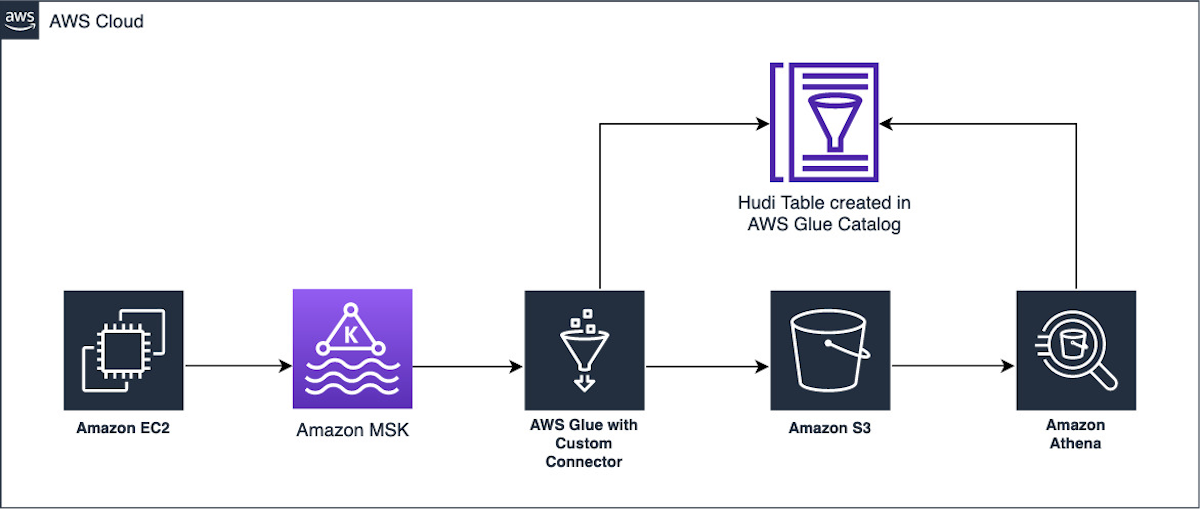
Ingest streaming data to Apache Hudi tables using AWS Glue and Apache Hudi DeltaStreamerOctober 6, 2022 by Vishal Pathak, Anand Prakash and Noritaka Sekiyamastreaminghudi streameraws
Building Streaming Data Lakes with Hudi and MinIOSeptember 20, 2022 by Matt Sarreldata lakehousestreamingminio
Data Lake / Lakehouse Guide: Powered by Data Lake Table Formats (Delta Lake, Iceberg, Hudi)August 25, 2022 by Simon Spätidata lakehousecomparisonairbyte
