Automatic Record Key Generation in Apache Hudi
In database systems, the primary key is a foundational design principle for managing data at the record level. Its function is to provide each record with a unique and stable logical identifier, which decouples the record's identity from its physical location on storage. While using direct physical address pointers (e.g., position inside a file being used as a key) can be convenient, the physical address can change when records are moved around within the table for things like clustering or z-ordering (called out here).
By using a primary key that is stable across record movement, a system can efficiently perform operations like updates and deletes, enabling critical features like relational integrity.
First-Class Support of Record Keys
Apache Hudi was the first lakehouse storage project to introduce the notion of record keys. For mutable workloads, this addressed a significant architectural challenge. In a typical data lake table, updating records usually required rewriting entire partitions—a process that is slow and expensive. By supporting the record key as the stable identifier for every record, Hudi offered unique and advanced capabilities among lakehouse frameworks:
- Hudi supports record-level indexing for directly locating records in file groups for highly efficient upserts and queries, and secondary indexes that enable performant lookups for predicates on non-record key fields.
- Hudi implements merge modes, standardizing record-merging semantics to handle requirements such as unordered events, duplicate records, and custom merge logic.
- By materializing record keys along with other record-level meta-fields, Hudi unlocks features such as efficient change data capture (CDC) that serves record-level change streams, near-infinite history for time-travel queries, and the clustering table service that can significantly optimize file sizes.
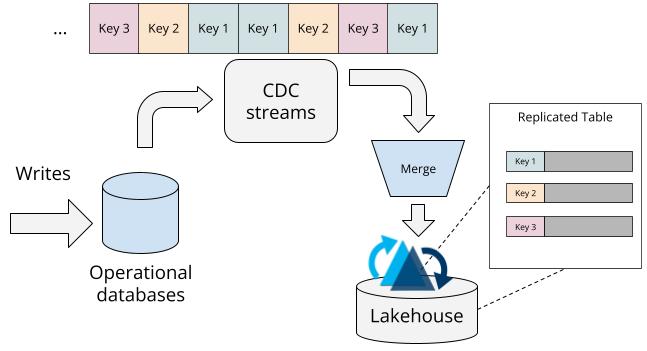
Append-only writes are very common in the data lakehouse, such as ingesting application logs streamed continuously from numerous servers or capturing clickstream events from user interactions on a website. Even for this kind of scenario, having record keys is beneficial in scenarios like concurrently running data-fixing backfill writers (e.g., a GDPR deletion process) with ongoing writers to the same table. Without record keys, engineers typically had to coordinate the backfill to run on different partitions than the active writes to avoid conflicts. With record keys and the support provided by Hudi’s concurrency control and merge modes, this restriction can be lifted, with Hudi handling the concurrent writes properly.
Given the advantages of supporting record keys, Hudi required users to set one or multiple record key fields when creating a table prior to release 0.14. However, this requirement created friction for users in cases where there were no natural record keys in the incoming stream for simply setting another config variable. Even for users who understood the benefits of record keys, they had to put careful thought into their record key generation to ensure uniqueness and idempotency. The initial friction of generating keys was a barrier to adoption for teams who simply wanted to land their append-only workloads in a lakehouse with as few lines of code and configuration as possible.
Automatic Key Generation
With the release of version 0.14 (this is actually old news), Hudi has introduced automatic record key generation, a feature designed to simplify the user experience with append-only writes. This enhancement eliminates the mandatory requirement to specify record key fields for every write operation.
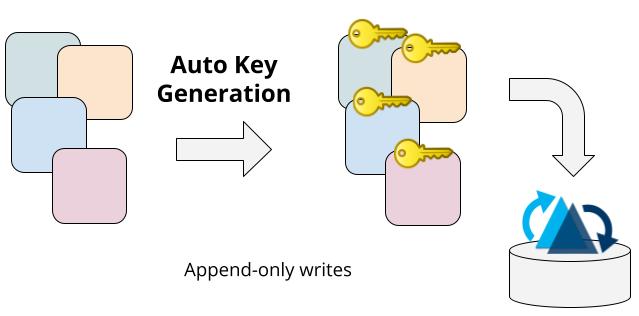
Now, to perform append-only writes, you can simply omit the primaryKey property in CREATE TABLE statements (see the example below) or skip setting the hoodie.datasource.write.recordkey.field or hoodie.table.recordkey.fields configurations.
