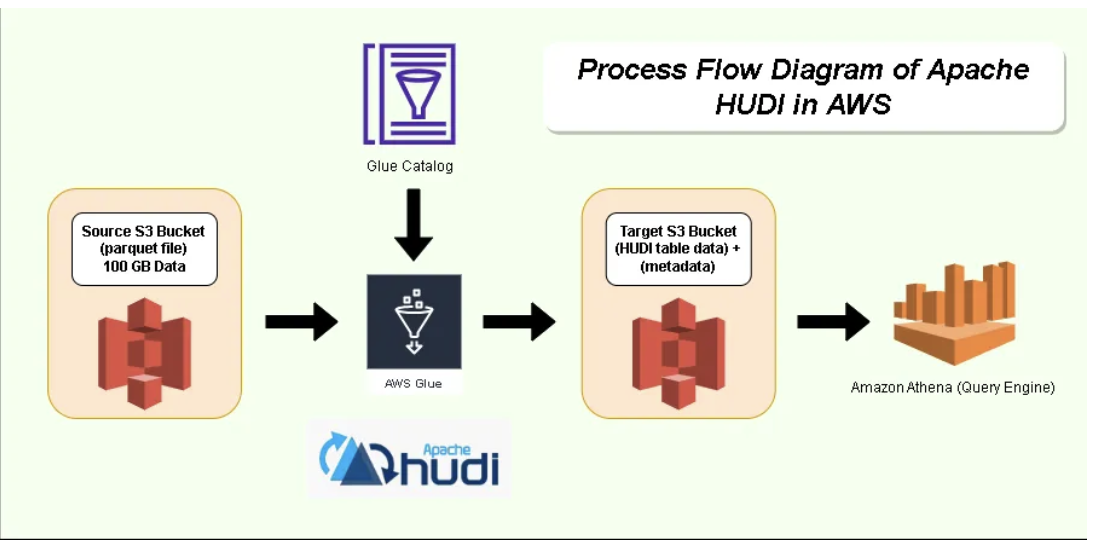
Create an Apache Hudi-based-near-real-time transactional data lake using AWS DMS, Amazon Kinesis, AWS Glue streaming ETL, and data visualization using Amazon QuickSightAugust 3, 2023 by Raj Ramasubbu, Sundeep Kumar and Rahul Sonawanecdcdmlaws
Data lake Table formats: Apache Iceberg vs Apache Hudi vs Delta lakeAugust 3, 2023 by Shashwat Pandeyapache icebergdelta lake
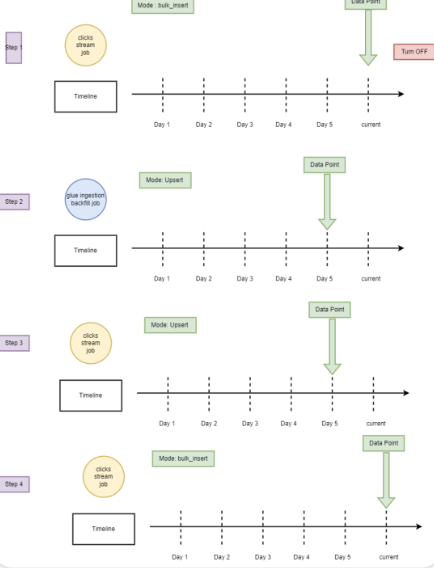
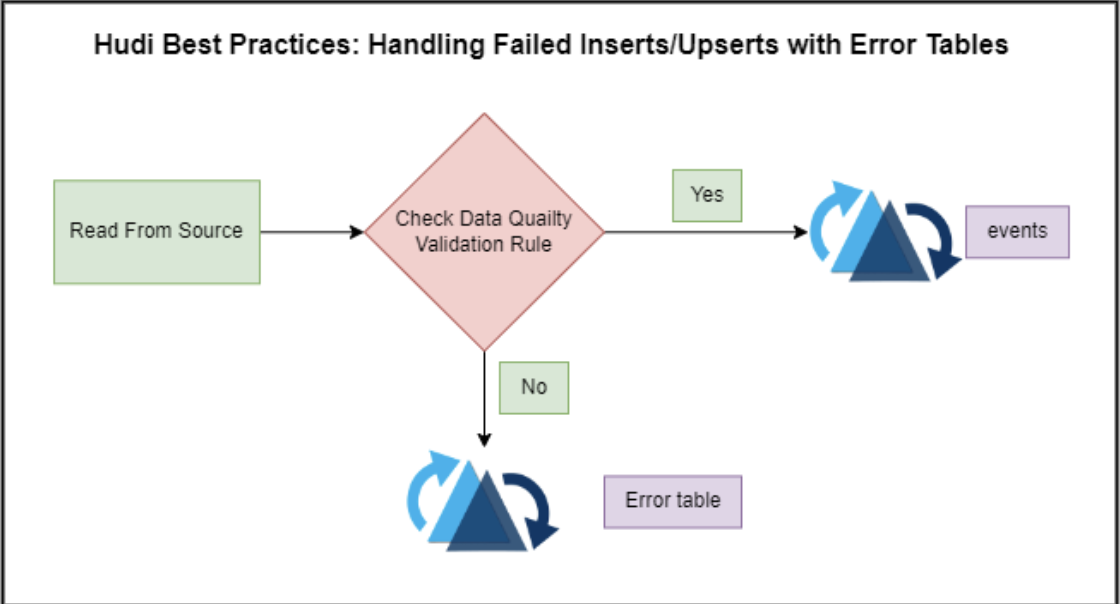
