Accelerating Data Operations: Metica's Journey with Apache Hudi
This blog post summarizes Metica's presentation led by Subash Prabanantham at the Apache Hudi Community Sync. Watch the recording on YouTube.

Metica, a B2B SaaS startup building AI-driven personalization for the gaming industry, built its first lakehouse from scratch on Apache Hudi running on Amazon EMR. Hudi sits on the "gold" layer of a medallion architecture on AWS, with StarRocks (via CelerData) querying the data in place. The team grew their data from ~16 GB to billions of events without re-architecting — turning each scaling milestone into a configuration change rather than a migration. By enabling inline clustering with sort columns, they cut S3 object counts from ~17K to ~3K (a ~6x storage reduction) and roughly halved query latency on StarRocks (from ~200 ms to ~90 ms on a 40M-row table). This post covers their architecture, the access patterns that drove Hudi adoption, the feature timeline they followed as they scaled, the performance wins, and what's next.
Managing data platforms in a B2B SaaS startup requires a fine balance between long-term reliability and architectural flexibility. As data grows unpredictably alongside new client acquisitions, engineering teams often face the challenge of constantly refactoring their storage and compute tiers.
At a recent Apache Hudi Community Sync, Subash Prabanantham, a lead data engineer at Metica, shared how his team navigated these exact challenges. Spun out of an experienced team of ex-Apple and ex-King engineers, Metica personalizes gaming experiences via specialized ML techniques, helping studios maximize player lifetime value (LTV) and revenue.
Below is an in-depth breakdown of Metica's data platform architecture, their evolutionary journey using Apache Hudi, practical performance optimizations, and lessons learned along the way.
About Metica
Metica is a VC-backed B2B SaaS company (Play Ventures, Firstminute Capital) focused on personalizing every gaming experience. The team uses machine learning to deliver tailored offers, intelligent bundles, and contextual optimization, working together as an integrated suite that helps game developers and studios personalize for individual players — lifting player lifetime value, and with it, revenue.
Why a Lakehouse, and Why Hudi?
This was Metica's first lakehouse. Before it, the team worked primarily with plain Parquet and hand-built many of the features Hudi provides out of the box. When they designed a real data platform, they set four requirements:
- Open source and community-backed: Not a clever one-off project, but a format with an active community behind it.
- Scales with uneven data growth: As a startup, clients of wildly different sizes arrive on unpredictable timelines. The platform had to stay stable whether the next customer was small or enormous.
- Supports different query engines: Avoiding multiple copies of data was a hard requirement; they wanted a query engine that reads directly on top of the underlying lakehouse data.
- Low Maintenance: Offers easier maintenance across both the platform and the data format.