Implementation of SCD-2 (Slowly Changing Dimension) with Apache Hudi & SparkAugust 24, 2022 by Jayasheel Kalgal, Esha Dhing and Prashant Mishrawalmartscd
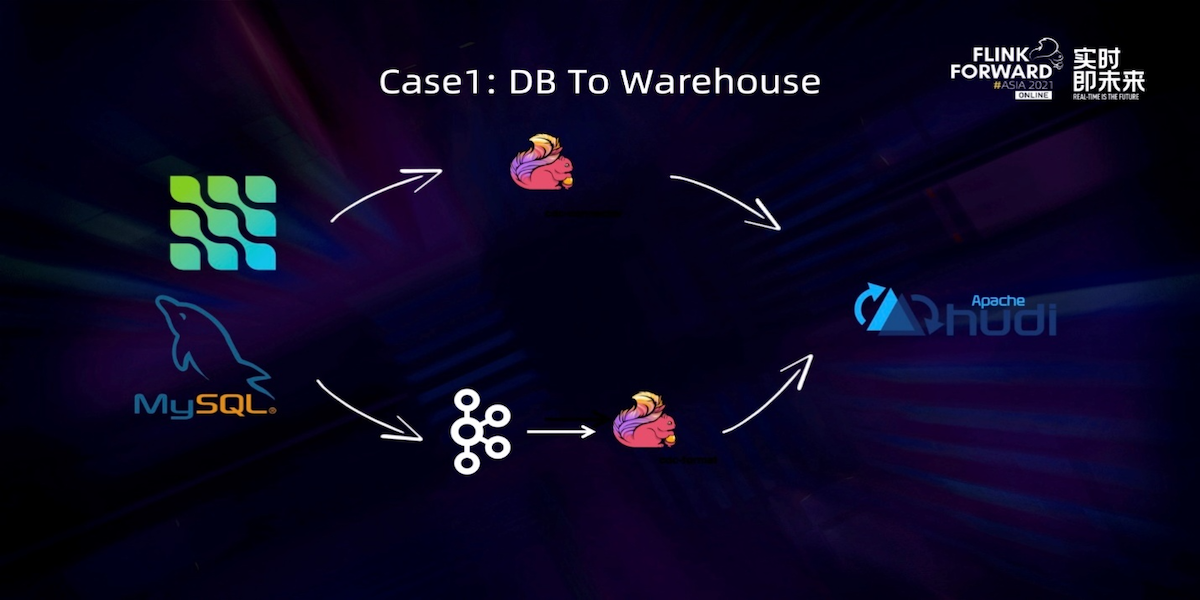
Use Flink Hudi to Build a Streaming Data Lake PlatformAugust 12, 2022 by Chen Yuzhao and Liu Dalongapache flinkalibabastreaming
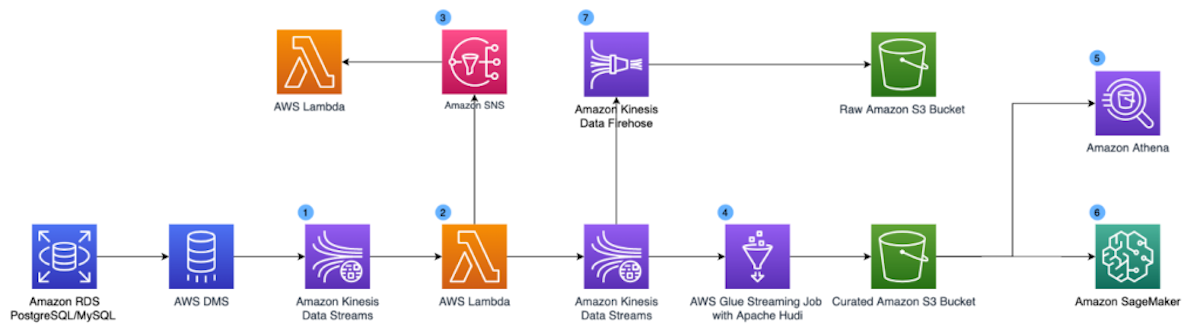
How NerdWallet uses AWS and Apache Hudi to build a serverless, real-time analytics platformAugust 9, 2022 by Kevin Chun and Dylan Qubiincremental processingaws
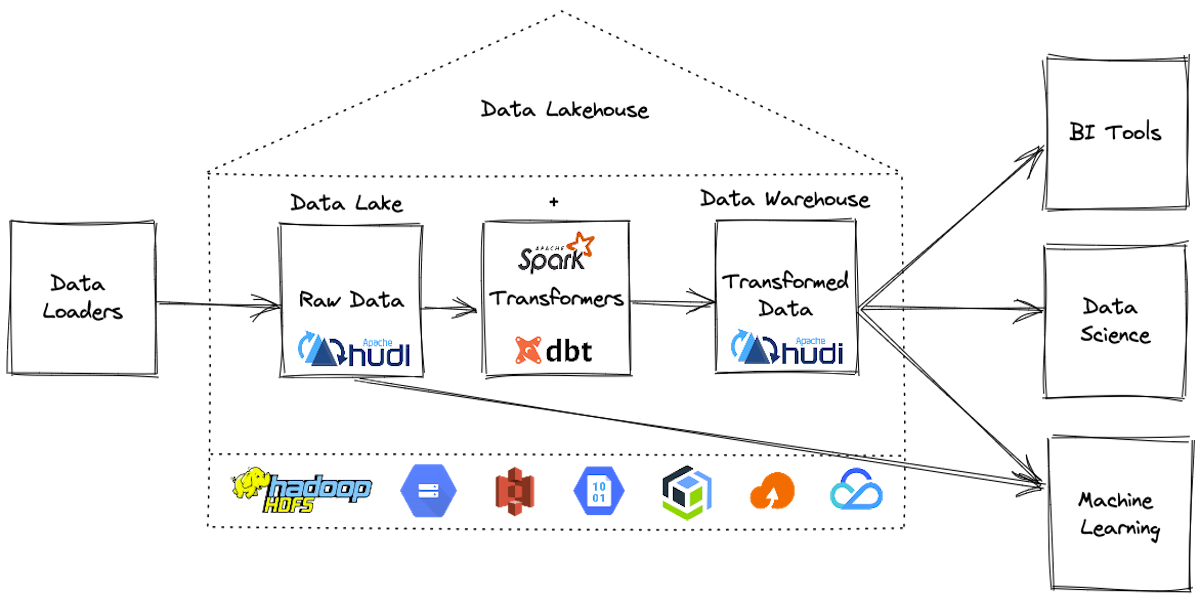
