Modernizing Data Infrastructure at Peloton Using Apache HudiJuly 15, 2025 by Amaresh Bingumalla, Thinh Kenny Vu, Gabriel Wang, Arun Vasudevan in collaboration with Dipankar Mazumdarpeloton
How PayU built a secure enterprise AI assistant using Amazon BedrockJuly 15, 2025 by Deepesh Dhapola, Mudit Chopra, Rahmat Khan, Rahul Ghosh, Saikat Dey, and Sandeep Kumar Veerlapatiaws
How Stifel built a modern data platform using AWS Glue and an event-driven domain architectureJuly 7, 2025 by Amit Maindola and Srinivas Kandi, Hossein Johari, Ahmad Rawashdeh, Lei Mengawsdata governancedata lakehouse
Why Uber Built Hudi: The Strategic Decision Behind a Custom Table FormatJuly 3, 2025 by ThamizhElango Natarajanapache icebergdata lakehouseuber
Lakehouse Architecture - Apache Hudi and Apache IcebergJuly 2, 2025 by beCloudReadyapache icebergdata lakehouse
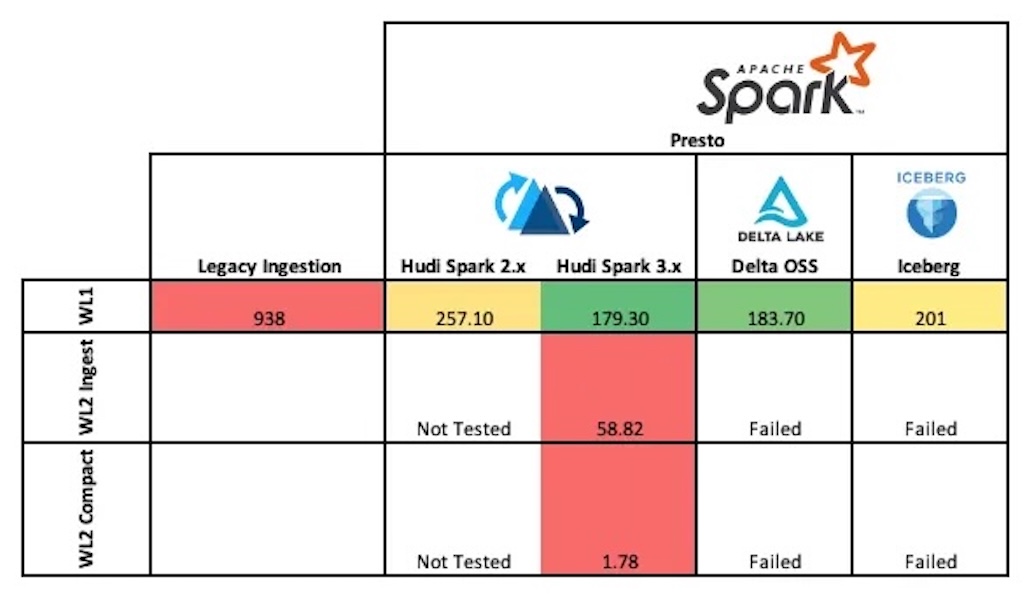
Scaling Complex Data Workflows at Uber Using Apache HudiJune 30, 2025 by Ankit Shrivastava in collaboration with Dipankaruber
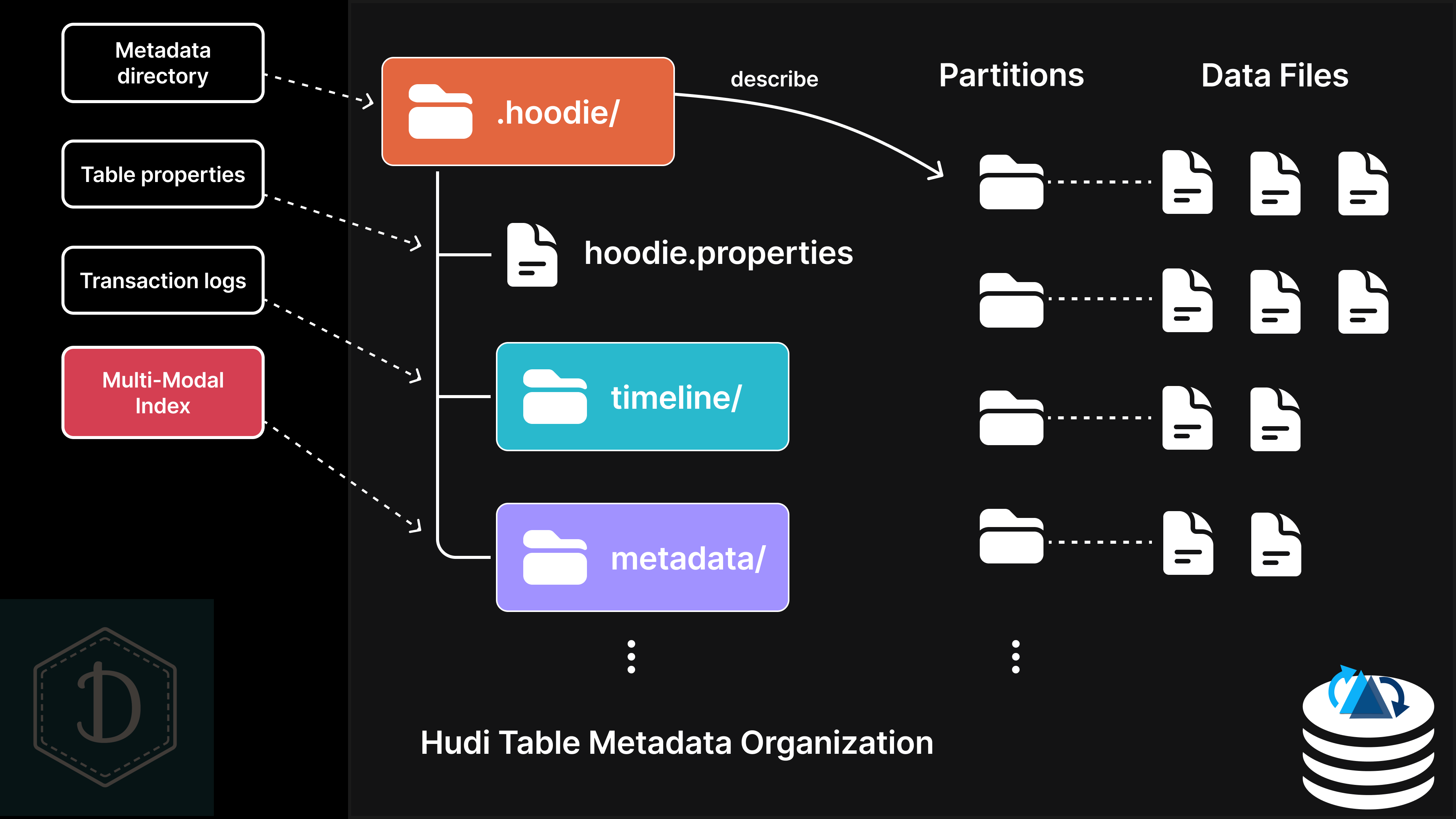