Apache Hudi was selected not just as a table format, but as a robust data platform that offered built-in table services, administrative tools like the Hudi CLI, and seamless ingestion utilities.
The Architecture: AWS + Apache Hudi
Metica implements a classic Medallion (Bronze/Silver/Gold) architecture entirely hosted on AWS. It decouples storage, compute, and cataloging to let each layer scale independently.
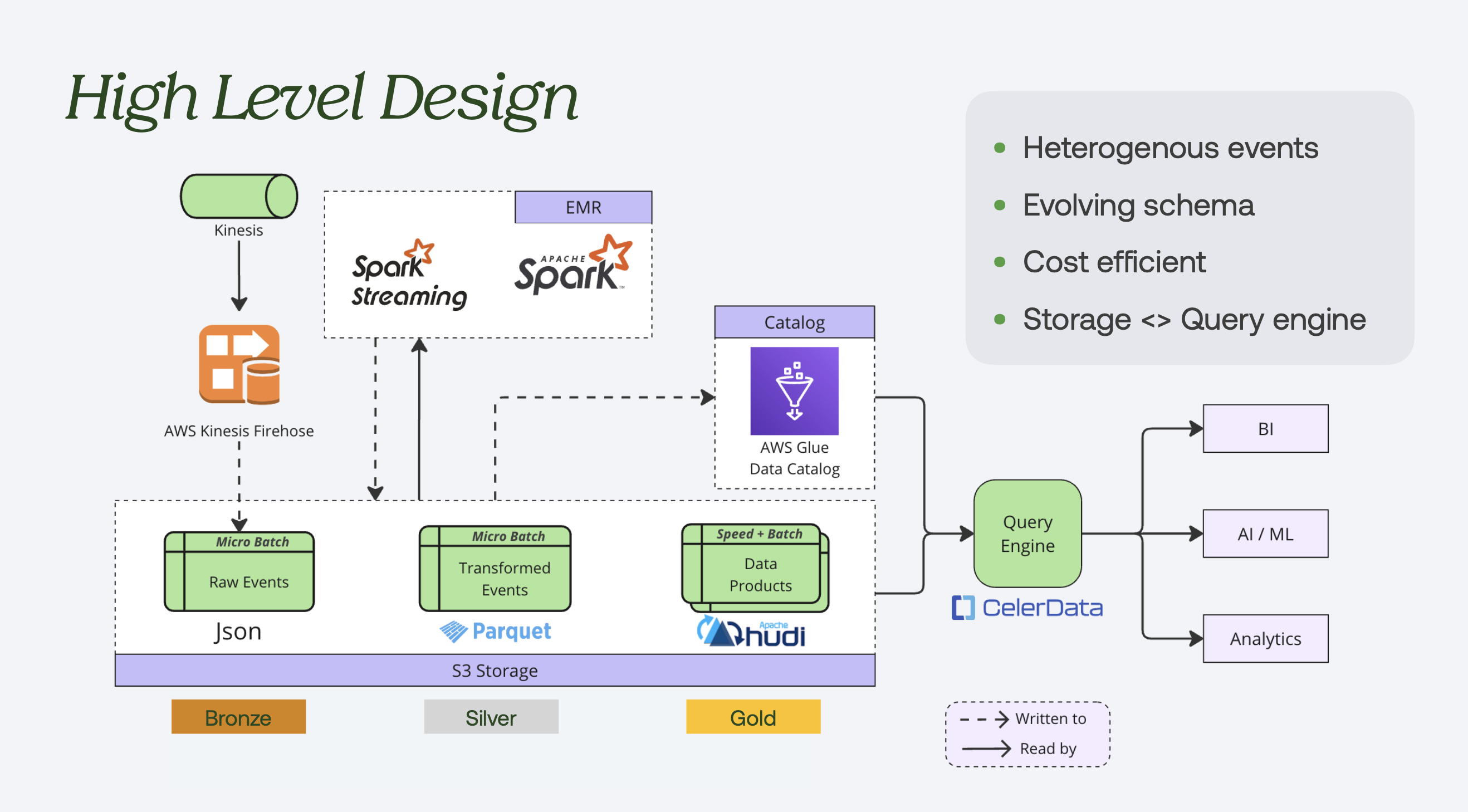
Metica's medallion architecture on AWS. Kinesis to raw JSON, Spark on EMR to Parquet, Apache Hudi for curated Gold tables, cataloged in Glue and served via CelerData.
- Ingestion & Bronze Layer: Real-time event streams are gathered via Amazon Kinesis and journaled directly into Amazon S3 as raw JSON objects.
- Processing (Silver): Spark and Spark Streaming on Amazon EMR apply minimal cleaning and transformation, writing transformed events to S3 as Parquet.
- Curated Layer (Gold): Data products and aggregates are written as Apache Hudi tables. This is where mutability, indexing, and table services earn their keep.
- Catalog & Query Engine: Metadata is maintained through the AWS Glue Data Catalog. For the consumption layer, Metica leverages CelerData (a managed solution for StarRocks) as its primary query engine to achieve sub-second query latencies without duplicating data into an isolated data warehouse and serves BI, AI/ML, and analytics consumers.
The most consequential decision sits at the query layer. In prior architectures the team had seen, a data lake fed a separate data warehouse (Snowflake, Teradata) — an extra hop, an extra copy, and a freshness lag between the two. Metica wanted to query lakehouse data in place, without copying it into a warehouse. After benchmarking, StarRocks delivered the sub-second latencies their reporting workloads needed while reading straight off Hudi tables.
One deliberate choice: bronze and silver aren't Hudi yet. The team kept the early layers as JSON and Parquet for flexibility, proving the table format out on the gold layer first. Ingestion is currently immutable (overwriting partitions) and there's no incremental processing in the pipeline. The plan is that when incremental processing arrives, flipping silver and bronze over to Hudi should be a configuration change — not an architectural migration.
The Use Case: Personalization Data and Access Patterns
Before adopting Hudi, the team mapped each top-level use case to the nature of its data and the operations performed on it. This framing drove where Hudi added value:

Each use case mapped to its data nature and operations, showing where Hudi's mutability, snapshot reads, and time travel fit.
Two of these illustrate why a table format was necessary. Experimentation data is fine-grained — user-level and event-level, sliced across many dimensions — producing huge, highly mutable tables with constant record-level deletes and updates. Ad-hoc analysis has a different problem: writers continuously append to a table while analysts and data scientists read from it simultaneously. With plain Parquet, a reader can hit files that change mid-read after a writer commits. The team had been working around this with bespoke partition-by-date patterns; Hudi gave them snapshot isolation out of the box, with no custom plumbing.
