54 posts tagged with "how-to"
View All Tags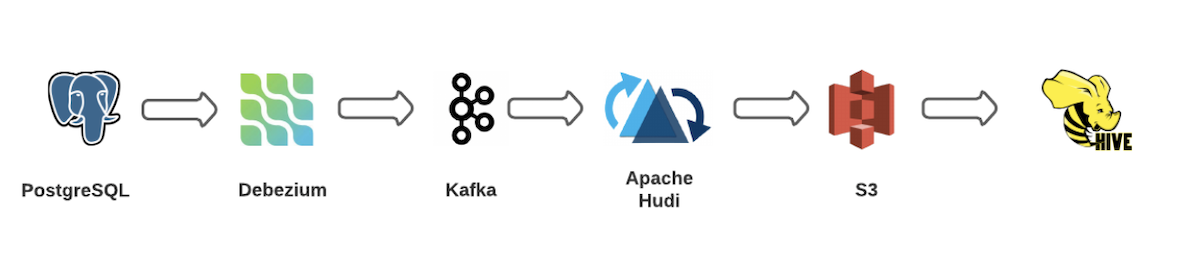
The Art of Building Open Data Lakes with Apache Hudi, Kafka, Hive, and Debezium
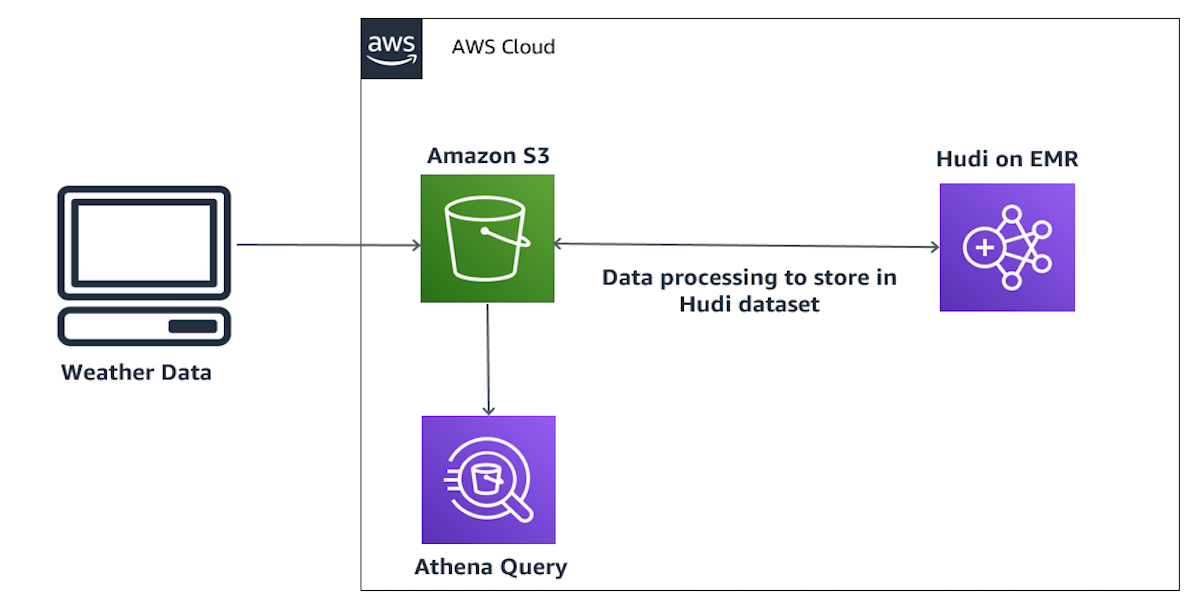
Part1: Query apache hudi dataset in an amazon S3 data lake with amazon athena : Read optimized queries
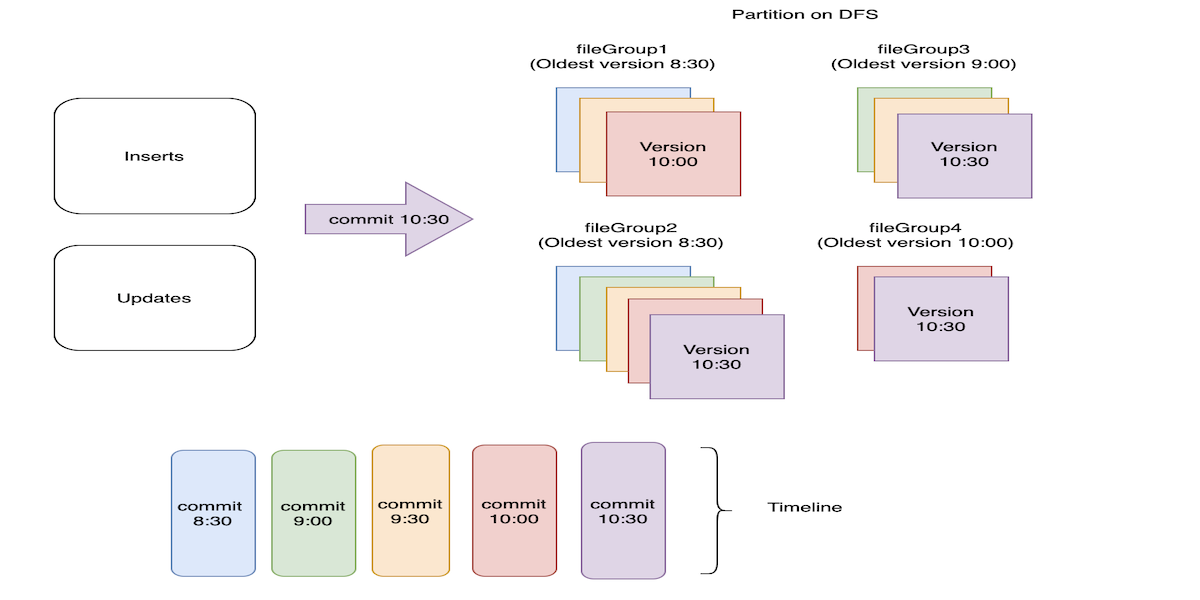
Employing correct configurations for Hudi's cleaner table service

