. Ultimately, data lakehouses are high-throughput systems, and failing concurrent writers to handle contention can waste expensive compute clusters. Streaming and high-frequency writes often require fine-grained concurrency control to prevent bottlenecks.
Hudi 1.0 introduces a new non-blocking concurrency control (NBCC) designed explicitly for data lakehouse workloads, using years of experience gained supporting some of the largest data lakes on the planet in the Hudi community. NBCC enables simultaneous writing from multiple writers and compaction of the same record without blocking any involved processes. This is achieved by simply lightweight distributed locks and TrueTime semantics discussed above. (see RFC-66 for more)

Figure: Two streaming jobs in action writing to the same records concurrently on different columns.
NBCC operates with streaming semantics, tying together concepts from previous sections. Data necessary to compute table updates are emitted from an upstream source, and changes and partial updates can be merged in any of the merge modes above. For example, in the figure above, two independent Flink jobs enrich different table columns in parallel, a pervasive pattern seen in stream processing use cases. Check out this blog for a full demo. We also expect to support NBCC across other compute engines in future releases.
Backwards Compatible Writing
If you are wondering: “All of this sounds cool, but how do I upgrade?” we have put a lot of thought into making that seamless. Hudi has always supported backward-compatible reads to older table versions. Table versions are stored in table properties unrelated to the software binary version. The supported way of upgrading has been to first migrate readers/query engines to new software binary versions and then upgrade the writers, which will auto-upgrade the table if there is a table version change between the old and new software binary versions. Upon community feedback, users expressed the need to be able to do upgrades on the writers without waiting on the reader side upgrades and reduce any additional coordination necessary within different teams.
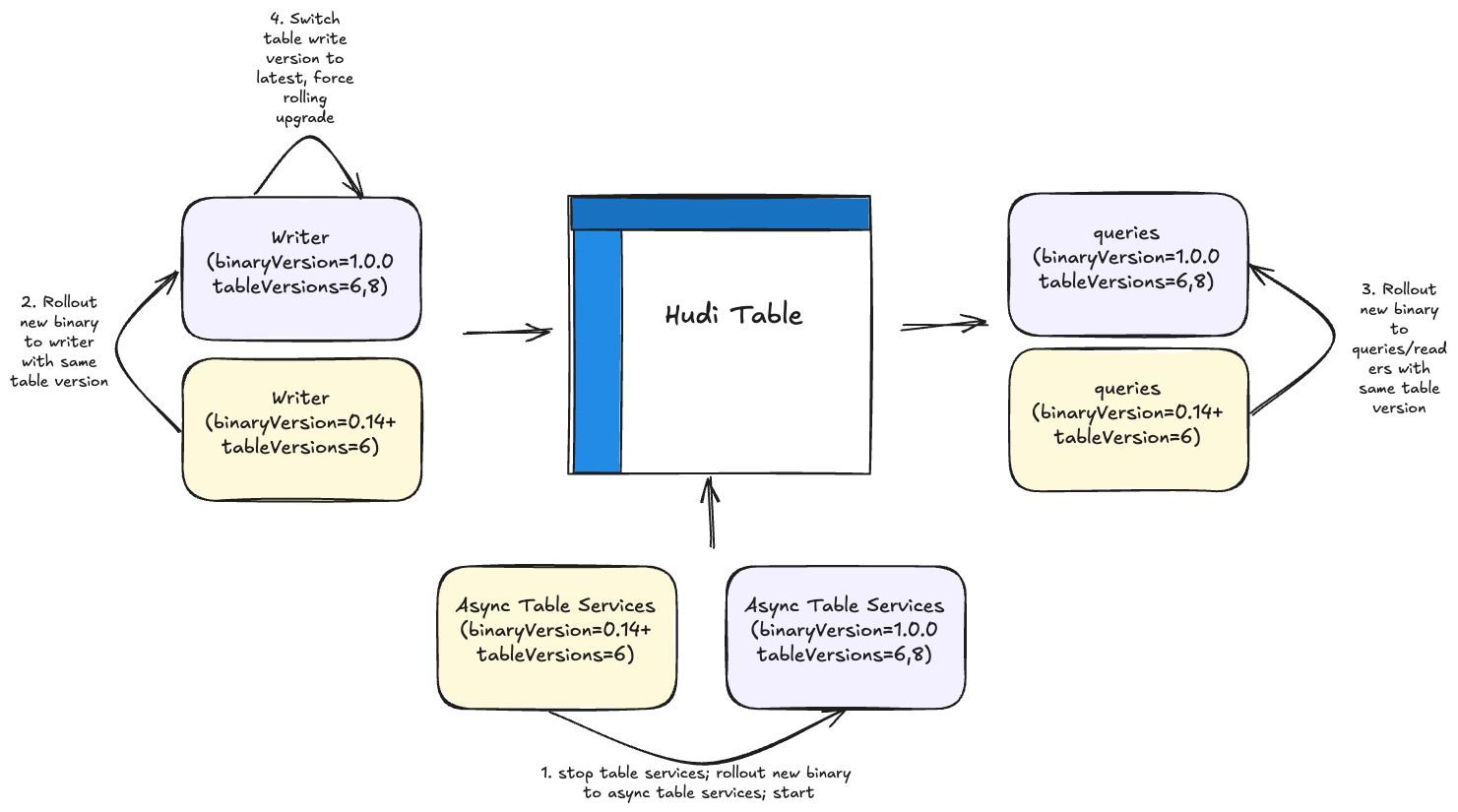
Figure: 4-step process for painless rolling upgrades to Hudi 1.0
Hudi 1.0 introduces backward-compatible writing to achieve this in 4 steps, as described above. Hudi 1.0 also automatically handles any checkpoint translation necessary as we switch to completion time-based processing semantics for incremental and CDC queries. The Hudi metadata table has to be temporarily disabled during this upgrade process but can be turned on once the upgrade is completed successfully. Please read the release notes carefully to plan your migration.
What’s Next?
Hudi 1.0 is a testament to the power of open-source collaboration. This release embodies the contributions of 60+ developers, maintainers, and users who have actively shaped its roadmap. We sincerely thank the Apache Hudi community for their passion, feedback, and unwavering support.
The release of Hudi 1.0 is just the beginning. Our current roadmap includes exciting developments across the following planned releases:
- 1.0.1: First bug fix, patch release on top of 1.0, which hardens the functionality above and makes it easier. We intend to publish additional patch releases to aid migration to 1.0 as the bridge release for the community from 0.x.
- 1.1: Faster writer code path rewrite, new indexes like bitmap/vector search, granular record-level change encoding, Hudi storage engine APIs, abstractions for cross-format interop.
- 1.2: Multi-table transactions, platform services for reverse streaming from Hudi etc., Multi-modal data + indexing, NBCC clustering
- 2.0: Server components for DLMS, caching and metaserver functionality.
Hudi releases are drafted collaboratively by the community. If you don’t see something you like here, please help shape the roadmap together.
Get Started with Apache Hudi 1.0
Are you ready to experience the future of data lakehouses? Here’s how you can dive into Hudi 1.0:
- Documentation: Explore Hudi’s Documentation and learn the concepts.
- Quickstart Guide: Follow the Quickstart Guide to set up your first Hudi project.
- Upgrading from a previous version? Follow the migration guide and contact the Hudi OSS community for help.
- Join the Community: Participate in discussions on the Hudi Mailing List, Slack and GitHub.
- Follow us on social media: Linkedin, X/Twitter.
We can’t wait to see what you build with Apache Hudi 1.0. Let’s work together to shape the future of data lakehouses!
Crafted with passion for the Apache Hudi community.