Growing Up with Hudi: A Feature Timeline
The most resonant part of the talk was a timeline showing how Metica adopted Hudi features incrementally as the company and the data grew, from ~16 GB in August 2023 to billions of events today. The point worth dwelling on: each step was a configuration change, not a structural rewrite.
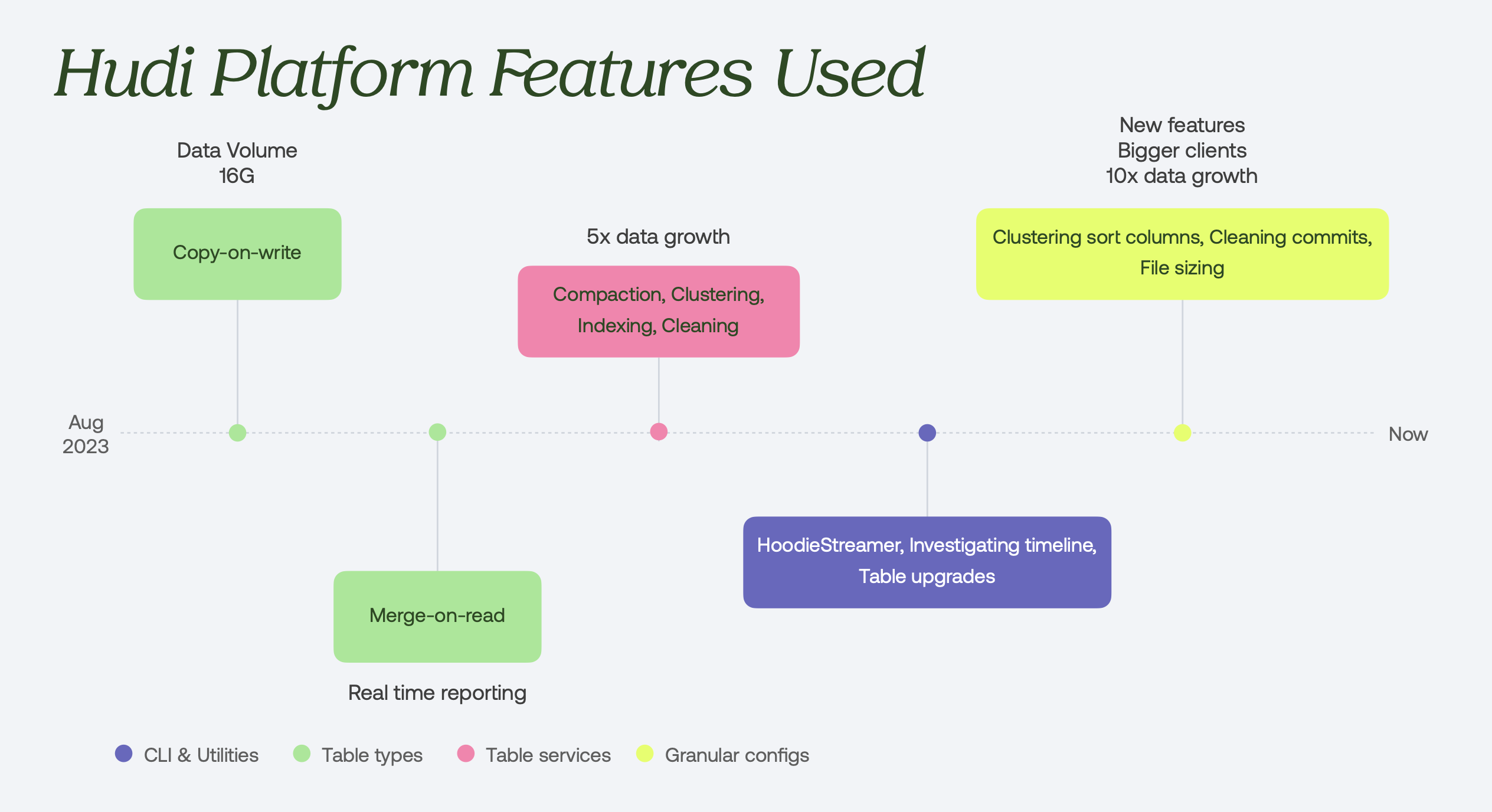
Metica's Hudi features adoption over time. Starting from Copy-on-Write and Merge-on-Read to table services, HoodieStreamer, and granular configs as data grew 10x.