CREATE TABLE hudi_table (
ts BIGINT,
uuid STRING,
rider STRING,
driver STRING,
fare DOUBLE,
city STRING
) USING HUDI
PARTITIONED BY (city);
In this example, you’re creating a Copy-on-Write table partitioned by city. Because the primaryKey property is not present, Hudi automatically detects the omission and engages the auto key generation feature.
Design Considerations
Designing a key generation mechanism that operates efficiently at petabyte scale requires careful thought. We established five core requirements for the auto-generated keys:
- Global Uniqueness: Keys must be unique across the entire table to maintain the integrity of a primary key.
- Low Storage Footprint: The keys should be highly compressible to add minimal storage overhead.
- Computational Efficiency: The encoding and decoding process must be lightweight so as not to slow down the write process.
- Idempotency: The generation process must be resilient to task retries, producing the same key for the same record every time.
- Engine Agnostic: The logic must be reusable and implemented consistently across different execution engines like Spark and Flink.
These principles guided the technical design. To align with primary key semantics, global uniqueness was non-negotiable. To minimize storage footprint, the generated keys needed to be compact and highly compressible, especially for tables with billions of records. The computational cost was also critical; any expensive operation would be amplified by the number of records, creating a significant performance overhead. Furthermore, in distributed systems where task failures and retries are common, the key generation process had to be idempotent—ensuring the same input record always produces the exact same key. Finally, the solution needed to be engine-agnostic to provide consistent behavior, whether data is written via Spark, Flink, or another supported engine.
Determining the Format
Based on the requirements mentioned previously, we eliminated several common ID generation techniques. For instance, we cannot use simple auto-incrementing IDs for each batch of writes, as it will not satisfy global uniqueness in the table across different writes. We also rule out using the monotonically_increasing_id function in Spark, as it does not guarantee global uniqueness either. Furthermore, using such functions violates the rule of being engine-agnostic. We do not use random ID generation such as UUID (v4, v6, and v7) and ULID, which do not satisfy the idempotency requirement. The final format that we chose is a deterministic, composite key with the following structure:
<write action start time>-<workload partition ID>-<record sequence ID>
Each component serves a specific purpose:
- Write Action Start Time: The timestamp from the Hudi timeline that marks the beginning of a write transaction.
- Workload Partition ID: An internal identifier that execution engines use to track the specific data split being processed by a given distributed write task.
- Record Sequence ID: A counter that uniquely identifies each record within that data split.
Together, these three components—all readily accessible during the write process—form a record identifier that satisfies the requirements of global uniqueness, idempotency, and being engine-agnostic.
Next, we evaluate the generated keys against the requirements of low storage footprint and computational efficiency. The following tables highlight some experiment numbers based on the RFC document of the auto key generation feature.
For storage efficiency, we compare the original strings with UUID v6/7, Base64, and ASCII encoding schemes:
| Format | Uncompressed size (bytes) | Compressed size (bytes) | Compression ratio |
|---|---|---|---|
| Original string | 4,000,185 | 244,373 | 11.1 |
| UUID v6/7 | 4,000,184 | 1,451,897 | 2.74 |
| Base64 | 2,400,184 | 202,095 | 11.9 |
| ASCII | 1,900,185 | 176,606 | 10.8 |
We also compare their compute efficiency using the original string format as the baseline:
| Format | Average runtime (ms) | Ratio to baseline |
|---|---|---|
| Original string | 0.00001 | 1 |
| UUID v6/7 | 0.0001 | 10 |
| Base64 | 0.004 | 400 |
| ASCII | 0.004 | 400 |
Based on the micro-benchmarking results, UUID v6/7 resulted in a much larger and undesired compressed size compared to others. Base64 and ASCII encoding had a lower storage footprint compared to the original string, with around 17% and 28% reduction respectively. However, both Base64 and ASCII require 400x more CPU power for encoding than the original string format. Given that write performance is often more critical than marginal storage savings in high-throughput data systems, we opted for the original string format for auto-generating record keys.
Summary
Hudi’s first-class support for record keys provides a database-like experience for lakehouses, enabling powerful features such as record-level indexing, merge modes, and CDC. The introduction of automatic record key generation thoughtfully extends the record key support, removing a barrier for teams performing append-only writes. By following the design principles of uniqueness, idempotency, and efficiency, the feature allows more users to easily adopt Hudi and benefit from its rich set of lakehouse capabilities without the initial overhead of manual key generation. This enhancement reinforces Hudi’s position as a versatile and user-friendly platform for building modern data lakehouses.