Build Open Lakehouse using Apache Hudi & dbtJuly 11, 2022 by Vinoth Govindarajanhudi streamerincremental processing
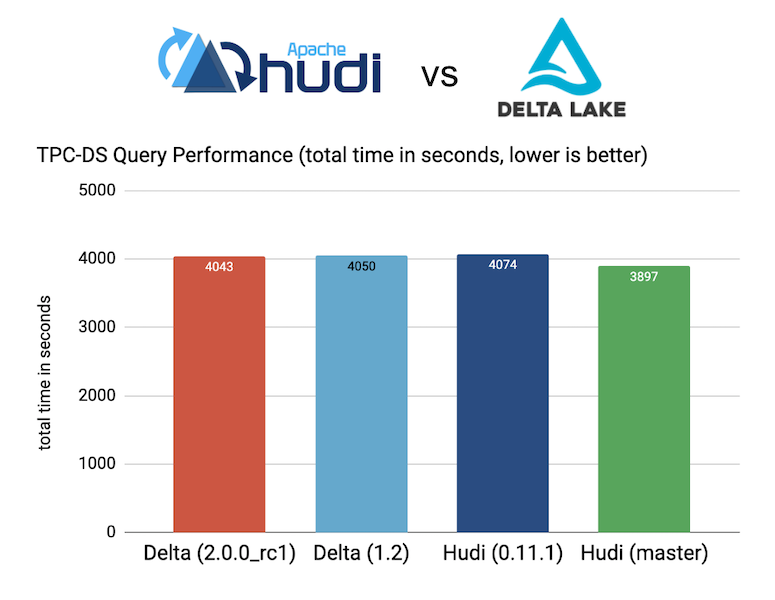
Apache Hudi vs Delta Lake - Transparent TPC-DS Lakehouse Performance BenchmarksJune 29, 2022 by Alexey Kudinkinperformancedata lakehousecomparisononehouse
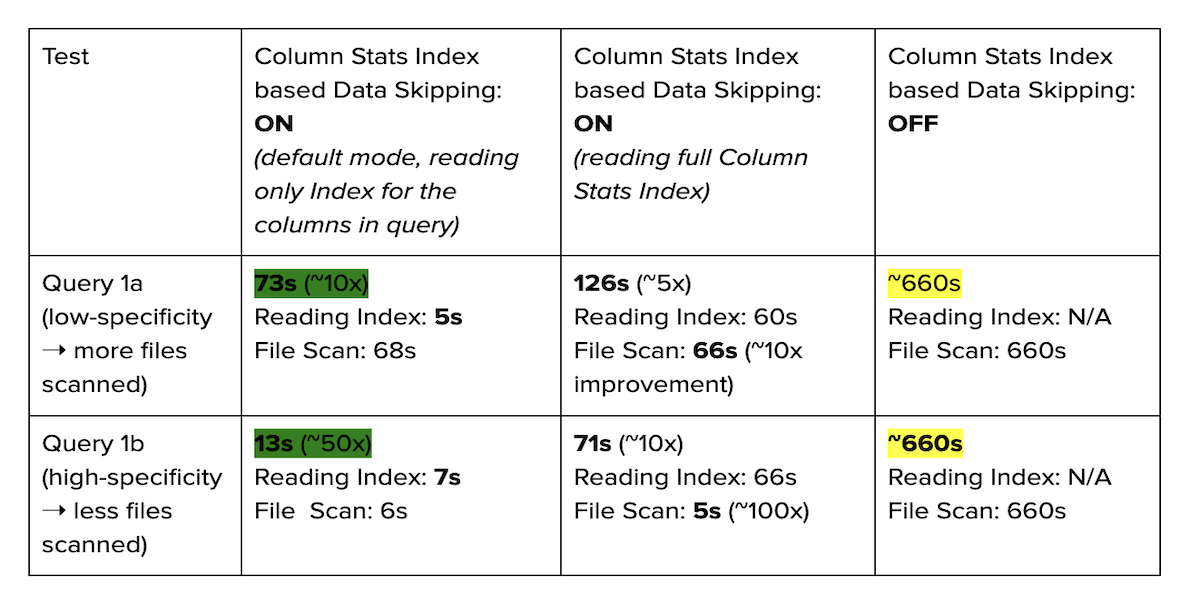
Hudi’s Column Stats Index and Data Skipping feature help speed up queries by an orders of magnitude!June 9, 2022 by Alexey Kudinkinindexingdata skippingonehouse