- August 2023 (16GB Baseline): Initially started with standard Copy-on-Write (CoW) tables because data volumes were small and write performance wasn't a bottleneck.
- Real-time reporting: As real-time user reporting expanded, fine-grained updates began touching a high percentage of files. Re-writing entire Parquet files via CoW became expensive, leading Metica to migrate latency-sensitive pipelines to Merge-on-Read (MoR) tables.
- Managing 5x data growth: When mid-sized clients started sending millions of events, read latency suffered. Until this point the team had run on defaults — no clustering, indexing, or cleaning. Rather than overhauling the architecture, Metica stabilized performance simply by modifying Hudi cluster configurations to trigger automatic clustering, cleaning, and indexing.
- Seamless Version Upgrades: Wanting record-level indexes (introduced in 0.14), the team upgraded their EMR Hudi client from 0.13 to 0.14.1 — moving the internal table version from v5 to v6. They were nervous about existing tables, but Hudi handled the upgrade automatically on first write, with no config changes. The Hudi CLI became a valued admin tool for inspecting and reasoning about table state, and Hudi Streamer worked as expected where they used it.
- 10x data growth: Bigger clients and new features pushed data into the billions of events, reviving the read-latency challenge. The fix was optimizing data layout further: clustering with sort columns on predicate columns, cleaning commits to limit retained commits (some tables keep only the latest two), and file sizing to pack small files into larger ones.
Practical Scenarios & Performance Gains
This is where the real engineering lessons live. Here are before-and-after numbers from a real workload — a CelerData/StarRocks cluster of 1 frontend and 1 backend node, on a ~40M-row table.
1. Too Many Small Files
Without a table format manager, standard Apache Spark pipelines writing to raw Parquet require rigid repartition() or coalesce() configuration parameters. When data volumes are low, this practice forces a "small-file problem" across S3 objects.
Optimization applied: Enable inline clustering and let Hudi pack files adaptively to a target size.
hoodie.clustering.inline = true
Result: Total objects in S3 dropped from ~17K to ~3K — which is ~6x storage reduction.
2. Slow Reads on Wide File Scans
Because StarRocks prunes storage scans using parquet file-footers and file-level metadata, unsorted clustering still forced the engine to scan wide swaths of blocks.
Optimization applied: Add sort columns on the predicate columns so clustering co-locates the data that queries actually filter on.
hoodie.clustering.inline = true
hoodie.clustering.plan.strategy.sort.columns = col1,col2
Result: The same query with the same predicates went from ~200 ms to ~90 ms — a minimum ~2x improvement.
Key Challenges
Even with notable successes, Metica identified two production challenges:
- Column statistics on wide tables. Hudi enables column stats for all columns by default. On tables with very large column counts, that slowed down writes. The workaround is moving those services to async rather than inline. For now, the team is prioritizing record-level indexes over column stats, though they may combine the two later.
- Partition evolution. A known Hudi limitation — once partition columns are defined, changing them is awkward and involves real work. The lesson: be deliberate about choosing partition columns up front.
What's Next
The team is actively exploring several Hudi capabilities to push further:
- Record-level index (RLI): With more upsert-heavy workloads arriving, RLI's fast file lookup is the obvious next step; offline analysis showed it locates the right files very quickly.
- Apache XTable adoption: Apache XTable provides interoperability between table formats. Metica's angle is standardizing on a single read format: write whatever format fits a use case (say, Iceberg on ingestion) but translate it to Hudi so the query engine always reads Hudi tables — avoiding separate catalogs per format.
- StarRocks honoring RLI: Enabling an index in Hudi only helps if the query engine reads those statistics. StarRocks currently falls back to file-level indexing; Metica is working with both communities to close that gap so the benefit lands end-to-end.
- Async table services: Moving from inline to async management via Hudi's indexer, compactor, and clustering utilities, so the write pipeline can focus on producing gold tables while table maintenance runs in the background.
Conclusion
Adopting Apache Hudi paid off in a few concrete ways for Metica. The biggest win was being able to scale from ~16 GB to billions of events without ever re-architecting, since every jump in data volume became a configuration change instead of a painful migration. On the performance side, turning on inline clustering cut their S3 object count from ~17K to ~3K (about a 6x storage reduction), and adding sort columns on predicate columns roughly halved query latency on StarRocks, dropping it from ~200 ms to ~90 ms on a 40M-row table. Hudi removed a lot of manual work. Snapshot isolation let writers and readers hit the same tables safely without custom plumbing, and built-in table services, the Hudi CLI, and the indexer, compactor, and clustering utilities let a small team keep a growing platform healthy without building that machinery themselves.