Backfilling Apache Hudi Tables in Production: Techniques & Approaches Using AWS Glue by Job Target LLCJuly 20, 2023 by Soumil Shahbackfillingawscode sample
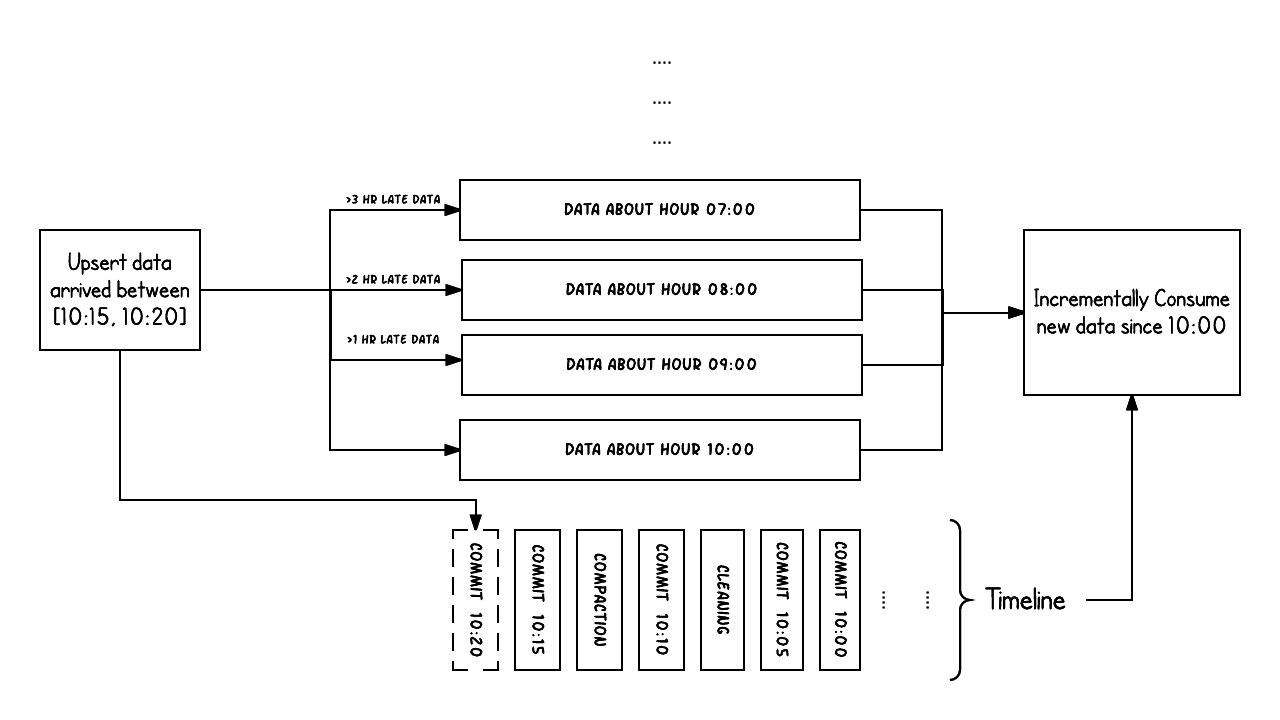
Hoodie Timeline: Foundational pillar for ACID transactionsJuly 9, 2023 by Sivabalan Narayananacidhudi timeline
Skip rocks and files: Turbocharge Trino queries with Hudi’s multi-modal indexing subsystemJuly 7, 2023 by Nadine Farah, Sagar Sumit and Cole Bowdenconferenceindexingtrinoquerying
What about Apache Hudi, Apache Iceberg, and Delta Lake?June 30, 2023 by Martin Jurado Pedrozavector searchcomparisondelta lakeapache iceberg