Apache Hudi does XYZ (1/10): File pruning with multi-modal indexJune 16, 2025 by Shiyan Xuapache sparkdata lakehouse
Optimizing Apache Hudi Workflows: Automation for Clustering, Resizing & ConcurrencyJune 13, 2025 by Halodoc, Apache Hudihalodocdata lakehouse
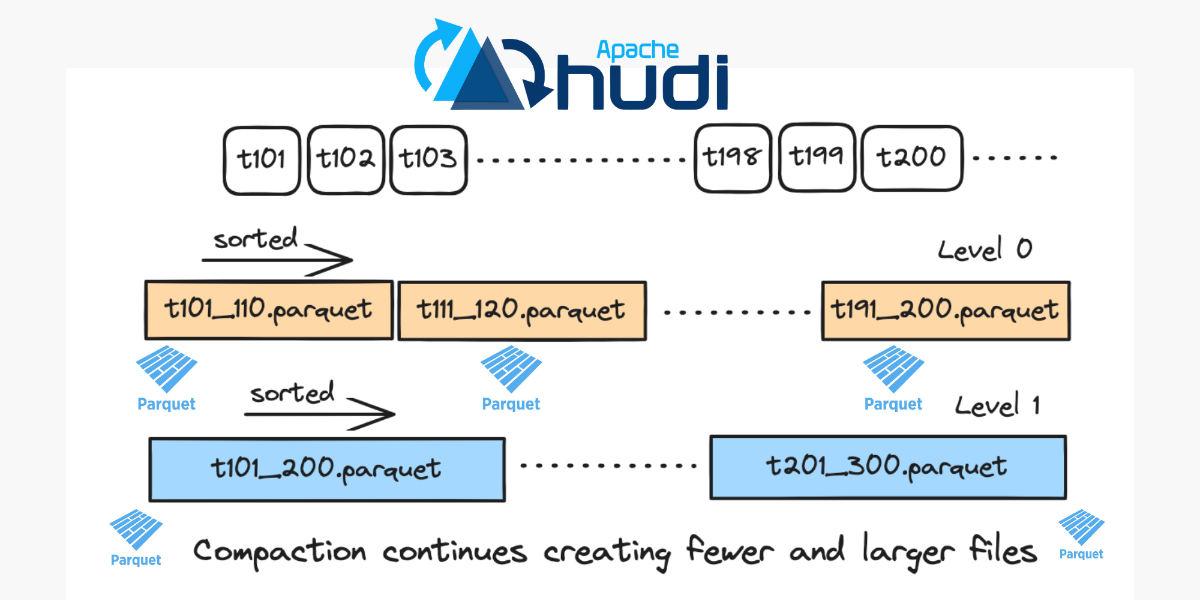
Exploring Apache Hudi’s New Log-Structured Merge (LSM) TimelineMay 29, 2025 by Dipankar Mazumdarlsm treeperformanceconcurrency control
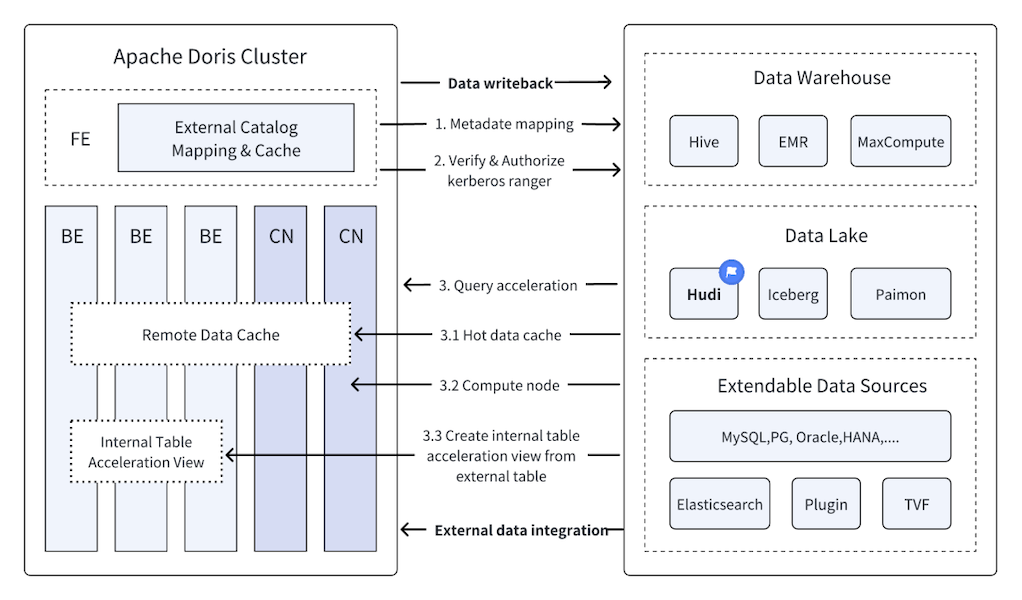
How Doris + Hudi Turned the Impossible Into the EverydayApril 14, 2025 by Zen Huaapache dorisquerying