Build Slowly Changing Dimensions Type 2 (SCD2) with Apache Spark and Apache Hudi on Amazon EMR
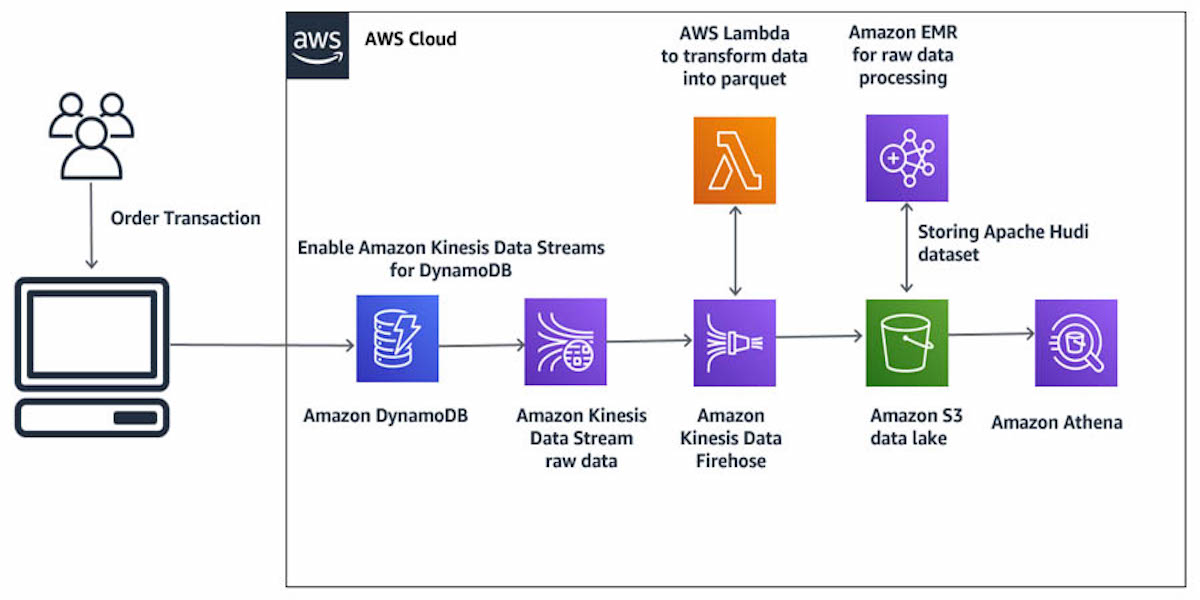
Build a data lake using amazon kinesis data stream for amazon dynamodb and apache hudi
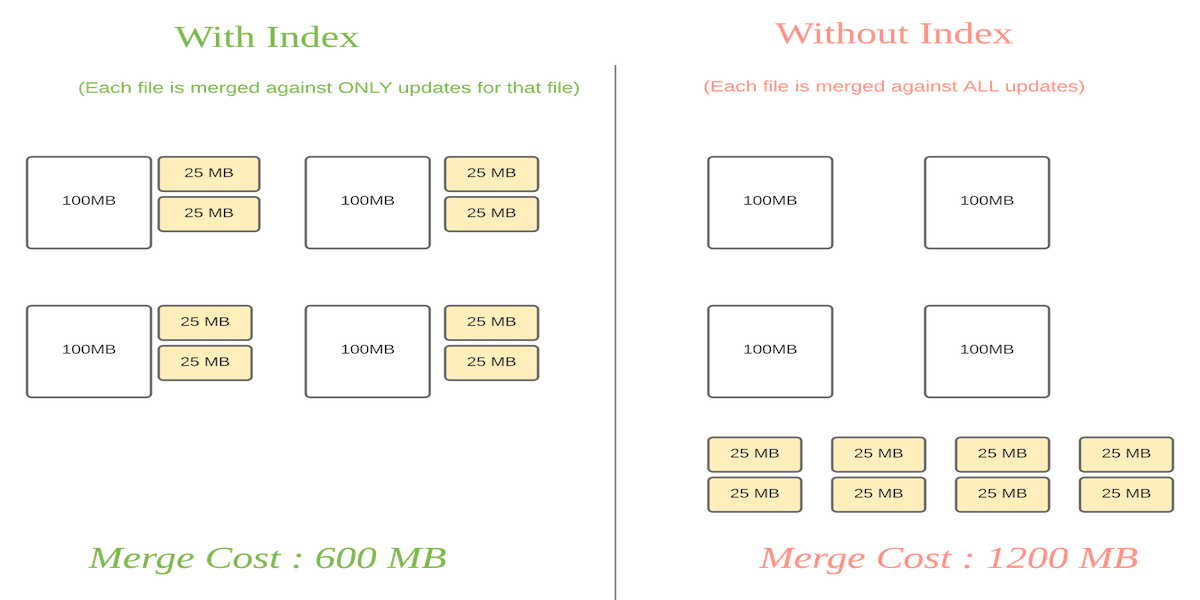
Employing the right indexes for fast updates, deletes in Apache Hudi

Data Lake Change Capture using Apache Hudi & Amazon AMS/EMR
Ingest multiple tables using Hudi
Async Compaction Deployment Models